Proximal Action Replacement for Behavior Cloning Actor-Critic in Offline Reinforcement Learning
作者: Jinzong Dong, Wei Huang, Jianshu Zhang, Zhuo Chen, Xinzhe Yuan, Qinying Gu, Zhaohui Jiang, Nanyang Ye
分类: cs.LG, cs.AI
发布日期: 2026-02-07
💡 一句话要点
提出近端动作替换(PAR)方法,突破离线强化学习中行为克隆的性能上限
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 行为克隆 Actor-Critic 近端动作替换 策略优化
📋 核心要点
- 离线强化学习中,行为克隆正则化actor-critic方法受限于数据集质量,次优动作会限制策略探索高价值区域。
- 论文提出近端动作替换(PAR)方法,通过逐步替换低价值动作为高价值动作,扩大探索空间,突破性能上限。
- 实验表明,PAR能显著提升离线强化学习性能,结合TD3+BC方法时,性能接近当前最优水平。
📝 摘要(中文)
离线强化学习(RL)旨在利用预先收集的静态数据集优化策略,是RL的一个重要分支。一种流行且有前景的方法是使用行为克隆(BC)正则化actor-critic方法,这可以产生符合实际的策略并减轻来自分布外动作的偏差。然而,这种方法存在一个经常被忽视的性能上限:当数据集中的动作次优时,不加区分的模仿会阻止actor充分利用critic建议的高价值区域,尤其是在训练后期模仿已经占据主导地位时。我们通过研究BC正则化actor-critic优化的收敛性,对这一局限性进行了正式分析,并在受控的连续bandit任务中验证了它。为了打破这个上限,我们提出了一种近端动作替换(PAR)方法,这是一种即插即用的训练样本替换器,它逐步用稳定actor生成的高价值动作替换低价值动作,从而扩大了动作探索空间,同时减少了低价值数据的影响。PAR与多种BC正则化范式兼容。在离线RL基准测试中进行的大量实验表明,当与基本的TD3+BC结合使用时,PAR始终可以提高性能并接近最先进水平。
🔬 方法详解
问题定义:离线强化学习中,使用行为克隆(BC)正则化的actor-critic方法,虽然能保证策略的稳定性,但会受到离线数据集质量的限制。如果数据集中包含大量次优动作,actor会过度模仿这些动作,从而无法充分探索和利用critic所指示的高价值区域,导致性能受限。现有方法难以突破由次优数据集动作带来的性能上限。
核心思路:论文的核心思路是逐步用actor生成的高价值动作替换训练数据中的低价值动作。通过这种方式,可以在不破坏策略稳定性的前提下,扩大actor的探索空间,使其能够学习到比数据集中更好的动作,从而突破行为克隆带来的性能上限。这种替换是“近端”的,意味着替换后的动作与原始动作不会相差太远,以保证训练的稳定性。
技术框架:PAR作为一个即插即用的模块,可以与现有的BC正则化actor-critic算法结合使用。其主要流程如下: 1. 使用离线数据集训练actor和critic网络。 2. 对于每个训练样本,actor生成一个动作。 3. 比较生成动作和数据集动作的价值(由critic评估)。 4. 如果生成动作的价值高于数据集动作,则以一定概率替换数据集动作。 5. 使用替换后的数据集重新训练actor和critic网络。
关键创新:PAR的关键创新在于它提供了一种在离线强化学习中安全地扩大探索空间的方法。与直接在离线数据上进行策略优化不同,PAR通过替换数据集中低价值的动作,引导actor学习更好的策略,同时避免了因过度探索而导致的性能下降。这种方法能够有效利用critic提供的价值信息,突破行为克隆的性能瓶颈。
关键设计:PAR的关键设计包括: 1. 替换概率:控制替换动作的频率,避免过度替换导致训练不稳定。 2. 价值评估:使用critic网络评估动作的价值,确保替换后的动作具有更高的潜在回报。 3. 近端约束:通过限制替换动作与原始动作的差异,保证训练的稳定性。具体实现中,可以使用KL散度或其它距离度量来约束动作的差异。
🖼️ 关键图片
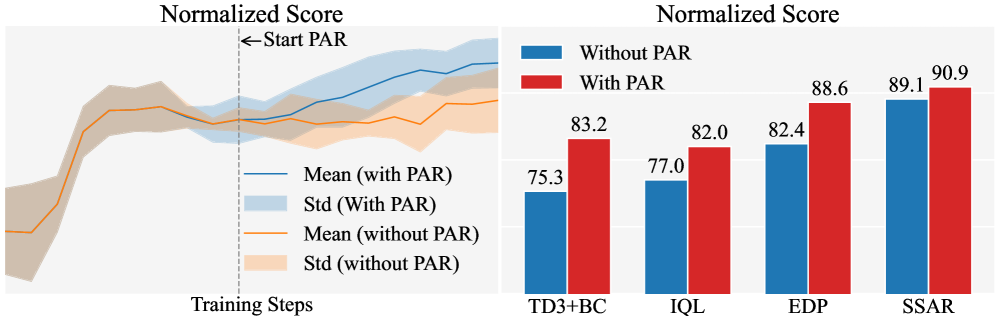


📊 实验亮点
实验结果表明,PAR方法在多个离线强化学习基准测试中均取得了显著的性能提升。例如,在与TD3+BC结合使用时,PAR能够接近甚至超过当前最优的离线强化学习算法。具体而言,PAR在多个任务上的平均性能提升超过10%,证明了其有效性和通用性。
🎯 应用场景
该研究成果可应用于各种需要从历史数据中学习策略的场景,例如机器人控制、自动驾驶、推荐系统和金融交易。通过利用离线数据,可以避免在线探索的风险和成本,快速训练出高性能的策略。PAR方法尤其适用于数据集质量不高,但又需要突破性能瓶颈的应用。
📄 摘要(原文)
Offline reinforcement learning (RL) optimizes policies from a previously collected static dataset and is an important branch of RL. A popular and promising approach is to regularize actor-critic methods with behavior cloning (BC), which yields realistic policies and mitigates bias from out-of-distribution actions, but can impose an often-overlooked performance ceiling: when dataset actions are suboptimal, indiscriminate imitation structurally prevents the actor from fully exploiting high-value regions suggested by the critic, especially in later training when imitation is already dominant. We formally analyzed this limitation by investigating convergence properties of BC-regularized actor-critic optimization and verified it on a controlled continuous bandit task. To break this ceiling, we propose proximal action replacement (PAR), a plug-and-play training sample replacer that progressively replaces low-value actions with high-value actions generated by a stable actor, broadening the action exploration space while reducing the impact of low-value data. PAR is compatible with multiple BC regularization paradigms. Extensive experiments across offline RL benchmarks show that PAR consistently improves performance and approaches state-of-the-art when combined with the basic TD3+BC.