Pimp My LLM: Leveraging Variability Modeling to Tune Inference Hyperparameters
作者: Nada Zine, Clément Quinton, Romain Rouvoy
分类: cs.LG, cs.SE
发布日期: 2026-02-06
💡 一句话要点
利用变异性建模优化LLM推理超参数,提升效率与可持续性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理优化 变异性建模 超参数调优 能源效率 性能预测 Hugging Face Transformers
📋 核心要点
- 大型语言模型推理计算成本高昂,优化推理配置至关重要,但配置空间巨大,难以穷举。
- 论文将LLM视为可配置系统,利用变异性建模系统分析推理配置,降低了复杂性。
- 实验表明,该方法能有效分析超参数影响,预测推理行为,并支持高效配置。
📝 摘要(中文)
大型语言模型(LLMs)的应用日益广泛。然而,其巨大的计算需求引发了对训练和推理的能源效率和可持续性的担忧。特别是推理,它占据了总计算使用量的大部分,因此优化至关重要。最近的研究探索了优化技术,并分析了配置选择如何影响能源消耗。然而,由于组合爆炸,推理服务器的巨大配置空间使得详尽的经验评估变得不可行。在本文中,我们通过将LLM视为可配置系统,并应用变异性管理技术来系统地分析推理时的配置选择,从而为这个问题引入了一个新的视角。我们通过使用基于特征的变异性模型表示生成超参数及其约束,抽样代表性配置,测量其能耗、延迟、准确性,并从收集的数据中学习预测模型,从而在Hugging Face Transformers库上评估我们的方法。我们的结果表明,变异性建模有效地管理了LLM推理配置的复杂性。它能够系统地分析超参数的影响和相互作用,揭示权衡,并支持从有限数量的测量中准确预测推理行为。总的来说,这项工作开辟了一个新的研究方向,通过利用变异性建模来实现LLM的高效和可持续配置,从而桥接了软件工程和机器学习。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理过程中,由于超参数配置空间巨大,导致难以找到能源效率和性能最佳配置的问题。现有方法通常依赖于经验搜索或简单的启发式方法,无法有效地探索整个配置空间,导致次优的能源消耗和延迟。
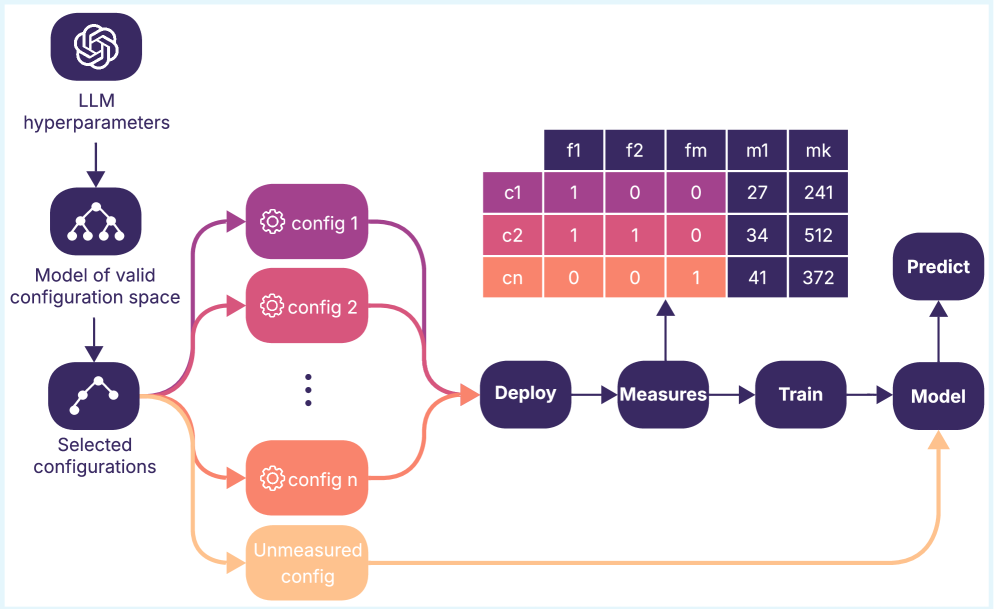
核心思路:论文的核心思路是将LLM推理过程视为一个可配置系统,利用软件工程中的变异性建模技术来管理和分析推理超参数。通过建立超参数之间的约束关系,可以有效地缩小搜索空间,并系统地评估不同配置对性能和能耗的影响。
技术框架:该方法主要包含以下几个阶段:1) 使用特征模型表示LLM的生成超参数及其约束;2) 从特征模型中抽样代表性的配置;3) 在Hugging Face Transformers库上运行这些配置,并测量其能耗、延迟和准确性;4) 使用收集到的数据训练预测模型,用于预测不同配置的性能。
关键创新:该方法最重要的创新点在于将软件工程中的变异性建模技术引入到LLM推理配置优化中。这种方法能够有效地管理LLM推理配置的复杂性,并系统地分析超参数的影响和相互作用,从而找到更优的配置。与传统的黑盒优化方法相比,该方法能够提供更深入的理解和解释。
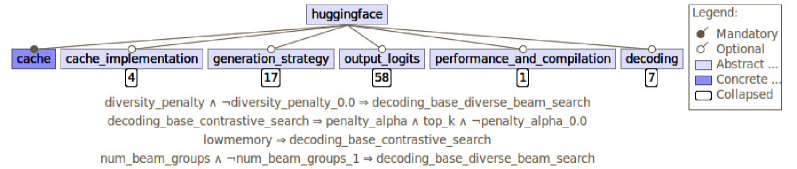
关键设计:论文使用基于特征的变异性模型来表示LLM的生成超参数及其约束。例如,可以定义某些超参数之间的依赖关系,或者限制某些超参数的取值范围。此外,论文还使用了不同的机器学习模型(如随机森林)来预测不同配置的性能。关键在于如何选择合适的特征模型和预测模型,以及如何平衡抽样配置的数量和评估成本。
🖼️ 关键图片
📊 实验亮点
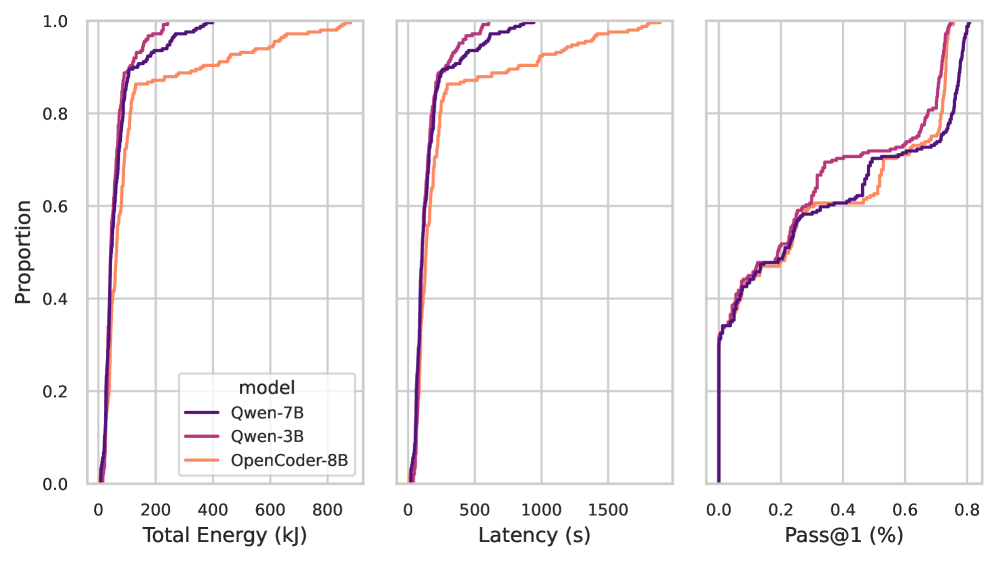
