Scalable Dexterous Robot Learning with AR-based Remote Human-Robot Interactions
作者: Yicheng Yang, Ruijiao Li, Lifeng Wang, Shuai Zheng, Shunzheng Ma, Keyu Zhang, Tuoyu Sun, Chenyun Dai, Jie Ding, Zhuo Zou
分类: cs.LG, cs.RO
发布日期: 2026-02-07
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于AR远程人机交互的可扩展灵巧机器人学习框架,提升操作任务效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧机器人 强化学习 对比学习 增强现实 人机交互 远程操作 行为克隆
📋 核心要点
- 现有灵巧机器人操作学习方法效率低,难以扩展,需要大量人工干预和专家知识。
- 论文提出基于AR的远程人机交互系统,收集专家数据,并结合对比学习强化学习提升策略。
- 实验表明,该方法显著提升了操作任务的成功率,并加快了推理速度,克服了策略崩溃问题。
📝 摘要(中文)
本文关注灵巧机器人臂手系统中可扩展的机器人操作学习,通过基于增强现实(AR)的远程人机交互来收集专家演示数据,从而提高效率。论文提出了一个统一的框架来解决通用操作任务问题。具体而言,该方法包括两个阶段:i) 在预训练的第一阶段,通过利用来自基于AR的远程人机交互系统的学习数据,以行为克隆(BC)的方式创建策略;ii) 在第二阶段,开发了一种对比学习增强的强化学习(RL)方法,以获得比BC更有效和鲁棒的策略,并设计了一个投影头来加速学习过程。采用事件驱动的增强奖励来提高安全性。通过PyBullet进行的物理模拟和真实世界的实验验证了所提出的方法。结果表明,与经典的近端策略优化和软演员-评论家策略相比,该方法不仅显著加快了推理速度,而且在完成操作任务的成功率方面也取得了更好的性能。通过消融研究证实,所提出的带有对比学习的强化学习克服了策略崩溃。
🔬 方法详解
问题定义:论文旨在解决灵巧机器人臂手系统中的操作任务学习问题。现有方法通常依赖于大量的真实世界数据或复杂的奖励函数设计,导致学习效率低下且难以泛化。此外,策略崩溃是强化学习中常见的问题,尤其是在复杂的机器人操作任务中,现有的强化学习方法难以有效避免。
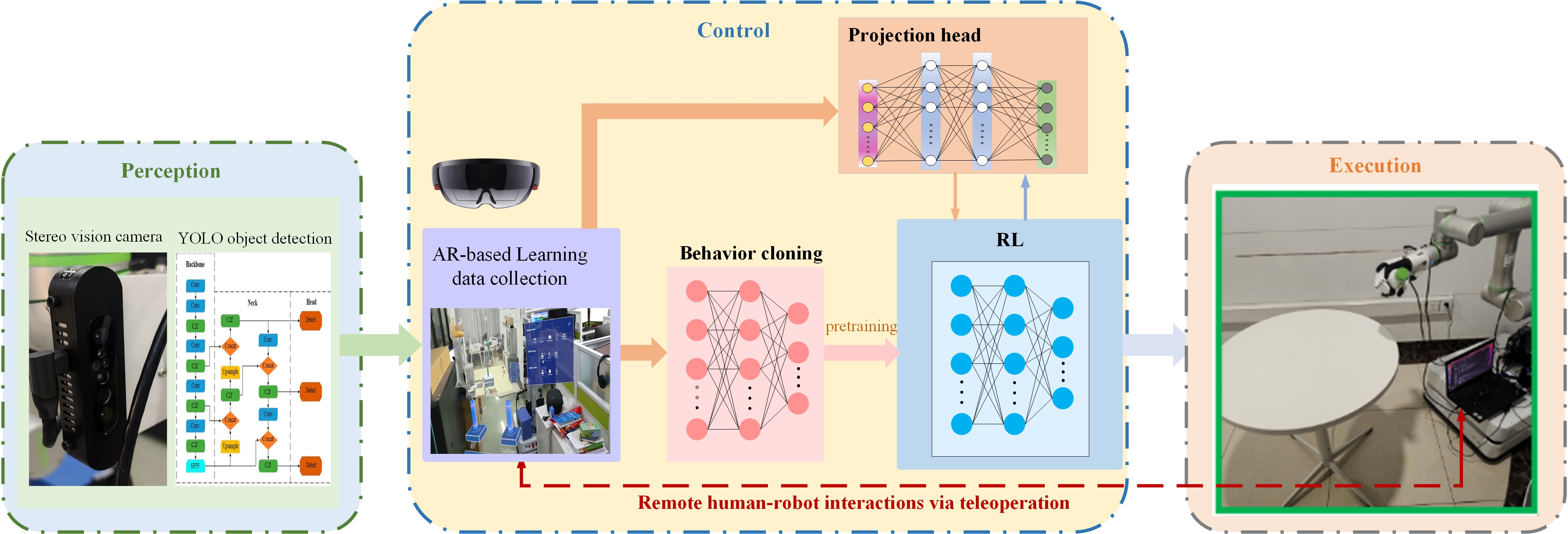
核心思路:论文的核心思路是利用AR技术实现远程人机交互,从而高效地收集专家演示数据。然后,利用这些数据进行预训练,并结合对比学习增强的强化学习方法,进一步提升策略的鲁棒性和泛化能力。通过对比学习,鼓励策略学习到更具区分性的特征表示,从而避免策略崩溃。
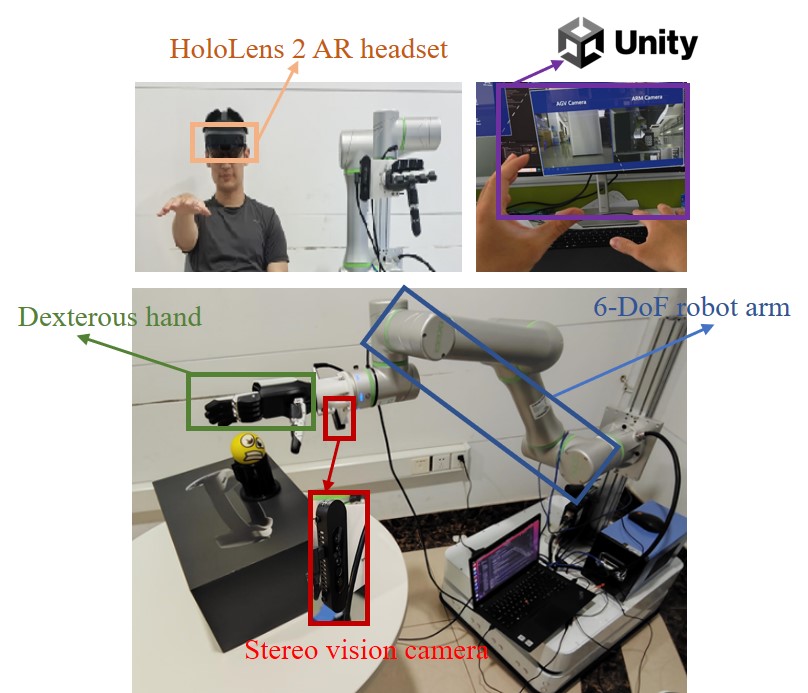
技术框架:该方法包含两个主要阶段:1) 基于AR远程人机交互的预训练阶段:通过AR界面,人类专家远程控制机器人执行操作任务,收集轨迹数据。利用这些数据,通过行为克隆(BC)训练初始策略。2) 对比学习增强的强化学习阶段:在预训练策略的基础上,使用强化学习算法(例如PPO或SAC)进行微调。同时,引入对比学习,鼓励策略学习到更鲁棒的特征表示。此外,采用事件驱动的增强奖励来提高安全性。
关键创新:该论文的关键创新在于将AR远程人机交互与对比学习增强的强化学习相结合。AR远程人机交互能够高效地收集高质量的专家数据,而对比学习能够提升策略的鲁棒性和泛化能力,从而克服策略崩溃问题。此外,事件驱动的增强奖励进一步提高了安全性。
