Sign-Based Optimizers Are Effective Under Heavy-Tailed Noise
作者: Dingzhi Yu, Hongyi Tao, Yuanyu Wan, Luo Luo, Lijun Zhang
分类: cs.LG, cs.CL, math.OC
发布日期: 2026-02-07
备注: Code available at https://github.com/Dingzhen230/Heavy-tailed-Noise-in-LLMs
💡 一句话要点
SignSGD优化器在重尾噪声下表现优异,为大模型训练提供理论支撑
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 重尾噪声 SignSGD 大型语言模型 优化算法 收敛性分析
📋 核心要点
- 现有自适应梯度方法在训练LLM时面临重尾梯度噪声的挑战,导致性能下降。
- 论文提出在广义重尾噪声条件下,SignSGD等基于符号的优化器具有更优的收敛性。
- 实验验证了提出的噪声模型与LLM训练实践相符,并支持了SignSGD优化器的有效性。
📝 摘要(中文)
自适应梯度方法是现代机器学习的常用工具,但基于符号的优化算法(如Lion和Muon)最近在训练大型语言模型(LLM)时表现出优于AdamW的经验性能。然而,对于基于符号的更新优于方差自适应方法的理论理解仍然难以捉摸。本文旨在通过重尾梯度噪声的视角来弥合理论与实践之间的差距,这种现象在语言建模任务中经常观察到。理论上,我们引入了一种新的广义重尾噪声条件,比标准的有限方差假设更准确地捕捉了LLM的行为。在这种噪声模型下,我们为广义平滑函数类建立了SignSGD和Lion的清晰收敛速度,匹配或超过了先前已知的最佳边界。此外,我们将分析扩展到Muon和Muonlight,提供了我们所知第一个在重尾随机性下进行矩阵优化的严格分析。这些结果为基于符号的优化器的经验优势提供了强有力的理论依据,表明它们自然适合处理与重尾相关的噪声梯度。经验上,LLM预训练实验验证了我们的理论见解,并证实了我们提出的噪声模型与实践非常吻合。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)训练中,由于梯度噪声呈现重尾分布,导致传统自适应梯度优化器(如AdamW)性能下降的问题。现有的理论分析通常基于有限方差的噪声假设,无法准确描述LLM训练中出现的重尾噪声现象,因此缺乏对基于符号的优化器(如Lion, Muon)有效性的理论解释。
核心思路:论文的核心思路是引入一种新的广义重尾噪声条件,该条件能够更准确地捕捉LLM训练中梯度噪声的特性。在此基础上,论文证明了基于符号的优化器(SignSGD, Lion, Muon)在这种重尾噪声下具有更好的收敛性。这种设计思路的出发点在于,基于符号的优化器对梯度幅值不敏感,因此能够更好地抵抗重尾噪声的影响。
技术框架:论文的整体框架包括以下几个部分:1) 提出广义重尾噪声模型;2) 分析SignSGD和Lion在广义平滑函数类下的收敛速度;3) 将分析扩展到矩阵优化算法Muon和Muonlight;4) 通过LLM预训练实验验证理论结果。主要模块包括噪声模型定义、收敛性分析和实验验证。
关键创新:论文最重要的技术创新在于:1) 提出了一个更符合LLM训练实际情况的广义重尾噪声模型;2) 首次对Muon和Muonlight等矩阵优化算法在重尾噪声下的收敛性进行了严格分析;3) 证明了基于符号的优化器在重尾噪声下具有优于自适应梯度优化器的理论性能。与现有方法的本质区别在于,论文的分析不再局限于有限方差的噪声假设,而是考虑了更一般的重尾噪声情况。
关键设计:论文的关键设计包括:1) 广义重尾噪声模型的具体形式,需要仔细选择合适的参数以捕捉LLM训练中的噪声特性;2) 收敛性分析中使用的广义平滑函数类,需要保证其能够覆盖LLM训练中常见的损失函数;3) 实验验证中使用的LLM模型和数据集,需要具有代表性,能够反映实际应用中的情况。
🖼️ 关键图片
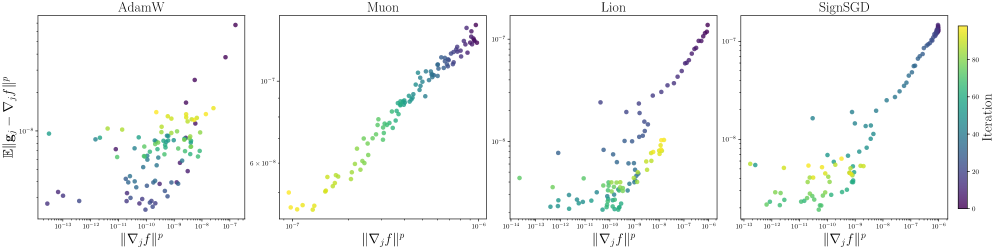

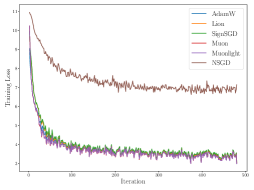
📊 实验亮点
论文通过LLM预训练实验验证了理论分析的正确性。实验结果表明,在重尾噪声条件下,SignSGD和Lion等基于符号的优化器能够达到与AdamW相当甚至更好的性能。此外,论文还首次对Muon和Muonlight在重尾噪声下的收敛性进行了分析,为矩阵优化算法的应用提供了理论支撑。
🎯 应用场景
该研究成果可应用于大型语言模型的预训练和微调,以及其他深度学习任务中存在重尾梯度噪声的场景。通过使用基于符号的优化器,可以提高模型的训练效率和最终性能。该研究为优化器选择提供了理论指导,有助于推动人工智能领域的发展。
📄 摘要(原文)
While adaptive gradient methods are the workhorse of modern machine learning, sign-based optimization algorithms such as Lion and Muon have recently demonstrated superior empirical performance over AdamW in training large language models (LLM). However, a theoretical understanding of why sign-based updates outperform variance-adapted methods remains elusive. In this paper, we aim to bridge the gap between theory and practice through the lens of heavy-tailed gradient noise, a phenomenon frequently observed in language modeling tasks. Theoretically, we introduce a novel generalized heavy-tailed noise condition that captures the behavior of LLMs more accurately than standard finite variance assumptions. Under this noise model, we establish sharp convergence rates of SignSGD and Lion for generalized smooth function classes, matching or surpassing previous best-known bounds. Furthermore, we extend our analysis to Muon and Muonlight, providing what is, to our knowledge, the first rigorous analysis of matrix optimization under heavy-tailed stochasticity. These results offer a strong theoretical justification for the empirical superiority of sign-based optimizers, showcasing that they are naturally suited to handle the noisy gradients associated with heavy tails. Empirically, LLM pretraining experiments validate our theoretical insights and confirm that our proposed noise models are well-aligned with practice.