Data-Aware and Scalable Sensitivity Analysis for Decision Tree Ensembles
作者: Namrita Varshney, Ashutosh Gupta, Arhaan Ahmad, Tanay V. Tayal, S. Akshay
分类: cs.LG, stat.ML
发布日期: 2026-02-07
💡 一句话要点
提出数据感知的决策树集成敏感性分析框架,提升模型可靠性和公平性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 决策树集成 敏感性分析 数据感知 混合整数线性规划 可满足性模理论 模型鲁棒性 模型公平性
📋 核心要点
- 现有敏感性分析方法生成的敏感示例远离训练数据分布,导致结果缺乏实际意义和可解释性。
- 提出数据感知的敏感性分析框架,通过约束敏感示例接近训练数据,生成更真实、可解释的模型弱点证据。
- 结合MILP和SMT编码,加速敏感性验证,并在大型树集成模型上验证了框架的可扩展性和有效性。
📝 摘要(中文)
决策树集成模型被广泛应用于关键领域,因此其鲁棒性和敏感性分析至关重要。本文研究了特征敏感性问题,即判断一个集成模型是否对特定的特征子集(如受保护属性)敏感,这些特征的操纵可能会改变模型的预测结果。现有方法通常产生远离训练分布的敏感性示例,限制了其可解释性和实际价值。为此,我们提出了一个数据感知的敏感性分析框架,该框架约束敏感示例使其保持接近数据集,从而产生模型弱点的真实且可解释的证据。我们开发了使用混合整数线性规划(MILP)和可满足性模理论(SMT)编码进行数据感知搜索的新技术。我们的贡献包括:加强了敏感性验证的NP-hardness结果,证明即使对于深度为1的树也成立;开发了MILP优化,显著加速了单个集成模型以及多分类树集成模型的敏感性验证;引入了数据感知的框架,生成接近训练分布的真实示例;最后,我们对大型树集成模型进行了广泛的实验评估,证明了其可扩展性,能够处理多达800棵深度为8的树集成模型,并且相比现有技术取得了显著的改进。该框架为分析高风险应用中基于树的模型的可靠性和公平性提供了实践基础。
🔬 方法详解
问题定义:论文旨在解决决策树集成模型中特征敏感性分析的问题。现有方法生成的敏感性示例往往远离训练数据分布,导致分析结果缺乏实际意义,难以解释模型在实际应用中的弱点。因此,需要一种能够生成更贴近真实数据的敏感性示例的方法。
核心思路:论文的核心思路是通过引入数据感知的约束,限制生成的敏感性示例必须接近训练数据分布。这样可以确保分析结果更具代表性,更容易理解模型在实际场景中的行为,从而更好地评估模型的可靠性和公平性。
技术框架:该框架主要包含以下几个阶段:1) 问题建模:将特征敏感性分析问题形式化为优化问题,目标是找到能够改变模型预测结果的特征扰动;2) 数据感知约束:引入约束条件,确保生成的敏感性示例与训练数据之间的距离在一定范围内;3) 优化求解:利用MILP和SMT编码,求解带有数据感知约束的优化问题,找到满足条件的敏感性示例;4) 结果分析:分析生成的敏感性示例,识别模型对特定特征的敏感程度和潜在的弱点。
关键创新:论文的关键创新在于提出了数据感知的敏感性分析框架,将生成的敏感性示例限制在训练数据附近。与现有方法相比,该框架能够生成更真实、可解释的敏感性示例,从而更好地评估模型的可靠性和公平性。此外,论文还提出了MILP优化方法,加速了敏感性验证过程,使其能够处理更大规模的树集成模型。
关键设计:论文使用混合整数线性规划(MILP)和可满足性模理论(SMT)编码来表示和求解优化问题。数据感知约束通过定义距离度量(例如,L1距离或L2距离)来衡量敏感性示例与训练数据之间的接近程度。MILP优化方法通过减少搜索空间和利用线性规划的求解器来加速求解过程。具体的参数设置和损失函数选择取决于具体的数据集和模型。
🖼️ 关键图片


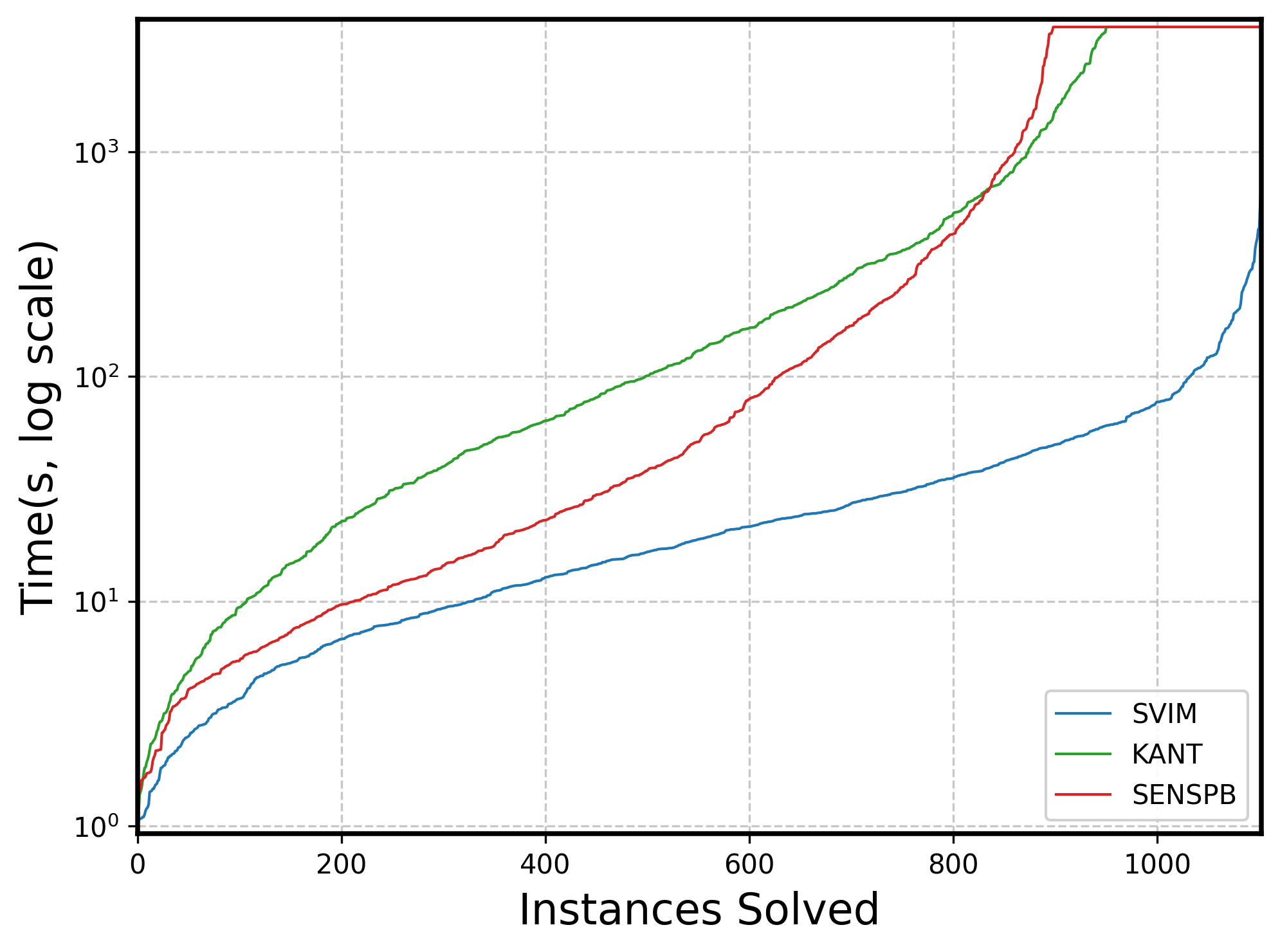
📊 实验亮点
实验结果表明,该框架能够处理高达800棵树、深度为8的集成模型,并在敏感性验证速度上显著优于现有技术。数据感知约束能够生成更接近训练数据的敏感性示例,提高了分析结果的实际意义。此外,论文还加强了敏感性验证的NP-hardness结果,为该领域的研究提供了理论基础。
