Can LLM Safety Be Ensured by Constraining Parameter Regions?
作者: Zongmin Li, Jian Su, Farah Benamara, Aixin Sun
分类: cs.LG, cs.AI
发布日期: 2026-02-06
备注: 32 pages
💡 一句话要点
评估参数约束法在确保LLM安全性的有效性,发现现有方法难以可靠识别安全区域。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全性 参数约束 安全区域识别 IoU 安全对齐 模型评估
📋 核心要点
- 现有方法难以可靠识别LLM中稳定的、与数据集无关的安全区域,这给安全干预带来了挑战。
- 论文系统评估了四种安全区域识别方法,涵盖不同参数粒度,旨在寻找影响LLM安全行为的关键参数子集。
- 实验结果表明,当前技术识别的安全区域重叠度低,且对数据集敏感,无法保证LLM的安全性。
📝 摘要(中文)
大型语言模型(LLM)通常被认为包含“安全区域”——参数子集,其修改直接影响安全行为。我们对四种安全区域识别方法进行了系统评估,这些方法涵盖了不同的参数粒度,从单个权重到整个Transformer层,跨越了四个具有不同大小的主干LLM家族。使用十个安全识别数据集,我们发现识别出的安全区域仅表现出低到中等的重叠,如IoU所衡量。当使用效用数据集(即非有害查询)进一步细化安全区域时,重叠会显着下降。这些结果表明,当前的技术无法可靠地识别出一个稳定的、与数据集无关的安全区域。
🔬 方法详解
问题定义:论文旨在评估通过约束LLM参数区域来确保其安全性的可行性。现有的假设是,LLM存在一个或多个“安全区域”,修改这些区域的参数可以直接影响模型的安全行为。然而,现有方法在识别这些安全区域时缺乏稳定性和一致性,导致难以进行可靠的安全干预。
核心思路:论文的核心思路是通过系统性的实验评估,验证不同安全区域识别方法在不同LLM上的有效性。通过计算不同方法识别的安全区域之间的重叠度(IoU),以及评估这些区域对数据集的敏感性,来判断是否存在一个通用的、稳定的安全区域。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择四种具有代表性的安全区域识别方法,这些方法涵盖了不同的参数粒度(例如,单个权重、神经元、层)。2) 选择四个不同大小的LLM家族作为实验对象。3) 使用十个安全识别数据集来识别每个LLM的安全区域。4) 使用效用数据集(非有害查询)进一步细化安全区域。5) 计算不同方法和数据集识别的安全区域之间的IoU,评估其重叠度和稳定性。
关键创新:论文的关键创新在于对现有安全区域识别方法进行了全面的、系统性的评估。以往的研究通常只关注单个方法或单个模型,而本文则跨越了多种方法、多种模型和多种数据集,从而得出了更具普遍性的结论。此外,论文还考虑了效用数据集对安全区域的影响,这使得评估更加全面。
