AsynDBT: Asynchronous Distributed Bilevel Tuning for efficient In-Context Learning with Large Language Models
作者: Hui Ma, Shaoyu Dou, Ya Liu, Fei Xing, Li Feng, Feng Pi
分类: cs.LG, cs.AI
发布日期: 2026-02-06
备注: Accepted in Scientific Reports
💡 一句话要点
提出AsynDBT异步分布式双层调优算法,高效解决大语言模型上下文学习问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 联邦学习 分布式训练 异步优化 双层调优
📋 核心要点
- 现有上下文学习方法依赖高质量数据,但数据通常敏感且难以共享,阻碍了其发展。
- 提出AsynDBT算法,通过异步分布式双层调优,优化上下文学习样本和提示片段,提升下游任务性能。
- 理论分析保证算法收敛性,实验证明AsynDBT在多个基准数据集上有效且高效。
📝 摘要(中文)
随着大型语言模型(LLM)的快速发展,越来越多的应用利用云端LLM API来降低使用成本。然而,由于云端模型的参数和梯度是未知的,用户必须手动或使用启发式算法来调整提示,以干预LLM的输出,这需要昂贵的优化过程。上下文学习(ICL)最近成为一种有前景的范例,它使LLM能够使用输入中提供的示例来适应新任务,从而无需参数更新。然而,ICL的进步常常受到缺乏高质量数据的阻碍,这些数据通常是敏感的且难以共享。联邦学习(FL)提供了一种潜在的解决方案,通过实现分布式LLM的协作训练,同时保护数据隐私。尽管存在这些问题,但先前结合ICL的FL方法在严重的落后者问题和与异构非独立同分布数据相关的挑战中挣扎。为了解决这些问题,我们提出了一种异步分布式双层调优(AsynDBT)算法,该算法基于LLM的反馈来优化上下文学习样本和提示片段,从而提高下游任务的性能。受益于其分布式架构,AsynDBT提供了隐私保护和对异构计算环境的适应性。此外,我们提出了一个理论分析,建立了所提出算法的收敛性保证。在多个基准数据集上进行的大量实验证明了AsynDBT的有效性和效率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在上下文学习(ICL)中,由于缺乏高质量数据、数据隐私问题以及异构计算环境下的效率问题。现有方法,如手动调整prompt或启发式算法,成本高昂且效率低下;而联邦学习虽然能保护隐私,但面临严重的落后者问题和非独立同分布数据带来的挑战。
核心思路:论文的核心思路是提出一种异步分布式双层调优(AsynDBT)算法。该算法通过分布式架构,在保护数据隐私的前提下,利用LLM的反馈来优化上下文学习样本和prompt片段,从而提高下游任务的性能。异步更新机制旨在缓解落后者问题,提高训练效率。
技术框架:AsynDBT算法采用分布式架构,包含多个客户端和一个服务器。客户端持有本地数据,并在本地进行上下文学习样本和prompt片段的优化。服务器负责收集客户端的更新,并进行全局模型的更新。整个流程是异步的,客户端可以独立进行训练,无需等待其他客户端。双层调优体现在同时优化上下文学习样本和prompt片段,以获得更好的性能。
关键创新:AsynDBT的关键创新在于其异步分布式架构和双层调优策略。异步架构有效缓解了联邦学习中的落后者问题,提高了训练效率。双层调优策略能够同时优化上下文学习样本和prompt片段,从而更有效地利用LLM的上下文学习能力。此外,该算法还提供了隐私保护和对异构计算环境的适应性。
关键设计:AsynDBT算法的关键设计包括:1) 异步更新机制,允许客户端独立训练,减少等待时间;2) 双层优化目标,同时优化上下文学习样本和prompt片段;3) 针对异构数据的处理策略,例如使用不同的学习率或模型结构;4) 理论分析,保证算法的收敛性。
🖼️ 关键图片
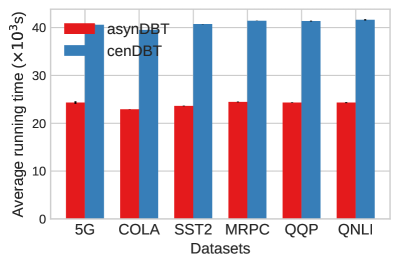
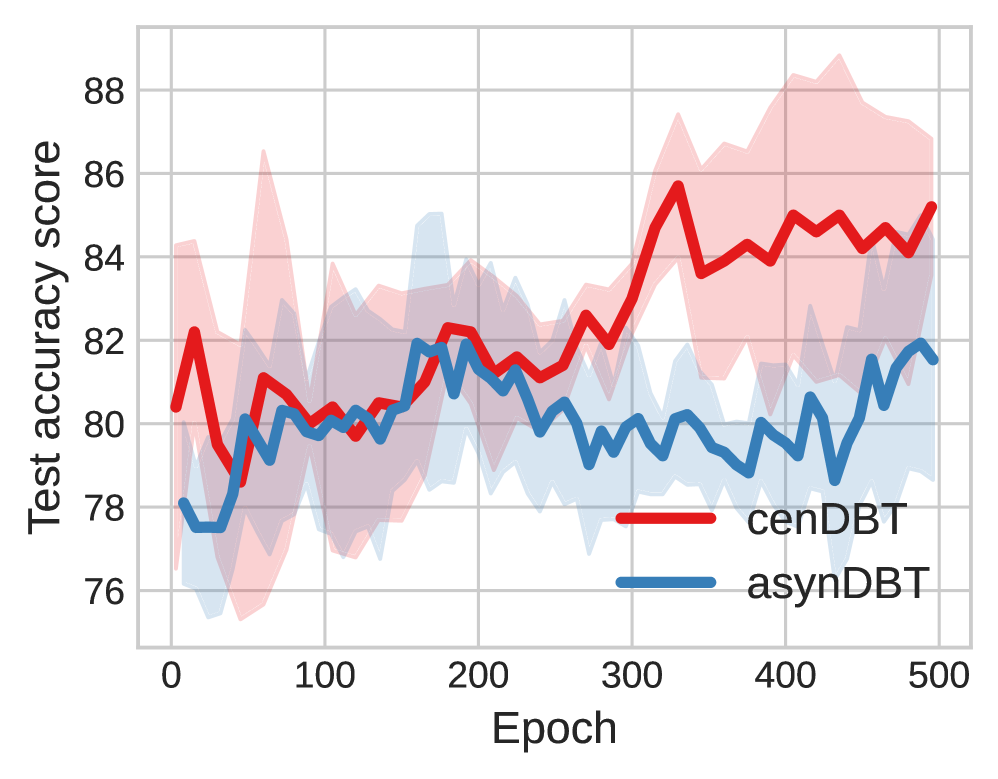
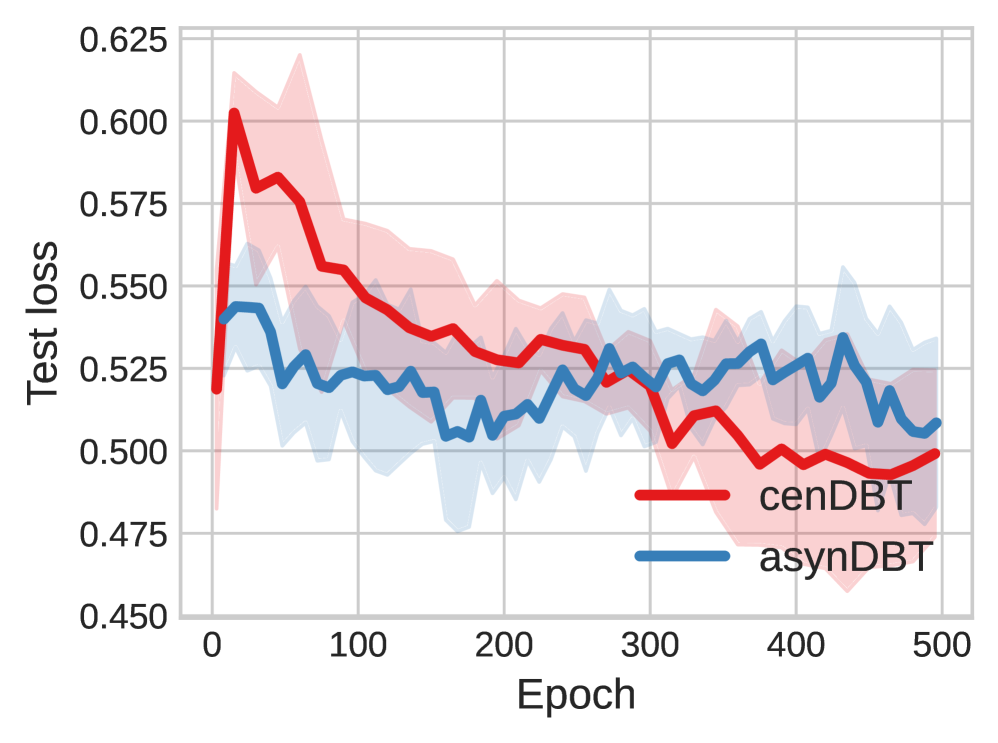
📊 实验亮点
