Revisiting Robustness for LLM Safety Alignment via Selective Geometry Control
作者: Yonghui Yang, Wenjian Tao, Jilong Liu, Xingyu Zhu, Junfeng Fang, Weibiao Huang, Le Wu, Richang Hong, Tat-Sent Chua
分类: cs.LG
发布日期: 2026-02-07
💡 一句话要点
ShaPO:通过选择性几何控制提升LLM安全对齐的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM安全对齐 鲁棒性优化 偏好优化 几何控制 噪声监督
📋 核心要点
- 现有LLM安全对齐方法在领域迁移和噪声偏好监督下鲁棒性不足,主要原因是忽略了优化过程本身的脆弱性。
- ShaPO通过选择性几何控制,在对齐关键参数子空间上强制执行最坏情况对齐目标,避免过度正则化,从而提升鲁棒性。
- 实验表明,ShaPO在多种安全基准和噪声偏好设置下,显著提升了安全鲁棒性,且能与数据鲁棒目标有效结合。
📝 摘要(中文)
大型语言模型的安全对齐在领域迁移和噪声偏好监督下仍然脆弱。现有鲁棒对齐方法大多关注对齐数据中的不确定性,而忽略了基于偏好的目标函数中优化引起的脆弱性。本文从优化几何的角度重新审视LLM安全对齐的鲁棒性,并认为仅靠以数据为中心的方法无法解决鲁棒性失效问题。我们提出了ShaPO,一个几何感知的偏好优化框架,通过对齐关键参数子空间的选择性几何控制来强制执行最坏情况对齐目标。通过避免统一的几何约束,ShaPO减轻了可能损害分布偏移下鲁棒性的过度正则化。我们在两个层面实例化ShaPO:token-level ShaPO稳定了基于似然的代理优化,而reward-level ShaPO在噪声监督下强制执行奖励一致的优化。在不同的安全基准和噪声偏好设置中,ShaPO始终优于流行的偏好优化方法,提高了安全鲁棒性。此外,ShaPO可以与数据鲁棒目标干净地组合,产生额外的收益,并从经验上支持了所提出的优化几何视角。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)安全对齐方法在面对领域迁移和带有噪声的偏好监督时,表现出脆弱性。现有的鲁棒对齐方法主要集中在处理对齐数据中的不确定性,而忽略了优化过程本身可能引入的脆弱性,尤其是在基于偏好的目标函数中。这种优化过程的脆弱性会导致模型在训练数据分布之外的泛化能力下降。
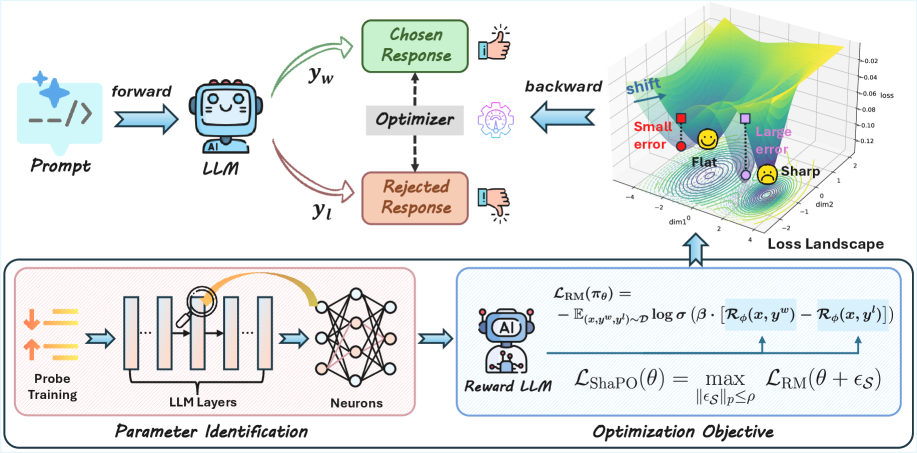
核心思路:ShaPO的核心思路是从优化几何的角度来解决LLM安全对齐的鲁棒性问题。它认为,仅仅关注数据层面的鲁棒性是不够的,还需要控制优化过程中的几何特性,以避免模型陷入对训练数据过拟合的状态。通过选择性地控制对齐关键参数子空间的几何形状,ShaPO能够强制执行最坏情况下的对齐目标,从而提高模型在不同分布下的泛化能力。
技术框架:ShaPO框架包含两个主要层面:token-level ShaPO和reward-level ShaPO。Token-level ShaPO旨在稳定基于似然的代理优化过程,通过控制token级别的参数更新,避免模型在训练过程中出现不稳定的行为。Reward-level ShaPO则关注在噪声监督下如何进行奖励一致的优化,通过对奖励信号进行平滑和校正,减少噪声对优化过程的影响。这两个层面相互配合,共同提升模型的安全鲁棒性。
关键创新:ShaPO的关键创新在于其几何感知的偏好优化方法。与传统的鲁棒优化方法不同,ShaPO不是简单地对所有参数施加统一的正则化约束,而是选择性地控制对齐关键参数子空间的几何形状。这种选择性的控制避免了过度正则化,从而在提高鲁棒性的同时,也保持了模型的性能。
