Collaborative and Efficient Fine-tuning: Leveraging Task Similarity
作者: Gagik Magakyan, Amirhossein Reisizadeh, Chanwoo Park, Pablo A. Parrilo, Asuman Ozdaglar
分类: cs.LG, cs.AI, stat.ML
发布日期: 2026-02-06
💡 一句话要点
提出CoLoRA,利用任务相似性协同高效地微调个性化大模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 协同学习 任务相似性 低秩适应 个性化模型
📋 核心要点
- 现有参数高效微调方法面临数据稀缺挑战,限制了大型模型在特定任务上的性能。
- CoLoRA通过训练共享适配器捕获任务间的相似性,并结合个性化适配器实现高效协同微调。
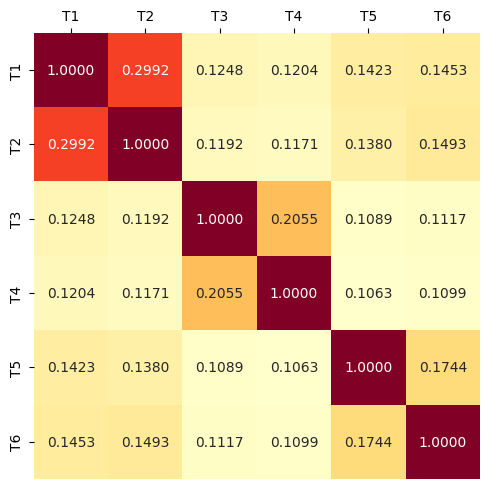
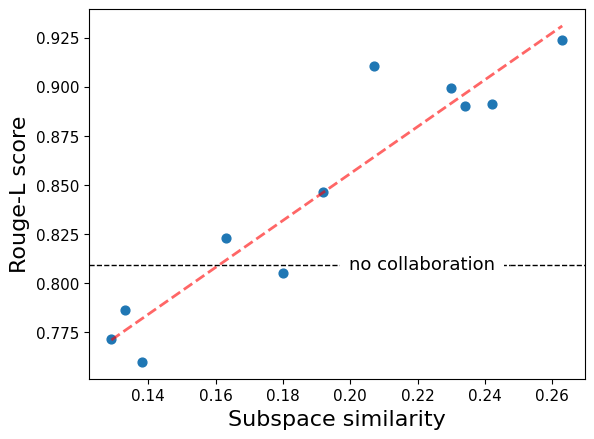
- 理论分析和自然语言实验表明,CoLoRA能显著提升个体任务的性能,尤其是在相似任务协同训练时。
📝 摘要(中文)
适应性是基础模型的核心特征,使其能够有效地适应未见过的下游任务。诸如LoRA等参数高效微调方法,利用标注的、高质量且通常稀缺的任务数据,促进大型基础模型的有效适应。为了缓解基础模型微调中的数据稀缺问题,我们建议利用多个下游用户之间的任务相似性。直观地说,具有相似任务的用户应该能够相互帮助,以提高有效的微调数据量。我们提出了协同低秩适应(CoLoRA),它利用任务相似性来协同且高效地微调个性化基础模型。CoLoRA的主要思想是训练一个共享适配器,捕获所有任务中潜在的任务相似性,以及针对用户特定任务定制的个性化适配器。我们在异构线性回归上对CoLoRA进行了理论研究,并为真值恢复提供了可证明的保证。我们还进行了几个具有不同任务相似性的自然语言实验,进一步证明了当与类似任务一起训练时,个体性能会得到显着提升。
🔬 方法详解
问题定义:论文旨在解决大型预训练模型在下游任务微调时面临的数据稀缺问题。现有的参数高效微调方法,如LoRA,虽然降低了计算成本,但仍然依赖于高质量的标注数据。当数据量不足时,模型的泛化能力会受到限制,尤其是在任务之间存在一定相似性的情况下,无法有效利用这些相似性来提升性能。
核心思路:CoLoRA的核心思路是利用任务之间的相似性,通过协同训练的方式来增强模型的泛化能力。它假设具有相似任务的用户可以相互帮助,从而有效地增加微调数据量。通过学习一个共享适配器来捕获任务间的共性,并为每个任务学习一个个性化的适配器来适应任务的独特性。
技术框架:CoLoRA包含两个主要模块:共享适配器和个性化适配器。共享适配器旨在学习所有任务共有的特征表示,而个性化适配器则用于捕捉特定任务的独有信息。在训练过程中,所有任务共享同一个共享适配器,但每个任务都有自己的个性化适配器。模型的整体训练目标是最小化所有任务的损失函数之和,同时考虑共享适配器和个性化适配器的正则化项。
关键创新:CoLoRA的关键创新在于它能够显式地建模任务之间的相似性,并将其融入到微调过程中。与传统的微调方法相比,CoLoRA能够更好地利用任务之间的信息,从而提高模型的泛化能力。此外,CoLoRA采用参数高效的方式,避免了对整个模型进行微调,从而降低了计算成本。
关键设计:CoLoRA的关键设计包括共享适配器和个性化适配器的结构选择、损失函数的设计以及正则化项的选择。适配器通常采用低秩矩阵分解的方式来实现参数高效性。损失函数通常是交叉熵损失或均方误差损失,具体取决于任务类型。正则化项用于防止过拟合,并鼓励共享适配器学习到更通用的特征表示。具体参数设置需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
论文通过自然语言实验验证了CoLoRA的有效性。实验结果表明,当与相似任务一起训练时,CoLoRA能够显著提升个体任务的性能。具体的性能提升幅度取决于任务之间的相似程度,相似度越高,性能提升越明显。此外,论文还提供了异构线性回归的理论分析,为CoLoRA的有效性提供了理论支持。
🎯 应用场景
CoLoRA适用于各种需要对大型预训练模型进行个性化微调的场景,例如自然语言处理中的文本分类、情感分析、机器翻译等。在实际应用中,可以利用CoLoRA为不同用户或组织定制个性化的模型,同时利用任务之间的相似性来提高模型的性能和泛化能力。该方法在数据隐私保护方面也具有潜力,因为用户可以共享模型参数而非原始数据。
📄 摘要(原文)
Adaptability has been regarded as a central feature in the foundation models, enabling them to effectively acclimate to unseen downstream tasks. Parameter-efficient fine-tuning methods such as celebrated LoRA facilitate efficient adaptation of large foundation models using labeled, high-quality and generally scarce task data. To mitigate data scarcity in fine-tuning of foundation models, we propose to leverage task similarity across multiple downstream users. Intuitively, users with similar tasks must be able to assist each other in boosting the effective fine-tuning data size. We propose Collaborative Low-Rank Adaptation, or CoLoRA, which exploits task similarity to collaboratively and efficiently fine-tune personalized foundation models. The main idea in CoLoRA is to train one shared adapter capturing underlying task similarities across all tasks, and personalized adapters tailored to user-specific tasks. We theoretically study CoLoRA on heterogeneous linear regression and provide provable guarantees for ground truth recovery. We also conduct several natural language experiments with varying task similarity, which further demonstrate that when trained together with similar tasks, individual performances are significantly boosted.