SpecAttn: Co-Designing Sparse Attention with Self-Speculative Decoding
作者: Yikang Yue, Yuqi Xue, Jian Huang
分类: cs.LG
发布日期: 2026-02-06
💡 一句话要点
SpecAttn:通过自验证引导的稀疏注意力加速长文本LLM的自推测解码。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本LLM 自推测解码 稀疏注意力 KV缓存 推理加速
📋 核心要点
- 长文本LLM推理受限于KV缓存的内存需求,现有稀疏注意力方法的KV选择算法效率较低。
- SpecAttn利用验证过程中的信息来识别关键KV条目,仅加载这些条目用于后续tokens的起草。
- 实验表明,SpecAttn在吞吐量上优于传统自回归解码和现有稀疏自推测解码方法。
📝 摘要(中文)
长上下文大型语言模型(LLM)的推理已成为当今AI应用的标准。然而,它受到KV缓存日益增长的内存需求的严重限制。先前的工作表明,使用稀疏注意力的自推测解码,即使用KV缓存的子集来起草tokens,并与完整的KV缓存并行验证,可以无损地加速推理。然而,这种方法依赖于独立的KV选择算法来选择用于起草的KV条目,并且忽略了每个KV条目的重要性在验证期间被固有地计算出来。在本文中,我们提出了SpecAttn,一种具有验证引导的稀疏注意力的自推测解码方法。SpecAttn将关键KV条目识别为验证的副产品,并且仅在起草后续tokens时加载这些条目。这不仅提高了草稿token的接受率,而且降低了KV选择开销,从而提高了解码吞吐量。SpecAttn实现了比原始自回归解码高2.81倍的吞吐量,并且比最先进的基于稀疏性的自推测解码方法提高了1.29倍。
🔬 方法详解
问题定义:长文本LLM推理过程中,KV缓存的内存需求成为瓶颈。现有的自推测解码方法虽然利用稀疏注意力加速推理,但其KV选择算法是独立的,效率不高,且忽略了验证过程中蕴含的关键信息。
核心思路:SpecAttn的核心思想是利用自推测解码的验证过程来指导稀疏注意力的KV选择。在验证过程中,模型已经计算了每个KV条目的重要性,SpecAttn将这些信息用于后续tokens的起草,从而更有效地选择关键KV条目。
技术框架:SpecAttn沿用自推测解码的框架,包含drafting和verification两个阶段。不同之处在于,SpecAttn在drafting阶段使用的KV缓存不是通过独立的KV选择算法选择的,而是通过verification阶段的副产品——KV条目的重要性得分来选择的。整体流程为:首先,使用少量KV缓存进行drafting,生成草稿tokens;然后,使用完整KV缓存进行verification,验证草稿tokens;最后,利用verification阶段的信息选择关键KV条目,用于后续tokens的drafting。
关键创新:SpecAttn的关键创新在于将verification过程与稀疏注意力的KV选择相结合。传统方法将两者视为独立的步骤,而SpecAttn则利用verification过程中的信息来指导KV选择,从而提高了KV选择的效率和准确性。
关键设计:SpecAttn的关键设计在于如何从verification阶段提取KV条目的重要性得分。具体实现方式未知,论文中可能涉及注意力权重或其他相关指标的计算和选择策略。此外,如何平衡drafting阶段的KV缓存大小和计算开销也是一个重要的设计考虑。