实验结果表明,变异性建模能够有效地管理LLM推理配置的复杂性,并能够从有限数量的测量中准确预测推理行为。该方法能够揭示超参数之间的权衡关系,例如,在某些情况下,可以通过牺牲少量准确性来显著降低能耗和延迟。具体性能数据未知,但论文强调了该方法在系统分析超参数影响和相互作用方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要高效和可持续LLM推理的场景,例如云服务提供商、边缘计算设备和移动应用。通过优化推理配置,可以降低能源消耗,提高推理速度,并延长设备的使用寿命。此外,该方法还可以帮助开发者更好地理解LLM的性能特征,并根据具体应用需求选择合适的配置。
📄 摘要(原文)
Large Language Models (LLMs) are being increasingly used across a wide range of tasks. However, their substantial computational demands raise concerns about the energy efficiency and sustainability of both training and inference. Inference, in particular, dominates total compute usage, making its optimization crucial. Recent research has explored optimization techniques and analyzed how configuration choices influence energy consumption. Yet, the vast configuration space of inference servers makes exhaustive empirical evaluation infeasible due to combinatorial explosion. In this paper, we introduce a new perspective on this problem by treating LLMs as configurable systems and applying variability management techniques to systematically analyze inference-time configuration choices. We evaluate our approach on the Hugging Face Transformers library by representing generation hyperparameters and their constraints using a feature-based variability model, sampling representative configurations, measuring their energy consumption, latency, accuracy, and learning predictive models from the collected data. Our results show that variability modeling effectively manages the complexity of LLM inference configurations. It enables systematic analysis of hyperparameters effects and interactions, reveals trade-offs, and supports accurate prediction of inference behavior from a limited number of measurements. Overall, this work opens a new research direction that bridges software engineering and machine learning by leveraging variability modeling for the efficient and sustainable configuration of LLMs.