论文在多个基准数据集上进行了实验,证明了AsynDBT算法的有效性和效率。实验结果表明,AsynDBT算法在下游任务的性能上优于现有的联邦学习方法。此外,实验还验证了AsynDBT算法在异构计算环境下的适应性,以及异步更新机制对缓解落后者问题的有效性。具体的性能提升数据在论文中有详细展示。
🎯 应用场景
AsynDBT算法可应用于各种需要利用大型语言模型进行上下文学习的场景,例如智能客服、文本生成、代码生成等。该算法尤其适用于数据敏感或分布式的环境,例如医疗、金融等领域。通过保护数据隐私和提高训练效率,AsynDBT能够促进大型语言模型在更广泛的应用场景中的部署和应用。
📄 摘要(原文)
With the rapid development of large language models (LLMs), an increasing number of applications leverage cloud-based LLM APIs to reduce usage costs. However, since cloud-based models' parameters and gradients are agnostic, users have to manually or use heuristic algorithms to adjust prompts for intervening LLM outputs, which requiring costly optimization procedures. In-context learning (ICL) has recently emerged as a promising paradigm that enables LLMs to adapt to new tasks using examples provided within the input, eliminating the need for parameter updates. Nevertheless, the advancement of ICL is often hindered by the lack of high-quality data, which is often sensitive and different to share. Federated learning (FL) offers a potential solution by enabling collaborative training of distributed LLMs while preserving data privacy. Despite this issues, previous FL approaches that incorporate ICL have struggled with severe straggler problems and challenges associated with heterogeneous non-identically data. To address these problems, we propose an asynchronous distributed bilevel tuning (AsynDBT) algorithm that optimizes both in-context learning samples and prompt fragments based on the feedback from the LLM, thereby enhancing downstream task performance. Benefiting from its distributed architecture, AsynDBT provides privacy protection and adaptability to heterogeneous computing environments. Furthermore, we present a theoretical analysis establishing the convergence guarantees of the proposed algorithm. Extensive experiments conducted on multiple benchmark datasets demonstrate the effectiveness and efficiency of AsynDBT.