ScaleBITS: Scalable Bitwidth Search for Hardware-Aligned Mixed-Precision LLMs
作者: Xinlin Li, Timothy Chou, Josh Fromm, Zichang Liu, Yunjie Pan, Christina Fragouli
分类: cs.LG, cs.AI
发布日期: 2026-02-06
💡 一句话要点
ScaleBITS:面向硬件友好的混合精度LLM可扩展比特宽度搜索
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化 大型语言模型 混合精度 比特宽度搜索 硬件加速
📋 核心要点
- 现有LLM量化方法在低比特率下性能下降明显,且细粒度混合精度方案引入了额外的运行时开销。
- ScaleBITS通过敏感性分析指导硬件对齐的块状权重划分,并使用双向通道重排序优化量化效果。
- ScaleBITS将比特宽度分配建模为约束优化问题,并提出可扩展的贪婪算法近似,在超低比特率下显著提升性能。
📝 摘要(中文)
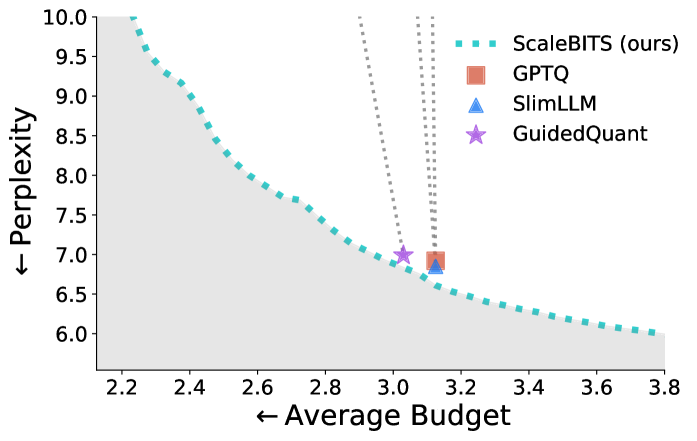
后训练权重量化对于降低大型语言模型(LLM)的内存和推理成本至关重要,但由于权重敏感性的高度非均匀性和缺乏有效的精度分配方法,将平均精度降低到4比特以下仍然具有挑战性。现有的解决方案要么使用不规则的细粒度混合精度,导致较高的运行时开销,要么依赖于启发式方法或高度受限的精度分配策略。本文提出了ScaleBITS,一个混合精度量化框架,能够在内存预算下实现自动化的细粒度比特宽度分配,同时保持硬件效率。在新的敏感性分析的指导下,我们引入了一种硬件对齐的、块状权重划分方案,并采用双向通道重排序。我们将全局比特宽度分配形式化为一个约束优化问题,并开发了一种可扩展的贪婪算法近似,从而实现端到端的有效分配。实验表明,ScaleBITS在超低比特率下显著优于均匀精度量化(高达+36%),并且优于最先进的敏感性感知基线(高达+13%),且不增加运行时开销。
🔬 方法详解
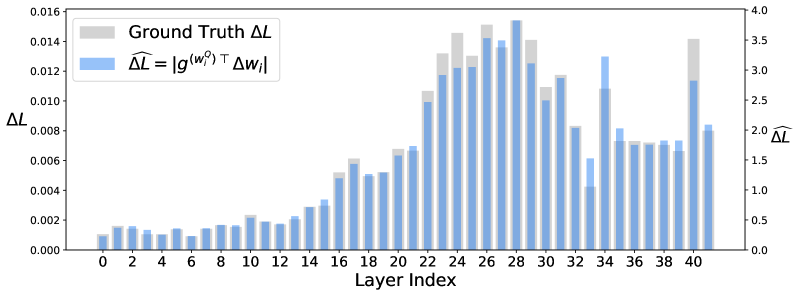
问题定义:论文旨在解决大型语言模型(LLM)量化过程中,如何在极低比特率下实现高效且准确的混合精度量化问题。现有方法,如均匀量化,在低比特率下性能损失严重;而细粒度混合精度量化虽然能提升性能,但会引入额外的运行时开销,影响硬件效率。此外,如何根据权重敏感性进行合理的比特分配也是一个挑战。
核心思路:ScaleBITS的核心思路是基于敏感性分析,设计一种硬件友好的块状权重划分方案,并结合双向通道重排序来优化量化效果。同时,将全局比特宽度分配建模为一个约束优化问题,并采用可扩展的贪婪算法近似来解决,从而在满足内存预算的条件下,实现最佳的精度分配。
技术框架:ScaleBITS框架主要包含以下几个阶段:1) 敏感性分析:分析LLM中不同权重的敏感性,为后续的比特分配提供依据。2) 硬件对齐的块状权重划分:根据敏感性分析结果,将权重划分为不同的块,并使其与硬件架构对齐,以提高硬件效率。3) 双向通道重排序:通过通道重排序,进一步优化量化效果。4) 全局比特宽度分配:将比特宽度分配建模为一个约束优化问题,并采用可扩展的贪婪算法近似来求解。
关键创新:ScaleBITS的关键创新在于:1) 提出了一种新的敏感性分析方法,能够更准确地评估权重的敏感性。2) 设计了一种硬件对齐的块状权重划分方案,能够提高硬件效率。3) 提出了双向通道重排序方法,进一步优化了量化效果。4) 开发了一种可扩展的贪婪算法近似,能够高效地解决全局比特宽度分配问题。
关键设计:ScaleBITS的关键设计包括:1) 敏感性分析的具体指标和计算方法。2) 块状权重划分的策略,如何保证硬件对齐。3) 双向通道重排序的具体算法。4) 约束优化问题的具体形式,以及贪婪算法近似的实现细节。这些设计共同保证了ScaleBITS能够在低比特率下实现高效且准确的量化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ScaleBITS在超低比特率下显著优于均匀精度量化(高达+36%),并且优于最先进的敏感性感知基线(高达+13%),且不增加运行时开销。这些结果验证了ScaleBITS在低比特率LLM量化方面的有效性。
🎯 应用场景
ScaleBITS可应用于各种需要低功耗、低延迟的边缘设备和移动设备,例如智能手机、物联网设备等。通过降低LLM的内存占用和推理成本,ScaleBITS能够使这些设备运行更复杂的AI应用,例如本地化的语音识别、机器翻译和自然语言理解,从而提升用户体验。
📄 摘要(原文)
Post-training weight quantization is crucial for reducing the memory and inference cost of large language models (LLMs), yet pushing the average precision below 4 bits remains challenging due to highly non-uniform weight sensitivity and the lack of principled precision allocation. Existing solutions use irregular fine-grained mixed-precision with high runtime overhead or rely on heuristics or highly constrained precision allocation strategies. In this work, we propose ScaleBITS, a mixed-precision quantization framework that enables automated, fine-grained bitwidth allocation under a memory budget while preserving hardware efficiency. Guided by a new sensitivity analysis, we introduce a hardware-aligned, block-wise weight partitioning scheme, powered by bi-directional channel reordering. We formulate global bitwidth allocation as a constrained optimization problem and develop a scalable approximation to the greedy algorithm, enabling end-to-end principled allocation. Experiments show that ScaleBITS significantly improves over uniform-precision quantization (up to +36%) and outperforms state-of-the-art sensitivity-aware baselines (up to +13%) in ultra-low-bit regime, without adding runtime overhead.