Hyperparameter Transfer Laws for Non-Recurrent Multi-Path Neural Networks
作者: Shenxi Wu, Haosong Zhang, Xingjian Ma, Shirui Bian, Yichi Zhang, Xi Chen, Wei Lin
分类: cs.LG
发布日期: 2026-02-07
💡 一句话要点
提出基于图的有效深度概念,实现非循环多路径神经网络超参数的零样本迁移。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超参数迁移 深度缩放 有效深度 非循环神经网络 最大更新参数化
📋 核心要点
- 现代深度网络训练成本高,超参数调优耗时,因此需要研究超参数迁移方法。
- 论文提出基于图的有效深度概念,统一描述CNN、ResNet和Transformer等网络,并推导出学习率与有效深度的关系。
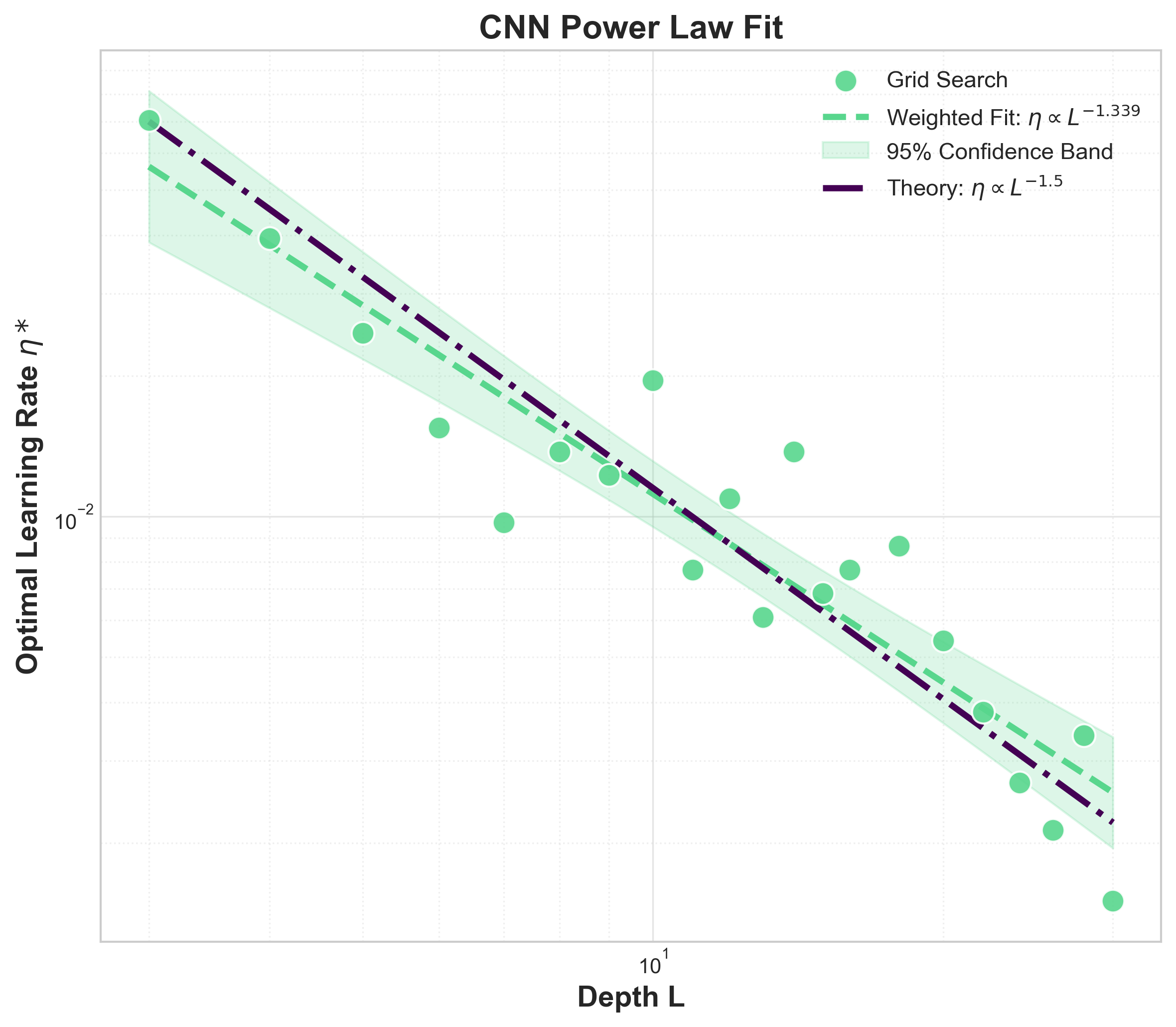
- 实验验证了学习率与有效深度之间的-3/2幂律关系,实现了跨深度和宽度的学习率零样本迁移。
📝 摘要(中文)
深度神经网络训练成本高昂,超参数迁移优于重复调优。最大更新参数化(μP)解释了超参数在宽度上的迁移性。但对于包含多条并行路径和残差聚合的现代架构,深度缩放的研究较少。为了统一CNN、ResNet和Transformer等非循环多路径神经网络,本文引入了基于图的有效深度概念。在稳定初始化和最大更新准则下,证明了最优学习率随有效深度衰减,遵循通用的-3/2幂律。最大更新准则旨在最大化初始化时典型的单步表示变化,同时避免不稳定。有效深度是输入到输出的最短路径长度,包括层和残差连接。在多种架构上的实验验证了预测的斜率,并实现了学习率在不同深度和宽度上的可靠零样本迁移,将深度缩放转化为可预测的超参数迁移问题。
🔬 方法详解
问题定义:现有深度神经网络,特别是包含多条并行路径和残差连接的现代架构,其深度缩放规律尚不明确。传统的超参数调优方法成本高昂,难以适应不断增长的网络规模。因此,需要一种有效的方法来实现超参数在不同深度和宽度网络之间的迁移,从而降低训练成本。现有方法在处理具有复杂拓扑结构的网络时,无法准确描述网络的深度,导致超参数迁移效果不佳。
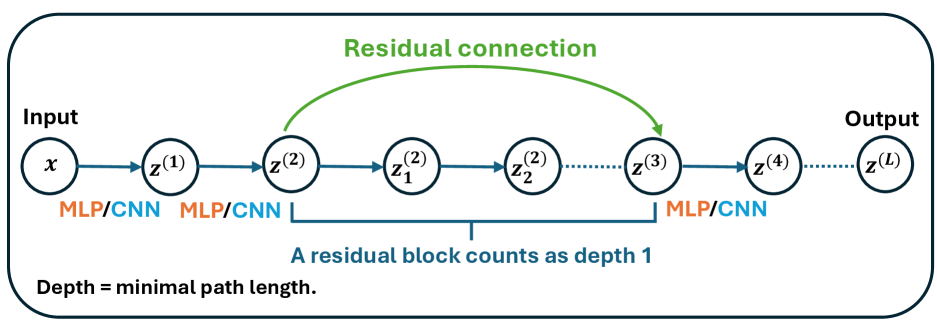
核心思路:论文的核心思路是引入“有效深度”的概念,将各种非循环多路径神经网络统一到一个框架下进行分析。有效深度被定义为输入到输出的最短路径长度,包括层和残差连接。通过分析网络在初始化时的表示变化,推导出最优学习率与有效深度之间的关系。这种方法旨在找到一个通用的规律,使得超参数能够从一个网络迁移到另一个网络,而无需进行额外的调优。
技术框架:论文的技术框架主要包括以下几个部分:1) 定义基于图的有效深度概念,用于描述网络的深度;2) 提出最大更新准则,用于确定初始化时的最优学习率;3) 推导最优学习率与有效深度之间的数学关系,即-3/2幂律;4) 通过实验验证理论推导的正确性,并评估超参数迁移的效果。整体流程是从理论分析到实验验证,最终实现超参数的零样本迁移。
关键创新:论文最重要的技术创新点在于提出了基于图的有效深度概念,并将其应用于分析非循环多路径神经网络的深度缩放规律。与传统的深度定义不同,有效深度考虑了网络中的并行路径和残差连接,能够更准确地描述网络的复杂拓扑结构。此外,论文还推导出了最优学习率与有效深度之间的通用关系,为超参数迁移提供了理论基础。
