tLoRA: Efficient Multi-LoRA Training with Elastic Shared Super-Models
作者: Kevin Li, Dibyadeep Saha, Avni Kanodia, Fan Lai
分类: cs.LG
发布日期: 2026-02-06 (更新: 2026-02-13)
💡 一句话要点
tLoRA:通过弹性共享超模型实现高效的多LoRA训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩适应 LoRA 参数高效微调 分布式训练 资源调度 弹性模型 大语言模型 GPU优化
📋 核心要点
- 现有LoRA训练在共享集群中面临异构任务的挑战,简单批量处理导致同步停顿和通信开销。
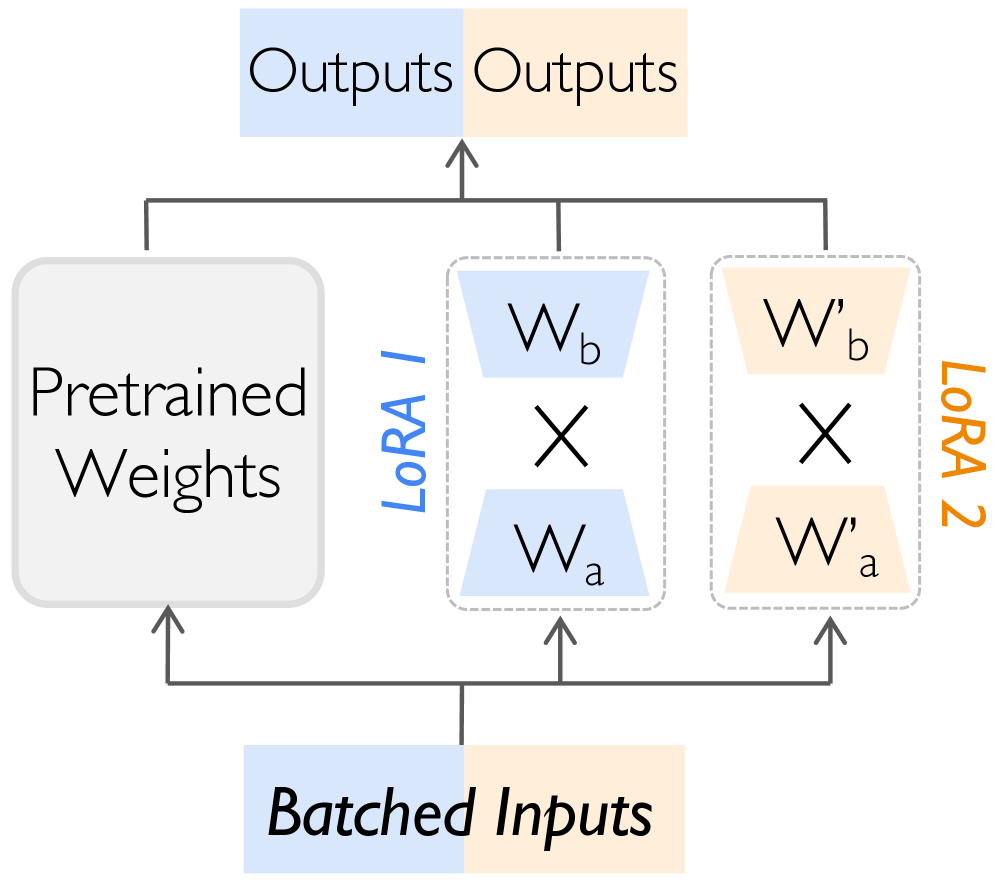
- tLoRA通过融合适配器为弹性共享超模型,并利用分布式训练框架实现资源高效共享。
- 实验表明,tLoRA显著提升训练吞吐量、缩短任务完成时间并提高GPU利用率。
📝 摘要(中文)
随着低秩适应(LoRA)成为高效微调大型语言模型(LLM)的标准方法,共享集群越来越多地在同一冻结骨干网络上执行许多并发的LoRA训练任务。虽然最近的进展使得在服务期间可以批量处理(共址)多个适配器,但异构LoRA适配器在训练时进行高效共址带来了独特的挑战。任务在适配器秩、批量大小和资源分配方面通常不同,并且简单的批量处理会引入同步停顿、通信开销和每个任务的减速,这些问题比独立执行更糟糕。我们介绍了tLoRA,一个能够高效批量训练多个LoRA任务的框架。tLoRA将共享相同基础模型的适配器融合到一个弹性共享超模型中,利用现有的分布式训练框架来推导出有效共享资源的并行计划。在内核级别,tLoRA采用融合的LoRA内核,该内核自适应地重建低秩计算块并调度秩感知的纳米批次,以最大化适配器之间的计算和通信重叠。在调度层,tLoRA包含一个在线的、剩余容量感知的调度器,该调度器自适应地对任务进行分组以最大化集体吞吐量。使用真实集群跟踪的评估表明,tLoRA将训练吞吐量提高了1.2-1.8倍,任务训练完成时间提高了2.3-5.4倍,GPU利用率提高了37%。
🔬 方法详解
问题定义:论文旨在解决在共享集群上高效训练多个异构LoRA适配器的问题。现有方法在直接批量处理不同秩、批量大小和资源分配的LoRA任务时,会引入显著的同步开销和通信瓶颈,导致整体训练效率低下。现有方法无法充分利用集群资源,导致任务完成时间长,GPU利用率低。
核心思路:tLoRA的核心思路是将共享相同基础模型的多个LoRA适配器融合为一个“弹性共享超模型”。通过这种融合,可以将多个独立的LoRA训练任务转化为一个统一的分布式训练任务,从而可以利用现有的分布式训练框架进行高效的资源调度和并行计算。这种方法旨在最大化计算和通信的重叠,减少同步开销,并提高整体训练吞吐量。