🎯 应用场景
该研究成果可应用于金融、医疗、法律等高风险领域,用于评估决策树集成模型的可靠性和公平性。例如,可以分析模型是否对某些受保护属性(如性别、种族)过于敏感,从而避免歧视性决策。此外,该方法还可以用于识别模型的潜在弱点,提高模型的鲁棒性和安全性,增强用户对模型的信任。
📄 摘要(原文)
Decision tree ensembles are widely used in critical domains, making robustness and sensitivity analysis essential to their trustworthiness. We study the feature sensitivity problem, which asks whether an ensemble is sensitive to a specified subset of features -- such as protected attributes -- whose manipulation can alter model predictions. Existing approaches often yield examples of sensitivity that lie far from the training distribution, limiting their interpretability and practical value. We propose a data-aware sensitivity framework that constrains the sensitive examples to remain close to the dataset, thereby producing realistic and interpretable evidence of model weaknesses. To this end, we develop novel techniques for data-aware search using a combination of mixed-integer linear programming (MILP) and satisfiability modulo theories (SMT) encodings. Our contributions are fourfold. First, we strengthen the NP-hardness result for sensitivity verification, showing it holds even for trees of depth 1. Second, we develop MILP-optimizations that significantly speed up sensitivity verification for single ensembles and for the first time can also handle multiclass tree ensembles. Third, we introduce a data-aware framework generating realistic examples close to the training distribution. Finally, we conduct an extensive experimental evaluation on large tree ensembles, demonstrating scalability to ensembles with up to 800 trees of depth 8, achieving substantial improvements over the state of the art. This framework provides a practical foundation for analyzing the reliability and fairness of tree-based models in high-stakes applications.