🖼️ 关键图片

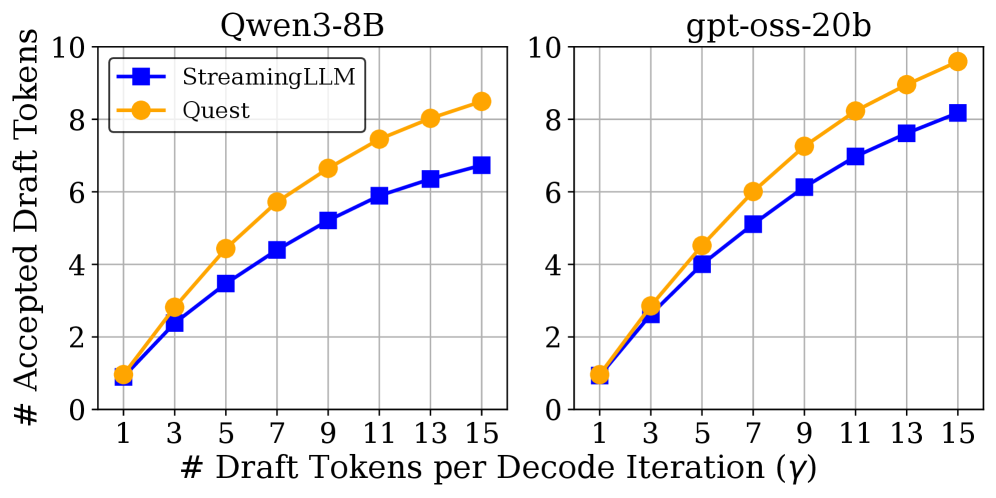
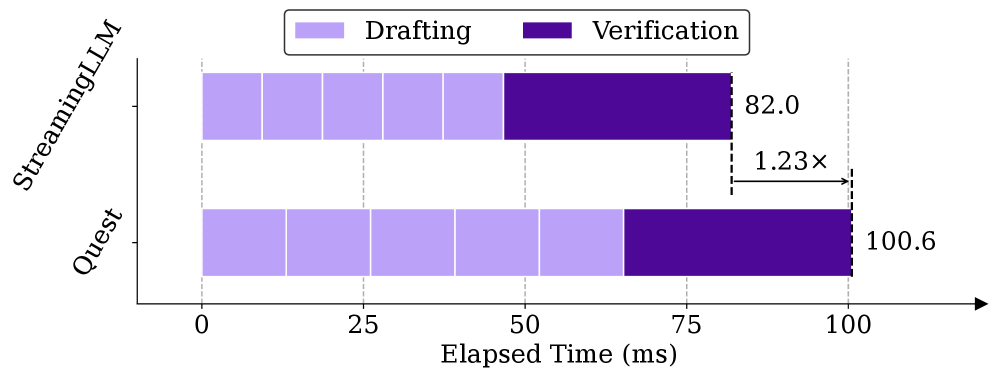
📊 实验亮点
SpecAttn在实验中表现出色,相较于原始自回归解码,吞吐量提升了2.81倍。与最先进的基于稀疏性的自推测解码方法相比,吞吐量也提升了1.29倍。这些结果表明,SpecAttn能够有效地加速长文本LLM的推理过程。
🎯 应用场景
SpecAttn可应用于各种需要长文本LLM推理的场景,例如:长篇文档摘要、代码生成、对话系统等。通过提高推理吞吐量,SpecAttn可以降低计算成本,并提升用户体验。该研究对于推动长文本LLM在实际应用中的普及具有重要意义。
📄 摘要(原文)
Long-context large language model (LLM) inference has become the norm for today's AI applications. However, it is severely bottlenecked by the increasing memory demands of its KV cache. Previous works have shown that self-speculative decoding with sparse attention, where tokens are drafted using a subset of the KV cache and verified in parallel with full KV cache, speeds up inference in a lossless way. However, this approach relies on standalone KV selection algorithms to select the KV entries used for drafting and overlooks that the criticality of each KV entry is inherently computed during verification. In this paper, we propose SpecAttn, a self-speculative decoding method with verification-guided sparse attention. SpecAttn identifies critical KV entries as a byproduct of verification and only loads these entries when drafting subsequent tokens. This not only improves draft token acceptance rate but also incurs low KV selection overhead, thereby improving decoding throughput. SpecAttn achieves 2.81$\times$ higher throughput over vanilla auto-regressive decoding and 1.29$\times$ improvement over state-of-the-art sparsity-based self-speculative decoding methods.