Cerebellar-Inspired Residual Control for Fault Recovery: From Inference-Time Adaptation to Structural Consolidation
作者: Nethmi Jayasinghe, Diana Gontero, Spencer T. Brown, Vinod K. Sangwan, Mark C. Hersam, Amit Ranjan Trivedi
分类: cs.LG, cs.RO
发布日期: 2026-02-06
💡 一句话要点
提出基于小脑的残差控制框架,用于机器人故障恢复和在线自适应。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 残差控制 故障恢复 强化学习 小脑模型 在线自适应
📋 核心要点
- 现实环境中部署的机器人策略常遇到训练后故障,而重新训练、探索或系统辨识不切实际。
- 论文提出一种受小脑启发的残差控制框架,通过在线修正动作增强冻结的强化学习策略,实现故障恢复。
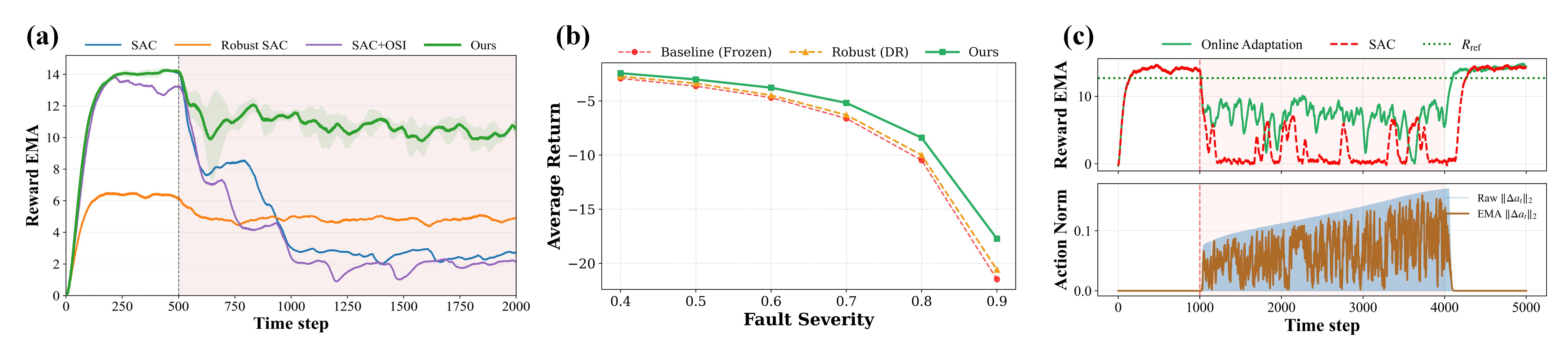
- 实验表明,该框架在MuJoCo基准测试中,针对多种扰动,性能显著提升,并具有良好的鲁棒性。
📝 摘要(中文)
本文提出了一种受小脑启发的残差控制框架,用于增强冻结的强化学习策略,使其能够在推理时进行在线修正,从而实现故障恢复,而无需修改基础策略参数。该框架实例化了小脑的核心原则,包括通过固定特征扩展实现高维模式分离、并行微区风格的残差路径,以及具有在不同时间尺度上运行的兴奋性和抑制性资格迹的局部误差驱动可塑性。这些机制能够在训练后扰动下实现快速、局部校正,同时避免破坏全局策略更新。保守的、性能驱动的元自适应调节残差权限和可塑性,保持标称行为并抑制不必要的干预。在MuJoCo基准测试中,针对执行器、动态和环境扰动的实验表明,在中等故障下, exttt{HalfCheetah-v5}的性能提升高达+66%, exttt{Humanoid-v5}的性能提升高达+53%,在严重偏移下表现出优雅的降级,并通过将持久残差校正整合到策略参数中获得互补的鲁棒性。
🔬 方法详解
问题定义:现实机器人部署中,预训练的强化学习策略容易受到训练后故障的影响,例如执行器损坏、环境变化等。传统的解决方案如重训练或在线探索成本高昂且不实用。因此,如何在不修改原有策略参数的情况下,快速适应并恢复性能成为一个关键问题。
核心思路:本文的核心思路是借鉴小脑的结构和功能,设计一个残差控制框架,该框架在原有冻结的强化学习策略之上,增加一个可学习的修正模块。该模块通过在线学习,对原有策略的输出进行微调,从而补偿故障带来的影响。这种方法避免了对原有策略的全局修改,保证了在无故障情况下的性能。
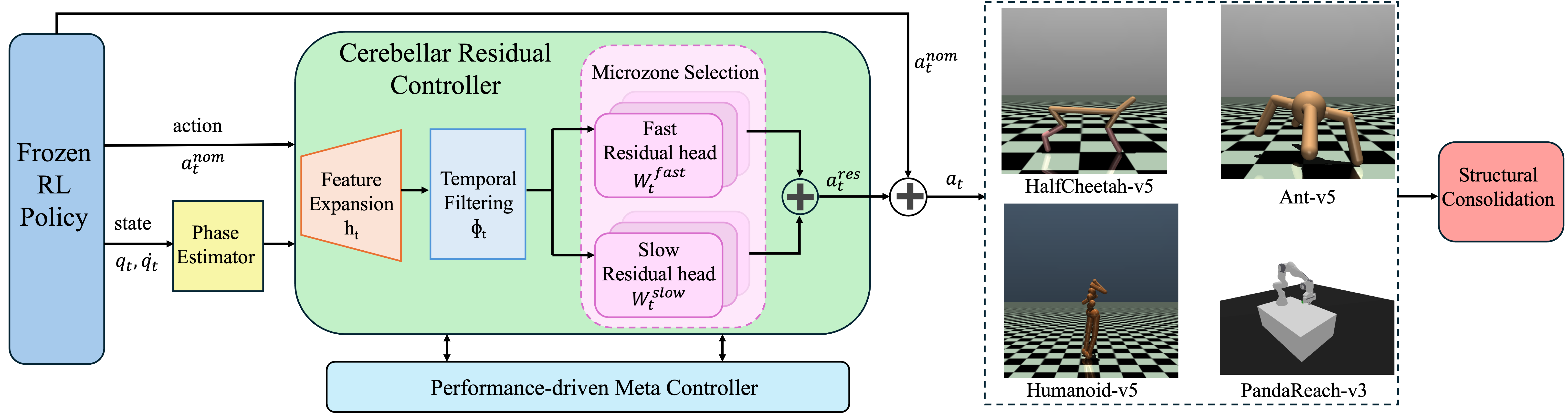
技术框架:该框架包含以下几个主要模块:1) 固定特征扩展模块,用于将输入状态映射到高维空间,实现模式分离;2) 并行微区风格的残差路径,每个路径负责对特定状态区域进行修正;3) 局部误差驱动可塑性模块,利用兴奋性和抑制性资格迹,在不同时间尺度上调整残差路径的权重;4) 元自适应模块,用于调节残差控制的权限和可塑性,防止过度干预。整体流程是,首先利用固定特征扩展模块处理输入状态,然后通过残差路径计算修正动作,最后将修正动作与原有策略的输出相加,得到最终的控制指令。
关键创新:该方法最重要的创新点在于借鉴了小脑的结构和功能,将其应用于机器人控制的故障恢复。具体来说,利用小脑的模式分离、并行处理和局部学习能力,实现了快速、鲁棒的在线自适应。与传统的残差控制方法相比,该方法更加高效和稳定,能够更好地应对复杂的故障情况。
