Parallel Track Transformers: Enabling Fast GPU Inference with Reduced Synchronization
作者: Chong Wang, Nan Du, Tom Gunter, Tao Lei, Kulin Seth, Senyu Tong, Jianyu Wang, Guoli Yin, Xiyou Zhou, Kelvin Zou, Ruoming Pang
分类: cs.DC, cs.LG
发布日期: 2026-02-07
💡 一句话要点
提出并行轨道Transformer,减少同步操作,加速GPU推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 并行推理 GPU加速 LLM serving 张量并行
📋 核心要点
- 现有张量并行方法在多GPU LLM推理中引入大量同步操作,导致通信瓶颈,限制了可扩展性。
- 论文提出并行轨道(PT)Transformer,通过重构计算来最小化跨设备依赖,从而减少同步需求。
- 实验表明,PT Transformer在Tensor-RT-LLM和vLLM中均能有效提升推理效率,包括降低延迟和提高吞吐量。
📝 摘要(中文)
基于Transformer的大型语言模型(LLM)的高效大规模推理仍然是一个根本的系统挑战,通常需要多GPU并行来满足严格的延迟和吞吐量目标。传统的张量并行将矩阵运算分解到多个设备上,但引入了大量的GPU间同步,导致通信瓶颈和可扩展性降低。我们提出了并行轨道(PT)Transformer,这是一种新颖的架构范式,它重构了计算以最小化跨设备依赖性。在我们的实验中,PT相对于标准张量并行实现了高达16倍的同步操作减少,同时保持了具有竞争力的模型质量。我们将PT集成到两个广泛采用的LLM服务堆栈——Tensor-RT-LLM和vLLM——并报告了服务效率的持续改进,包括在两种设置中,首次token的时间减少了15-30%,每个输出token的时间减少了2-12%,吞吐量提高了31.90%。
🔬 方法详解
问题定义:现有基于Transformer的大型语言模型在多GPU环境下的推理面临严重的同步瓶颈。传统的张量并行方法虽然可以将计算任务分配到多个GPU上,但由于需要频繁地在GPU之间进行数据交换和同步,导致通信开销巨大,严重影响了推理速度和效率。尤其是在大规模模型和高并发场景下,这个问题更加突出。
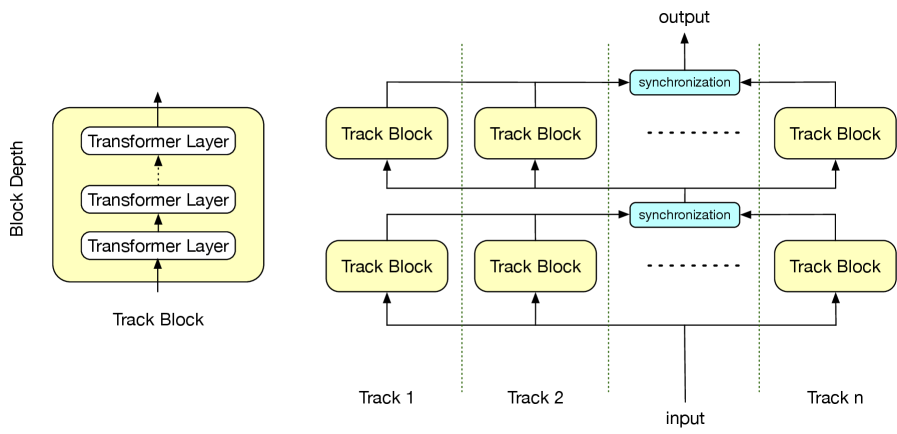
核心思路:论文的核心思路是通过重新设计Transformer的计算流程,减少GPU之间的依赖关系,从而降低同步操作的次数。具体来说,就是将Transformer的计算过程分解成多个可以并行执行的“轨道”,每个轨道内部的计算不需要与其他轨道进行同步,从而最大限度地利用GPU的并行计算能力。
技术框架:PT Transformer的核心在于其并行轨道的设计。Transformer的自注意力机制和前馈网络被重新组织成多个独立的计算轨道。每个轨道处理一部分输入数据,并且轨道之间的计算尽可能地解耦。整体架构上,PT Transformer仍然保持了Transformer的基本结构,包括多头注意力、前馈网络和残差连接等。论文将PT集成到Tensor-RT-LLM和vLLM两个主流的LLM serving框架中。
关键创新:PT Transformer的关键创新在于其并行轨道的设计,它通过重构Transformer的计算流程,显著减少了GPU之间的同步操作。与传统的张量并行方法相比,PT Transformer不需要将整个张量分割到多个GPU上,而是将计算任务分解成多个独立的轨道,每个轨道可以在不同的GPU上并行执行,从而避免了频繁的数据交换和同步。
关键设计:论文中没有详细说明关键参数设置、损失函数或网络结构的具体修改。重点在于架构层面的创新,即并行轨道的设计。具体实现细节可能依赖于所使用的LLM serving框架(Tensor-RT-LLM或vLLM)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PT Transformer在两种主流LLM serving框架(Tensor-RT-LLM和vLLM)中均能有效提升推理效率。具体来说,首次token的时间减少了15-30%,每个输出token的时间减少了2-12%,吞吐量提高了高达31.90%。这些数据表明,PT Transformer在降低延迟和提高吞吐量方面具有显著优势。
🎯 应用场景
该研究成果可广泛应用于需要高性能、低延迟的大型语言模型推理服务场景,例如在线对话机器人、智能客服、内容生成等。通过减少GPU同步开销,可以显著提升推理速度和吞吐量,降低部署成本,并为更复杂的AI应用提供支持。未来,该技术有望推广到其他类型的深度学习模型和异构计算平台。
📄 摘要(原文)
Efficient large-scale inference of transformer-based large language models (LLMs) remains a fundamental systems challenge, frequently requiring multi-GPU parallelism to meet stringent latency and throughput targets. Conventional tensor parallelism decomposes matrix operations across devices but introduces substantial inter-GPU synchronization, leading to communication bottlenecks and degraded scalability. We propose the Parallel Track (PT) Transformer, a novel architectural paradigm that restructures computation to minimize cross-device dependencies. PT achieves up to a 16x reduction in synchronization operations relative to standard tensor parallelism, while maintaining competitive model quality in our experiments. We integrate PT into two widely adopted LLM serving stacks-Tensor-RT-LLM and vLLM-and report consistent improvements in serving efficiency, including up to 15-30% reduced time to first token, 2-12% reduced time per output token, and up to 31.90% increased throughput in both settings.