关键设计:在对比学习中,设计了一个投影头,用于将状态表示映射到对比学习空间。对比损失函数的目标是拉近相似状态的表示,推远不相似状态的表示。事件驱动的增强奖励根据机器人的状态和环境的变化动态调整奖励,例如,当机器人即将发生碰撞时,给予负奖励。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与传统的PPO和SAC算法相比,该方法在操作任务的成功率方面取得了显著提升,并加快了推理速度。消融实验证明,对比学习能够有效克服策略崩溃问题。在真实世界实验中,该方法也表现出良好的性能,验证了其在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于各种需要灵巧操作的场景,例如:远程医疗、精密制造、危险环境下的操作任务等。通过AR远程交互,专家可以远程指导机器人完成复杂的操作,降低人工成本和风险。该方法还可用于训练更智能、更安全的机器人,从而提高生产效率和安全性。
📄 摘要(原文)
This paper focuses on the scalable robot learning for manipulation in the dexterous robot arm-hand systems, where the remote human-robot interactions via augmented reality (AR) are established to collect the expert demonstration data for improving efficiency. In such a system, we present a unified framework to address the general manipulation task problem. Specifically, the proposed method consists of two phases: i) In the first phase for pretraining, the policy is created in a behavior cloning (BC) manner, through leveraging the learning data from our AR-based remote human-robot interaction system; ii) In the second phase, a contrastive learning empowered reinforcement learning (RL) method is developed to obtain more efficient and robust policy than the BC, and thus a projection head is designed to accelerate the learning progress. An event-driven augmented reward is adopted for enhancing the safety. To validate the proposed method, both the physics simulations via PyBullet and real-world experiments are carried out. The results demonstrate that compared to the classic proximal policy optimization and soft actor-critic policies, our method not only significantly speeds up the inference, but also achieves much better performance in terms of the success rate for fulfilling the manipulation tasks. By conducting the ablation study, it is confirmed that the proposed RL with contrastive learning overcomes policy collapse. Supplementary demonstrations are available at https://cyberyyc.github.io/.