XShare: Collaborative in-Batch Expert Sharing for Faster MoE Inference
作者: Daniil Vankov, Nikita Ivkin, Kyle Ulrich, Xiang Song, Ashish Khetan, George Karypis
分类: cs.LG, cs.AI
发布日期: 2026-02-06
💡 一句话要点
XShare:协同批内专家共享加速MoE模型推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 推理加速 专家选择 批处理 推测解码 GPU负载
📋 核心要点
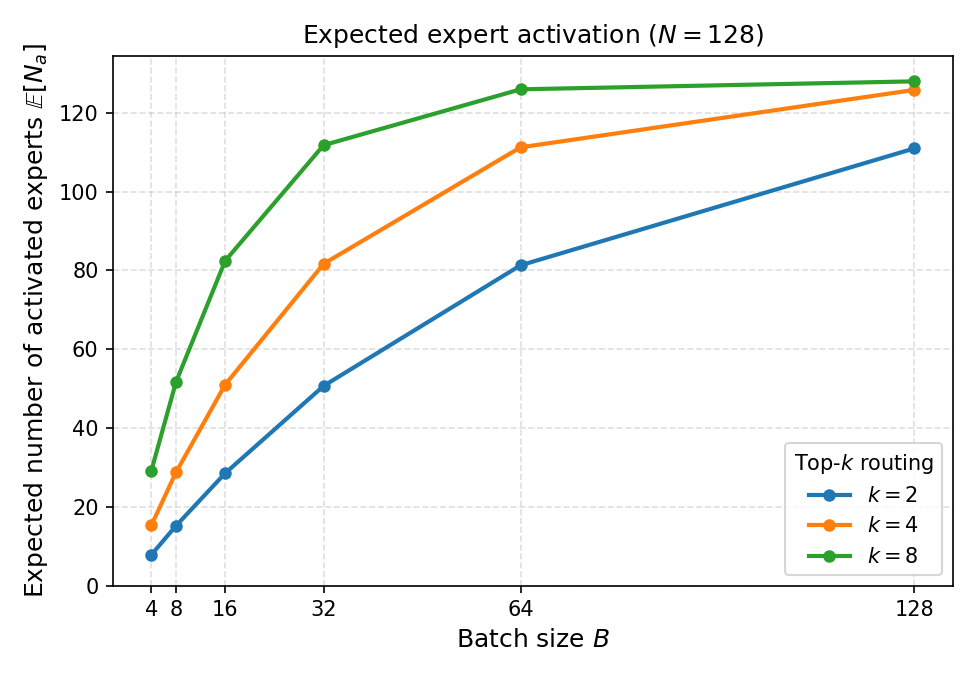
- MoE模型推理时,请求批处理和推测解码会加剧专家激活,降低效率。
- XShare将批处理感知的专家选择建模为优化问题,动态调整专家选择。
- 实验表明,XShare能减少专家激活、降低GPU负载,并提升吞吐量。
📝 摘要(中文)
混合专家模型(MoE)架构越来越多地被用于高效扩展大型语言模型。然而,在生产环境推理中,请求批处理和推测解码会显著放大专家激活,从而削弱这些效率优势。本文通过将批处理感知的专家选择建模为一个模块化优化问题,并为不同的部署设置设计高效的贪婪算法来解决这个问题。所提出的方法,即XShare,不需要重新训练,并通过最大化所选专家的总门控得分来动态适应每个批次。在标准批处理下,它最多可减少30%的专家激活,在专家并行部署中最多可减少3倍的峰值GPU负载,并且通过分层、感知相关性的专家选择,即使批次中的请求来自异构数据集,也能在推测解码中实现高达14%的吞吐量提升。
🔬 方法详解
问题定义:MoE模型在生产环境推理中,由于请求批处理和推测解码,导致专家激活数量显著增加,降低了模型的推理效率。现有方法难以在保证模型性能的同时,有效控制专家激活数量,尤其是在处理来自异构数据集的请求批次时,问题更加突出。
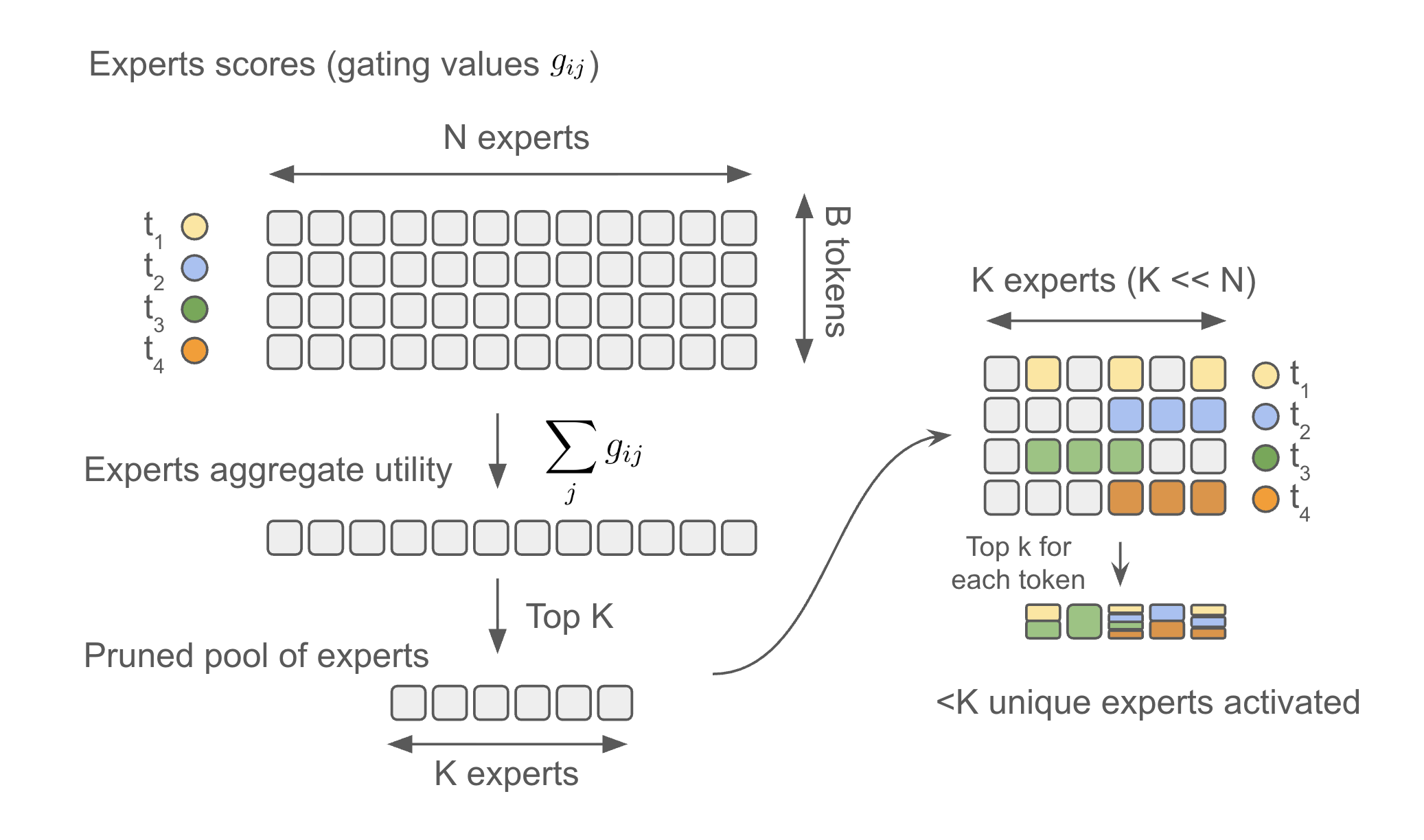
