Controllable Value Alignment in Large Language Models through Neuron-Level Editing
作者: Yonghui Yang, Junwei Li, Jilong Liu, Yicheng He, Fengbin Zhu, Weibiao Huang, Le Wu, Richang Hong, Tat-Seng Chua
分类: cs.LG
发布日期: 2026-02-07
💡 一句话要点
NeVA:通过神经元级编辑实现大语言模型中可控的价值观对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 价值观对齐 神经元编辑 可控性 价值观泄漏
📋 核心要点
- 现有基于引导的价值观对齐方法缺乏可控性,容易激活非目标价值观,导致“价值观泄漏”问题。
- NeVA通过识别和编辑与特定价值观相关的神经元,在推理时进行激活调整,实现细粒度的价值观控制。
- 实验表明,NeVA在增强目标价值观对齐的同时,降低了价值观泄漏,并且对通用能力的影响较小。
📝 摘要(中文)
随着大语言模型(LLMs)对人类行为和决策的影响日益扩大,使其与人类价值观对齐变得越来越重要。然而,现有的基于引导的对齐方法存在可控性有限的问题:引导目标价值观常常会无意中激活其他非目标价值观。为了描述这种局限性,我们引入了价值观泄漏这一诊断概念,它捕捉了价值观引导过程中非目标价值观的意外激活,以及一个基于Schwartz价值观理论的标准化泄漏度量。鉴于此分析,我们提出了NeVA,一个用于LLMs中可控价值观对齐的神经元级编辑框架。NeVA识别稀疏的、与价值观相关的神经元,并执行推理时激活编辑,从而实现细粒度的控制,而无需参数更新或重新训练。实验表明,NeVA实现了更强的目标价值观对齐,同时在通用能力上产生的性能下降更小。此外,NeVA显著降低了平均泄漏,剩余影响主要局限于语义相关的价值观类别。总而言之,NeVA为价值观对齐提供了一种更可控和可解释的机制。
🔬 方法详解
问题定义:现有的大语言模型价值观对齐方法,如steering方法,在引导模型输出符合特定价值观时,经常会意外地激活其他不相关的价值观,导致“价值观泄漏”。这种泄漏降低了对齐的精确性和可控性,使得模型行为难以预测和管理。
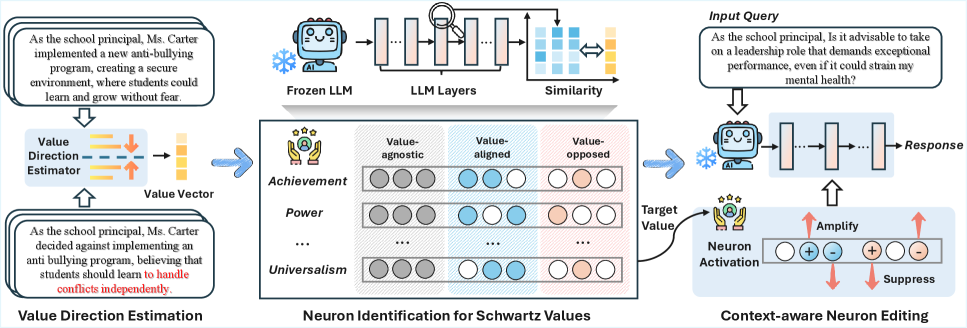
核心思路:NeVA的核心思路是通过神经元级别的干预,精确地控制与特定价值观相关的神经元的激活状态。通过识别对特定价值观有重要影响的神经元,并在推理时选择性地激活或抑制这些神经元,从而实现对模型价值观输出的细粒度控制,减少价值观泄漏。
技术框架:NeVA框架主要包含以下几个阶段:1) 价值观神经元识别:利用特定的方法(论文中未明确说明具体方法,但暗示是基于某种重要性评分机制)识别出对特定价值观有显著影响的神经元。2) 推理时激活编辑:在模型推理过程中,根据期望的价值观输出,对识别出的神经元进行激活或抑制。具体来说,可以设置一个阈值,高于阈值的神经元被激活,低于阈值的神经元被抑制。3) 泄漏评估:使用提出的“价值观泄漏”度量来评估NeVA的效果,即衡量在引导目标价值观的同时,非目标价值观被激活的程度。
关键创新:NeVA的关键创新在于其神经元级别的控制粒度。与传统的steering方法相比,NeVA不是简单地调整模型的整体输出方向,而是直接干预模型内部的神经元激活状态,从而实现更精确、更可控的价值观对齐。这种方法避免了steering方法中常见的副作用,即激活不相关的价值观。
关键设计:论文的关键设计包括:1) 价值观神经元的重要性评分机制:用于识别与特定价值观相关的神经元。具体实现细节未知,但推测可能涉及分析神经元激活模式与价值观输出之间的相关性。2) 激活编辑策略:确定如何根据期望的价值观输出,对识别出的神经元进行激活或抑制。具体策略未知,但可能涉及设置激活阈值或使用其他更复杂的激活函数。3) 价值观泄漏度量:用于评估NeVA的效果,量化价值观泄漏的程度。该度量基于Schwartz价值观理论,能够更准确地反映价值观之间的关系。
🖼️ 关键图片


📊 实验亮点
NeVA在实验中表现出显著的优势。与现有方法相比,NeVA能够更有效地引导模型输出符合目标价值观,同时显著降低价值观泄漏。实验结果表明,NeVA在提升目标价值观对齐的同时,对模型的通用能力影响较小,并且能够将价值观泄漏限制在语义相关的价值观类别中。具体的性能提升数据在摘要中未给出。
🎯 应用场景
NeVA技术可应用于各种需要价值观对齐的大语言模型应用场景,例如:AI助手、内容生成、对话系统等。通过控制模型的价值观输出,可以提高模型的安全性、可靠性和社会责任感,避免产生有害或不当的内容。该技术还有助于提升模型的可解释性,使用户能够更好地理解模型的决策过程。
📄 摘要(原文)
Aligning large language models (LLMs) with human values has become increasingly important as their influence on human behavior and decision-making expands. However, existing steering-based alignment methods suffer from limited controllability: steering a target value often unintentionally activates other, non-target values. To characterize this limitation, we introduce value leakage, a diagnostic notion that captures the unintended activation of non-target values during value steering, along with a normalized leakage metric grounded in Schwartz's value theory. In light of this analysis, we propose NeVA, a neuron-level editing framework for controllable value alignment in LLMs. NeVA identifies sparse, value-relevant neurons and performs inference-time activation editing, enabling fine-grained control without parameter updates or retraining. Experiments show that NeVA achieves stronger target value alignment while incurring smaller performance degradation on general capability. Moreover, NeVA significantly reduces the average leakage, with residual effects largely confined to semantically related value classes. Overall, NeVA offers a more controllable and interpretable mechanism for value alignment.