On the Importance of a Multi-Scale Calibration for Quantization
作者: Seungwoo Son, Ingyu Seong, Junhan Kim, Hyemi Jang, Yongkweon Jeon
分类: cs.LG, cs.CL
发布日期: 2026-02-07
备注: ICASSP 2026
💡 一句话要点
提出MaCa:一种多尺度校准方法,提升LLM量化在变长输入下的精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后训练量化 大型语言模型 多尺度校准 Hessian矩阵 模型压缩
📋 核心要点
- 现有PTQ方法在LLM量化中依赖固定长度校准集,忽略了LLM输入长度可变的特性,导致量化性能下降。
- MaCa方法通过将多尺度序列长度信息融入Hessian估计,并正则化每个序列,从而构建更稳定的Hessian矩阵。
- 实验结果表明,MaCa在Qwen3、Gemma3、LLaMA3等模型上,显著提升了低比特量化精度,且易于集成。
📝 摘要(中文)
后训练量化(PTQ)是高效部署大型语言模型(LLM)的基石,其中小规模校准集对量化性能至关重要。然而,传统方法依赖于固定长度的随机序列,忽略了LLM输入的可变长度特性。输入长度直接影响激活分布,进而影响Hessian矩阵所捕获的权重重要性,最终影响量化结果。因此,从固定长度校准集导出的Hessian估计可能无法代表各种输入场景下权重的真实重要性。我们提出了MaCa(Matryoshka Calibration),一种简单而有效的长度感知Hessian构建方法。MaCa (i) 将多尺度序列长度信息纳入Hessian估计,并且 (ii) 将每个序列正则化为独立样本,从而产生更稳定和有效的Hessian,以实现准确的量化。在最先进的LLM(例如,Qwen3、Gemma3、LLaMA3)上的实验表明,MaCa在低比特量化下始终提高精度,提供了一种与现有PTQ框架兼容的轻量级增强。据我们所知,这是第一项系统地强调多尺度校准在LLM量化中的作用的工作。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)后训练量化(PTQ)中,由于校准集长度单一,无法准确估计权重重要性,导致量化精度下降的问题。现有方法通常使用固定长度的随机序列作为校准集,忽略了LLM输入长度的多样性,使得基于Hessian矩阵的权重重要性估计存在偏差。
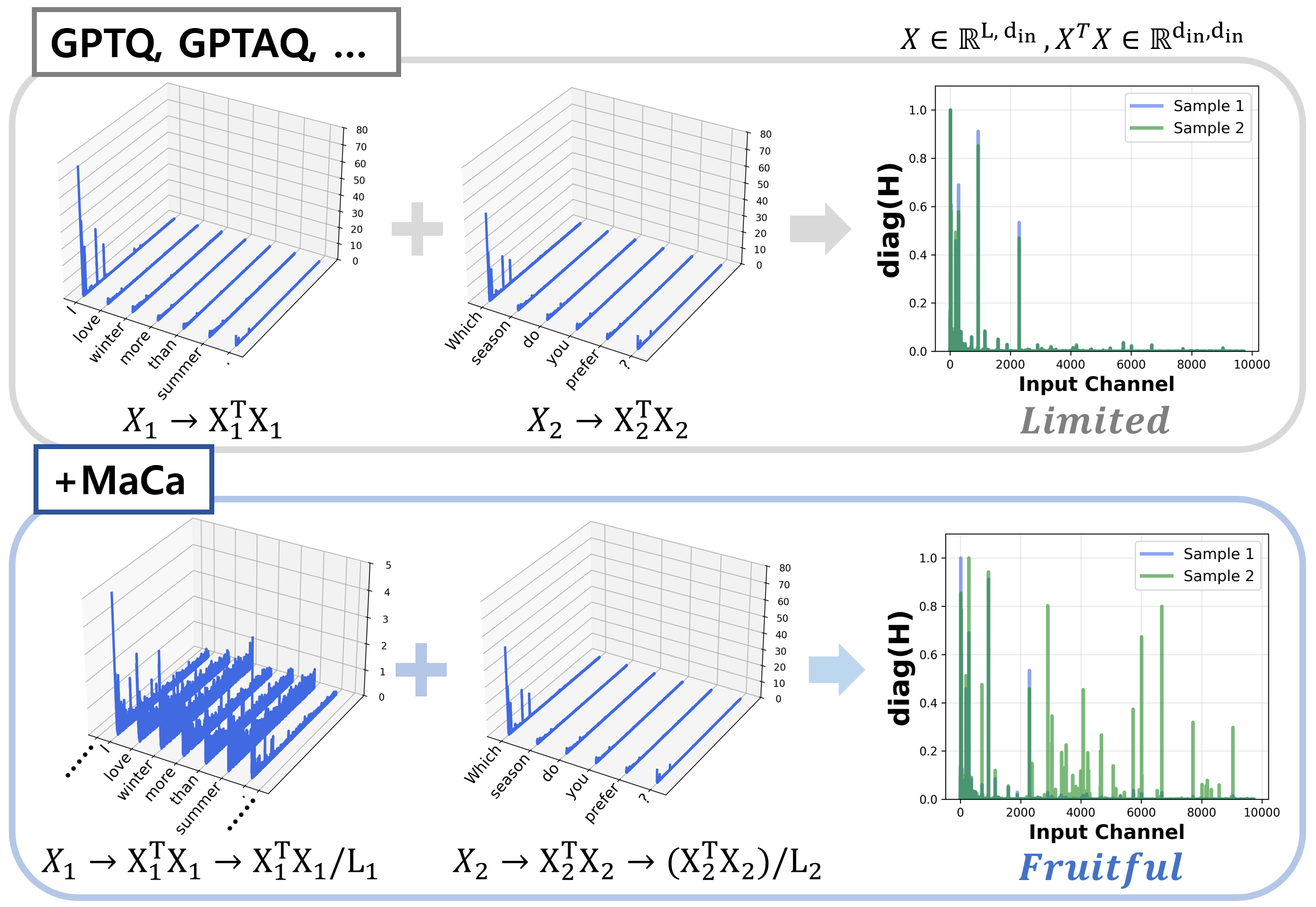