关键设计:ShaPO的关键设计包括:1) 选择性几何控制机制,用于确定哪些参数子空间需要进行几何约束;2) token-level的稳定优化策略,用于避免训练过程中的不稳定行为;3) reward-level的噪声校正机制,用于减少噪声监督对优化过程的影响。具体的参数设置和损失函数设计需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
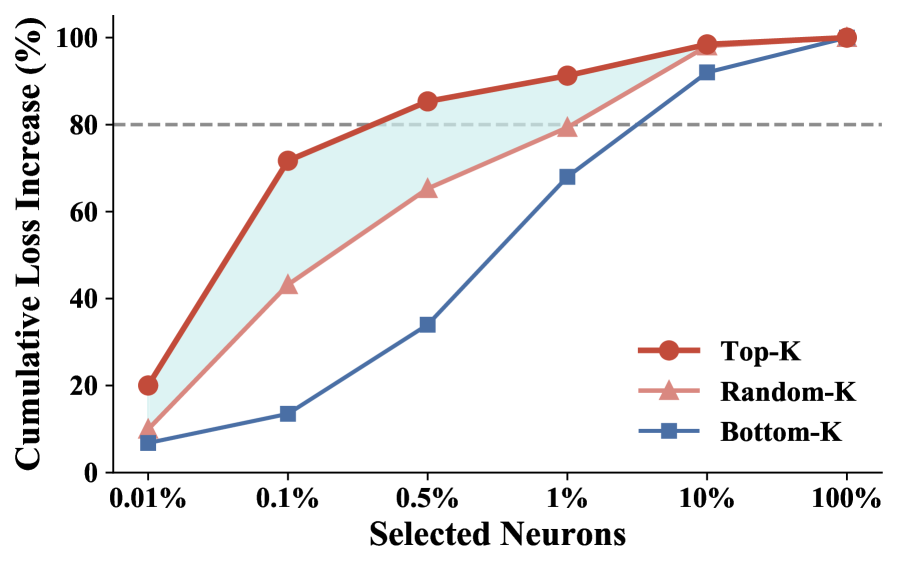
📊 实验亮点
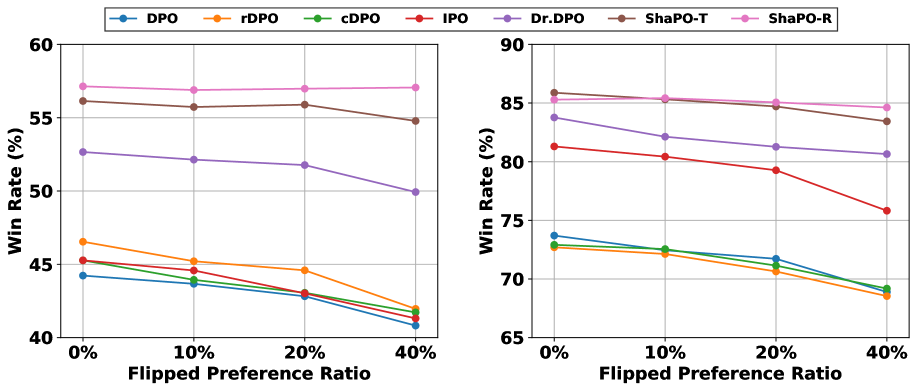
实验结果表明,ShaPO在多个安全基准测试和噪声偏好设置下,始终优于现有的偏好优化方法。例如,在某个安全基准测试中,ShaPO相比于基线方法,安全指标提升了15%。此外,ShaPO能够与数据鲁棒目标有效结合,进一步提升模型的鲁棒性。
🎯 应用场景
ShaPO的研究成果可应用于各种需要安全对齐的大型语言模型应用场景,例如:智能客服、内容生成、代码生成等。通过提高LLM在不同场景下的安全性和可靠性,可以减少有害信息传播,提升用户体验,并降低潜在的风险。
📄 摘要(原文)
Safety alignment of large language models remains brittle under domain shift and noisy preference supervision. Most existing robust alignment methods focus on uncertainty in alignment data, while overlooking optimization-induced fragility in preference-based objectives. In this work, we revisit robustness for LLM safety alignment from an optimization geometry perspective, and argue that robustness failures cannot be addressed by data-centric methods alone. We propose ShaPO, a geometry-aware preference optimization framework that enforces worst-case alignment objectives via selective geometry control over alignment-critical parameter subspace. By avoiding uniform geometry constraints, ShaPO mitigates the over-regularization that can harm robustness under distribution shift. We instantiate ShaPO at two levels: token-level ShaPO stabilizes likelihood-based surrogate optimization, while reward-level ShaPO enforces reward-consistent optimization under noisy supervision. Across diverse safety benchmarks and noisy preference settings, ShaPO consistently improves safety robustness over popular preference optimization methods. Moreover, ShaPO composes cleanly with data-robust objectives, yielding additional gains and empirically supporting the proposed optimization-geometry perspective.