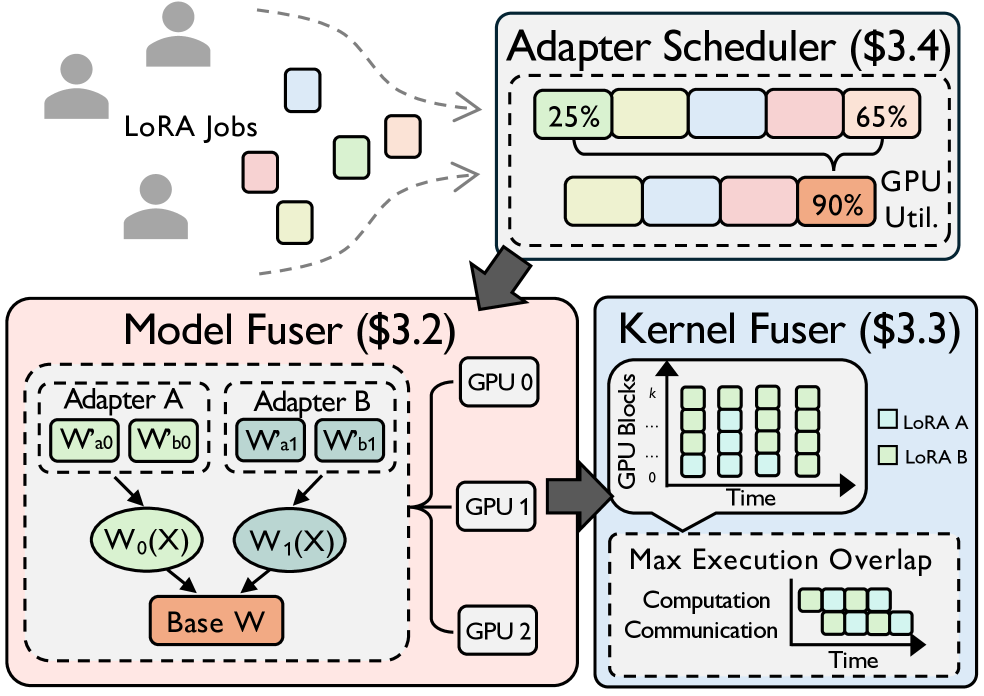
技术框架:tLoRA框架包含两个主要组件:融合的LoRA内核和在线剩余容量感知的调度器。融合的LoRA内核负责在GPU级别优化低秩计算,自适应地重建低秩计算块并调度秩感知的纳米批次,以最大化计算和通信重叠。在线剩余容量感知的调度器负责在集群级别动态地对任务进行分组,以最大化集体吞吐量。该调度器根据集群的剩余容量和任务的资源需求,自适应地调整任务分组策略。
关键创新:tLoRA的关键创新在于其弹性共享超模型的概念和融合的LoRA内核的设计。弹性共享超模型允许将多个LoRA适配器融合为一个统一的训练任务,从而可以利用现有的分布式训练框架进行高效的资源调度和并行计算。融合的LoRA内核通过自适应地重建低秩计算块和调度秩感知的纳米批次,最大化了计算和通信的重叠,从而提高了GPU利用率。
关键设计:tLoRA的关键设计包括:1) 融合的LoRA内核,它使用CUDA kernel实现,并针对不同的LoRA秩进行优化;2) 在线剩余容量感知的调度器,它使用贪心算法来对任务进行分组,并根据集群的剩余容量和任务的资源需求动态地调整分组策略;3) 弹性共享超模型,它允许将多个LoRA适配器融合为一个统一的训练任务,并使用现有的分布式训练框架进行训练。
🖼️ 关键图片
📊 实验亮点
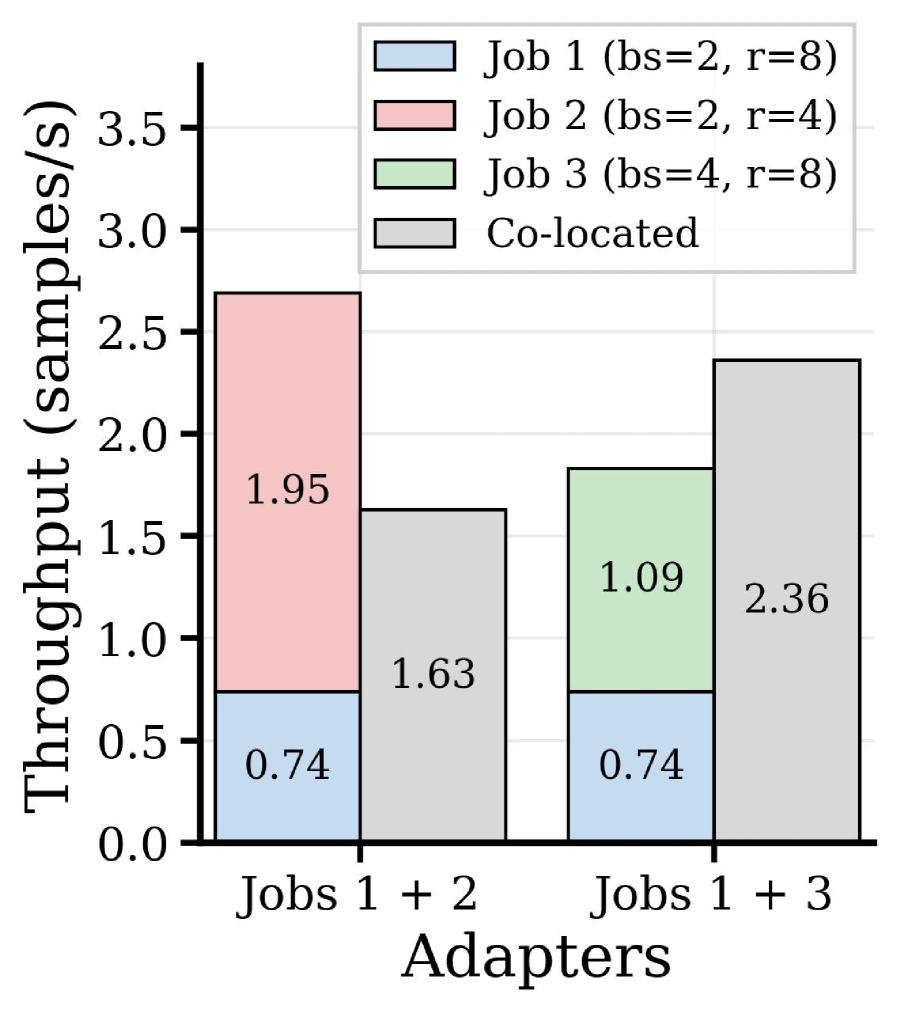
实验结果表明,tLoRA在真实集群跟踪数据上,相比于独立训练,将训练吞吐量提高了1.2-1.8倍,任务训练完成时间缩短了2.3-5.4倍,GPU利用率提高了37%。这些数据表明tLoRA在提高LoRA训练效率方面具有显著优势。
🎯 应用场景
tLoRA适用于需要高效微调大型语言模型的各种场景,例如:模型定制、领域迁移学习、持续学习等。该技术可以显著降低训练成本,缩短开发周期,并提高资源利用率。未来,tLoRA可以扩展到支持更多类型的适配器和更复杂的训练任务。
📄 摘要(原文)
As Low-Rank Adaptation (LoRA) becomes the standard approach for efficiently fine-tuning large language models (LLMs), shared clusters increasingly execute many concurrent LoRA training jobs over the same frozen backbone. While recent advances enable batching (co-locating) multiple adapters during serving, efficient training-time co-location of heterogeneous LoRA adapters presents unique challenges. Jobs often differ in adapter rank, batch size, and resource allocation, and naïve batching can introduce synchronization stalls, communication overheads, and per-job slowdowns that are worse than executing independently. We introduce tLoRA, a framework that enables efficient batch training of multiple LoRA jobs. tLoRA fuses adapters that share the same base model into an elastic shared super-model, exploiting existing distributed training frameworks to derive parallelism plans that share resources effectively. At the kernel level, tLoRA employs a fused LoRA kernel that adaptively reconstructs low-rank computation tiles and schedules rank-aware nano-batches to maximize overlap between computation and communication across adapters. At the scheduling layer, tLoRA incorporates an online, residual-capacity-aware scheduler that adaptively groups jobs to maximize collective throughput. Evaluations using real-world cluster traces demonstrate that tLoRA improves training throughput by 1.2--1.8x, job training completion time by 2.3--5.4x, and GPU utilization by 37%.