关键设计:在技术细节上,该方法采用了以下关键设计:1) 使用高斯径向基函数(RBF)作为固定特征扩展的基函数;2) 利用TD误差作为局部误差驱动可塑性的信号;3) 设计了兴奋性和抑制性资格迹,分别用于加速学习和防止过度修正;4) 采用性能驱动的元自适应策略,根据当前性能动态调整残差控制的权重。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在MuJoCo基准测试中,针对执行器、动态和环境扰动,取得了显著的性能提升。例如,在 exttt{HalfCheetah-v5}环境中,中等故障下的性能提升高达+66%,在 exttt{Humanoid-v5}环境中,性能提升高达+53%。此外,该方法还表现出良好的鲁棒性,能够在严重偏移下实现优雅的降级。通过将持久残差校正整合到策略参数中,进一步提高了系统的适应能力。
🎯 应用场景
该研究成果可应用于各种需要在复杂和动态环境中运行的机器人系统,例如自动驾驶汽车、无人机、工业机器人等。通过该方法,机器人能够更好地应对意外故障和环境变化,提高系统的可靠性和安全性。此外,该方法还可以用于个性化机器人控制,根据用户的习惯和偏好,在线调整控制策略。
📄 摘要(原文)
Robotic policies deployed in real-world environments often encounter post-training faults, where retraining, exploration, or system identification are impractical. We introduce an inference-time, cerebellar-inspired residual control framework that augments a frozen reinforcement learning policy with online corrective actions, enabling fault recovery without modifying base policy parameters. The framework instantiates core cerebellar principles, including high-dimensional pattern separation via fixed feature expansion, parallel microzone-style residual pathways, and local error-driven plasticity with excitatory and inhibitory eligibility traces operating at distinct time scales. These mechanisms enable fast, localized correction under post-training disturbances while avoiding destabilizing global policy updates. A conservative, performance-driven meta-adaptation regulates residual authority and plasticity, preserving nominal behavior and suppressing unnecessary intervention. Experiments on MuJoCo benchmarks under actuator, dynamic, and environmental perturbations show improvements of up to $+66\%$ on \texttt{HalfCheetah-v5} and $+53\%$ on \texttt{Humanoid-v5} under moderate faults, with graceful degradation under severe shifts and complementary robustness from consolidating persistent residual corrections into policy parameters.