关键设计:论文的关键设计包括:1) 有效深度的计算方法,即输入到输出的最短路径长度,包括层和残差连接;2) 最大更新准则,用于最大化初始化时典型的单步表示变化,同时避免不稳定;3) 最优学习率的计算公式,即与有效深度的-3/2次方成正比;4) 实验中使用的多种网络架构,包括CNN、ResNet和Transformer等,以验证理论的通用性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,最优学习率与有效深度之间存在显著的-3/2幂律关系。在多种网络架构上,该方法实现了学习率的可靠零样本迁移,无需额外的超参数调优。例如,在ResNet-50上,使用从ResNet-18迁移的学习率,可以达到与手动调优相近的性能,同时节省了大量的计算资源。
🎯 应用场景
该研究成果可应用于各种深度学习模型的训练加速和优化。通过实现超参数的零样本迁移,可以显著降低训练成本,缩短模型开发周期。尤其是在资源受限的环境下,该方法具有重要的实际价值。未来,该研究可以进一步推广到更复杂的网络结构和任务中,例如图神经网络和强化学习。
📄 摘要(原文)
Deeper modern architectures are costly to train, making hyperparameter transfer preferable to expensive repeated tuning. Maximal Update Parametrization ($μ$P) helps explain why many hyperparameters transfer across width. Yet depth scaling is less understood for modern architectures, whose computation graphs contain multiple parallel paths and residual aggregation. To unify various non-recurrent multi-path neural networks such as CNNs, ResNets, and Transformers, we introduce a graph-based notion of effective depth. Under stabilizing initializations and a maximal-update criterion, we show that the optimal learning rate decays with effective depth following a universal -3/2 power law. Here, the maximal-update criterion maximizes the typical one-step representation change at initialization without causing instability, and effective depth is the minimal path length from input to output, counting layers and residual additions. Experiments across diverse architectures confirm the predicted slope and enable reliable zero-shot transfer of learning rates across depths and widths, turning depth scaling into a predictable hyperparameter-transfer problem.