关键设计:论文的关键设计包括:1) 选择具有代表性的安全区域识别方法,例如基于梯度的、基于扰动的等。2) 使用IoU作为评估安全区域重叠度的指标。3) 使用效用数据集来评估安全区域的特异性,即确保识别的安全区域不会过度限制模型的正常功能。
🖼️ 关键图片
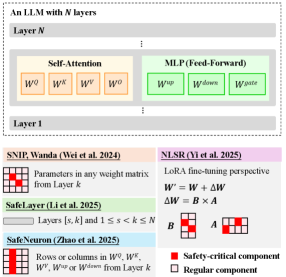
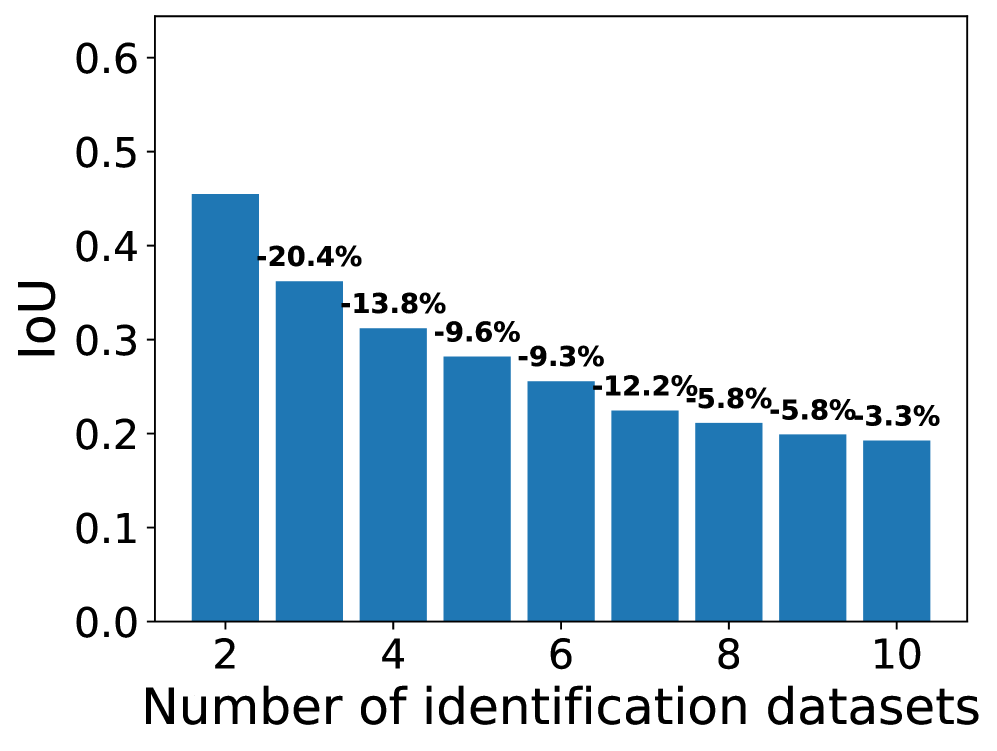
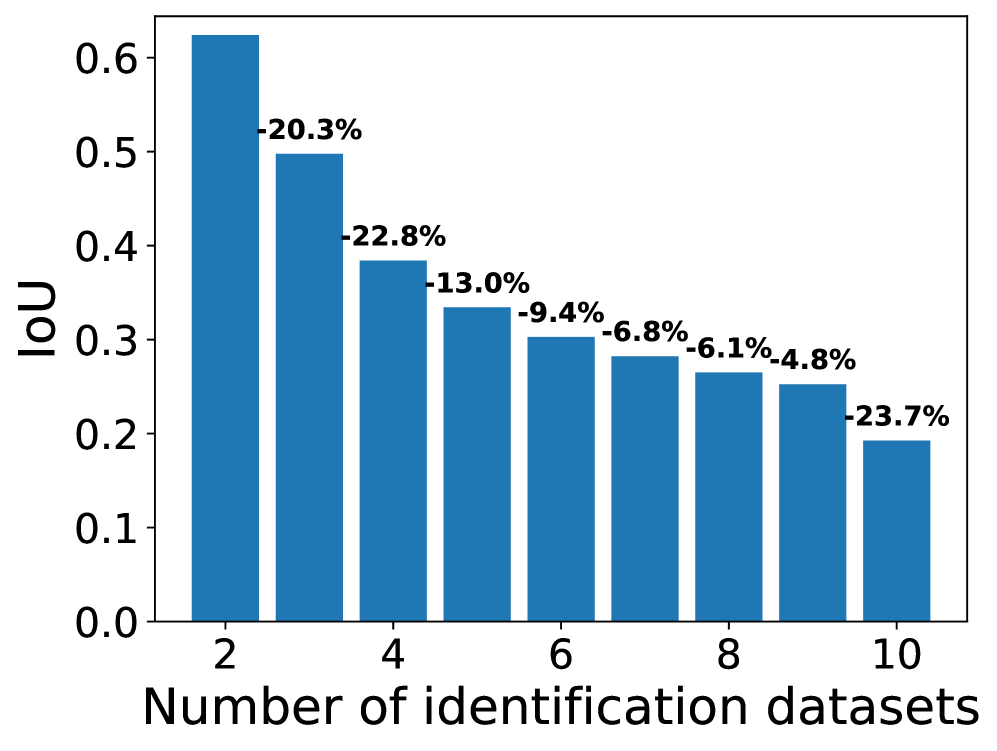
📊 实验亮点
实验结果表明,四种安全区域识别方法在不同LLM上识别的安全区域重叠度较低(IoU低至0.2左右),且对数据集敏感。使用效用数据集进一步细化安全区域后,重叠度显著下降。这些结果表明,当前技术无法可靠地识别出一个稳定的、与数据集无关的安全区域。
🎯 应用场景
该研究结果对LLM的安全对齐具有重要意义。如果无法可靠地识别安全区域,那么基于参数约束的安全干预方法可能无法有效保证LLM的安全性。未来的研究需要探索更有效、更稳定的安全区域识别方法,或者探索其他类型的安全干预策略,例如基于数据增强或基于强化学习的方法。
📄 摘要(原文)
Large language models (LLMs) are often assumed to contain ``safety regions'' -- parameter subsets whose modification directly influences safety behaviors. We conduct a systematic evaluation of four safety region identification methods spanning different parameter granularities, from individual weights to entire Transformer layers, across four families of backbone LLMs with varying sizes. Using ten safety identification datasets, we find that the identified safety regions exhibit only low to moderate overlap, as measured by IoU. The overlap drops significantly when the safety regions are further refined using utility datasets (\ie non-harmful queries). These results suggest that current techniques fail to reliably identify a stable, dataset-agnostic safety region.