核心思路:论文的核心思路是提出一种多尺度校准方法(MaCa),通过在Hessian矩阵构建过程中,考虑不同长度的输入序列,从而更准确地捕捉权重在不同输入长度下的重要性。MaCa通过引入多尺度序列长度信息,并对每个序列进行正则化,来提高Hessian矩阵的稳定性和有效性,最终提升量化精度。
技术框架:MaCa方法主要包含两个关键步骤:(1) 多尺度Hessian估计:使用不同长度的输入序列计算Hessian矩阵,从而捕捉不同输入长度下的权重重要性。(2) 序列正则化:将每个输入序列视为独立的样本,通过正则化方法提高Hessian矩阵的稳定性。该方法可以与现有的PTQ框架无缝集成,作为一个预处理步骤,用于生成更准确的Hessian矩阵。
关键创新:论文的关键创新在于提出了多尺度校准的概念,并将其应用于Hessian矩阵的构建过程中。与现有方法只使用固定长度的输入序列不同,MaCa方法能够更好地适应LLM输入长度的多样性,从而更准确地估计权重的重要性。这是首次系统性地研究多尺度校准在LLM量化中的作用。
关键设计:MaCa的关键设计包括:(1) 多尺度序列长度的选择:需要根据具体的LLM和应用场景,选择合适的序列长度范围和采样策略。(2) Hessian矩阵的计算方法:可以使用不同的Hessian近似方法,例如Fisher信息矩阵或二阶梯度信息。(3) 序列正则化的方法:可以使用L1或L2正则化,或者其他更高级的正则化技术,以提高Hessian矩阵的稳定性。
🖼️ 关键图片
📊 实验亮点
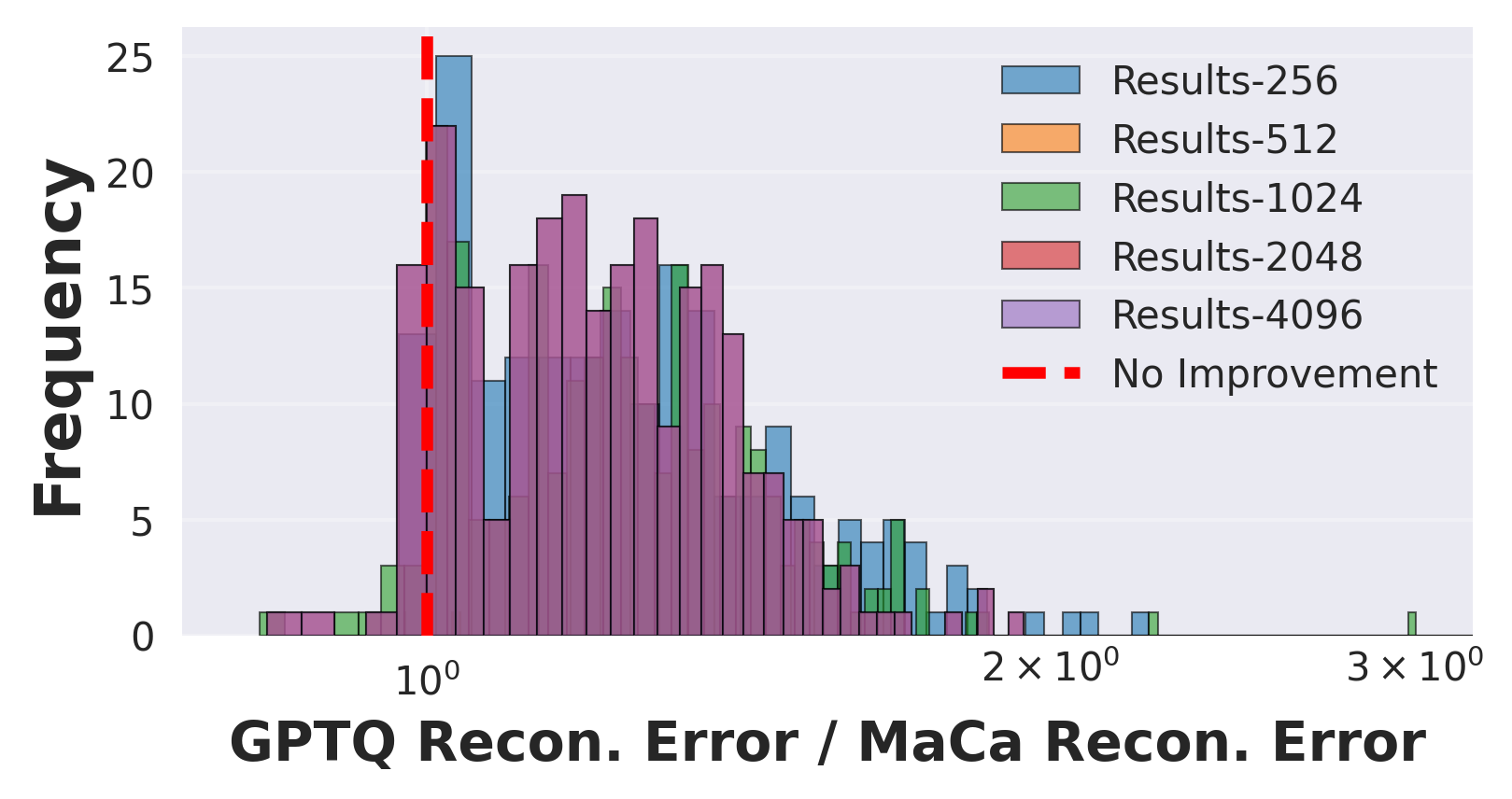
实验结果表明,MaCa方法在Qwen3、Gemma3和LLaMA3等先进LLM上,显著提升了低比特量化精度。例如,在某些模型和数据集上,MaCa能够将量化后的模型性能提升1-2个百分点,优于现有的PTQ方法。这些结果证明了MaCa方法在LLM量化中的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的压缩和加速,尤其是在资源受限的设备上部署LLM。通过提高量化精度,MaCa方法能够降低模型大小和计算复杂度,从而实现更高效的LLM推理。这对于移动设备、嵌入式系统和边缘计算等场景具有重要意义,有助于推动LLM在更广泛的应用领域落地。
📄 摘要(原文)
Post-training quantization (PTQ) is a cornerstone for efficiently deploying large language models (LLMs), where a small calibration set critically affects quantization performance. However, conventional practices rely on random sequences of fixed length, overlooking the variable-length nature of LLM inputs. Input length directly influences the activation distribution and, consequently, the weight importance captured by the Hessian, which in turn affects quantization outcomes. As a result, Hessian estimates derived from fixed-length calibration may fail to represent the true importance of weights across diverse input scenarios. We propose MaCa (Matryoshka Calibration), a simple yet effective method for length-aware Hessian construction. MaCa (i) incorporates multi-scale sequence length information into Hessian estimation and (ii) regularizes each sequence as an independent sample, yielding a more stable and fruitful Hessian for accurate quantization. Experiments on state-of-the-art LLMs (e.g., Qwen3, Gemma3, LLaMA3) demonstrate that MaCa consistently improves accuracy under low bit quantization, offering a lightweight enhancement compatible with existing PTQ frameworks. To the best of our knowledge, this is the first work to systematically highlight the role of multi-scale calibration in LLM quantization.