核心思路:XShare的核心思路是将批处理感知的专家选择问题建模为一个模块化的优化问题,目标是在每个批次中选择一组专家,使得这些专家能够最大化总的门控得分。通过动态调整专家选择策略,XShare能够适应不同的批处理和推测解码场景,从而降低专家激活数量,提高推理效率。
技术框架:XShare的技术框架主要包括以下几个模块:1) 门控得分计算模块:负责计算每个请求对每个专家的门控得分。2) 专家选择优化模块:基于门控得分,采用贪婪算法选择一组专家,以最大化总门控得分。该模块针对不同的部署场景(如标准批处理、专家并行部署、推测解码)设计了不同的贪婪算法。3) 专家激活模块:根据选择的专家,激活相应的专家进行计算。
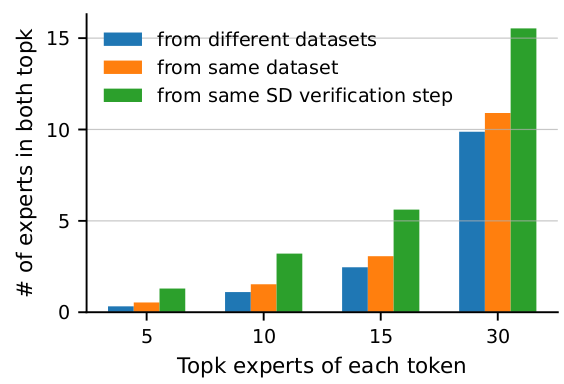
关键创新:XShare的关键创新在于其动态的、批处理感知的专家选择策略。与传统的静态专家选择方法不同,XShare能够根据每个批次的具体情况,动态调整专家选择,从而更好地适应不同的请求分布和推理场景。此外,针对推测解码,XShare还提出了分层的、感知相关性的专家选择方法,进一步提高了推理效率。
关键设计:XShare的关键设计包括:1) 贪婪算法:针对不同的部署场景,设计了不同的贪婪算法,以在计算复杂度和专家选择质量之间取得平衡。2) 分层专家选择:在推测解码中,采用分层专家选择策略,首先选择一组全局专家,然后再根据每个请求的具体情况,选择局部专家。3) 相关性感知:在推测解码中,考虑了请求之间的相关性,以选择更合适的专家组合。
🖼️ 关键图片
📊 实验亮点
实验结果表明,XShare在标准批处理下最多可减少30%的专家激活,在专家并行部署中最多可减少3倍的峰值GPU负载。在推测解码中,即使批次中的请求来自异构数据集,也能实现高达14%的吞吐量提升。这些结果表明,XShare能够有效提高MoE模型的推理效率,并降低部署成本。
🎯 应用场景
XShare可应用于各种需要高效MoE模型推理的场景,例如大规模语言模型的在线服务、智能对话系统、机器翻译等。通过降低专家激活数量和GPU负载,XShare能够显著提高推理吞吐量,降低部署成本,并支持更大规模的模型部署。该研究对于推动MoE模型在实际应用中的普及具有重要意义。
📄 摘要(原文)
Mixture-of-Experts (MoE) architectures are increasingly used to efficiently scale large language models. However, in production inference, request batching and speculative decoding significantly amplify expert activation, eroding these efficiency benefits. We address this issue by modeling batch-aware expert selection as a modular optimization problem and designing efficient greedy algorithms for different deployment settings. The proposed method, namely XShare, requires no retraining and dynamically adapts to each batch by maximizing the total gating score of selected experts. It reduces expert activation by up to 30% under standard batching, cuts peak GPU load by up to 3x in expert-parallel deployments, and achieves up to 14% throughput gains in speculative decoding via hierarchical, correlation-aware expert selection even if requests in a batch drawn from heterogeneous datasets.