Risk-Sensitive Exponential Actor Critic
作者: Alonso Granados, Jason Pacheco
分类: cs.LG
发布日期: 2026-02-06
备注: To appear at AAAI 2026
💡 一句话要点
提出风险敏感指数Actor-Critic算法,解决强化学习中风险规避策略学习的数值不稳定问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 风险敏感强化学习 Actor-Critic算法 策略梯度 熵风险度量 数值稳定性 深度强化学习 off-policy学习
📋 核心要点
- 现有风险敏感强化学习方法在优化熵风险度量时,面临高方差和数值不稳定的问题,限制了其在复杂任务中的应用。
- 论文提出风险敏感指数Actor-Critic算法(rsEAC),避免显式表示指数价值函数及其梯度,从而优化策略。
- 实验表明,rsEAC在MuJoCo连续控制任务中,能够更稳定地学习风险敏感策略,优于现有方法。
📝 摘要(中文)
无模型的深度强化学习(RL)算法在一系列具有挑战性的任务中取得了巨大的成功。然而,当这些方法部署在实际应用中时,安全问题仍然存在,因此需要具有风险意识的智能体。一种用于学习这种风险意识智能体的常用效用函数是熵风险度量,但目前优化这种度量的策略梯度方法必须执行高方差和数值不稳定的更新。因此,现有的风险敏感型无模型方法仅限于简单的任务和表格设置。在本文中,我们为熵风险度量上的策略梯度方法提供了全面的理论依据,包括随机和确定性策略设置下的on-policy和off-policy梯度定理。受理论的启发,我们提出了一种风险敏感型指数Actor-Critic算法(rsEAC),这是一种off-policy无模型方法,它结合了新颖的程序来避免指数价值函数及其梯度的显式表示,并优化其策略w.r.t.熵风险度量。我们表明,与现有方法相比,rsEAC产生更数值稳定的更新,并且能够在MuJoCo中具有挑战性的风险变体连续任务中可靠地学习风险敏感型策略。
🔬 方法详解
问题定义:论文旨在解决深度强化学习中,智能体在面对具有风险的环境时,如何学习风险规避策略的问题。现有基于熵风险度量的策略梯度方法,由于需要计算指数价值函数及其梯度,导致更新过程方差大、数值不稳定,难以应用于复杂连续控制任务。
核心思路:rsEAC的核心思路是通过避免显式地计算和表示指数价值函数及其梯度,来降低更新的方差和提高数值稳定性。具体来说,它利用了一种隐式的更新方式,直接优化策略,而无需显式地估计风险价值函数。
技术框架:rsEAC是一种off-policy的Actor-Critic算法。整体框架包括:一个Actor网络,用于生成策略;一个Critic网络,用于评估策略的价值。算法使用off-policy数据进行学习,并通过一种新颖的更新规则来优化Actor和Critic网络,从而学习风险敏感的策略。
关键创新:rsEAC的关键创新在于其避免了对指数价值函数及其梯度的显式计算。这通过一种特殊的策略梯度估计方法实现,该方法直接利用采样数据来更新策略,而无需显式地计算风险价值函数。这种隐式更新方式显著降低了更新的方差,提高了数值稳定性。
关键设计:rsEAC的关键设计包括:1) 使用指数效用函数作为风险度量;2) 设计了一种新的策略梯度估计方法,避免显式计算指数价值函数及其梯度;3) 使用off-policy数据进行学习,提高样本效率;4) Actor和Critic网络可以使用常见的深度神经网络结构,如多层感知机或循环神经网络。
🖼️ 关键图片
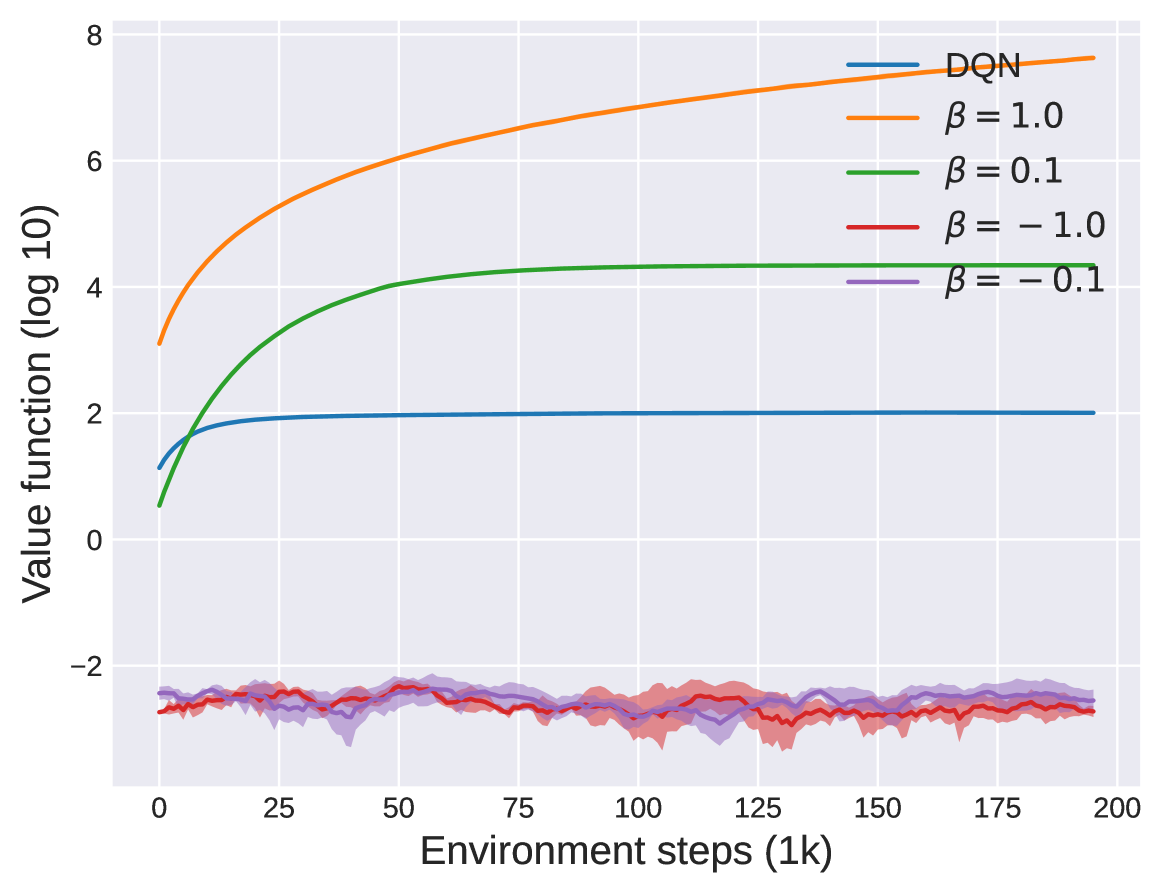
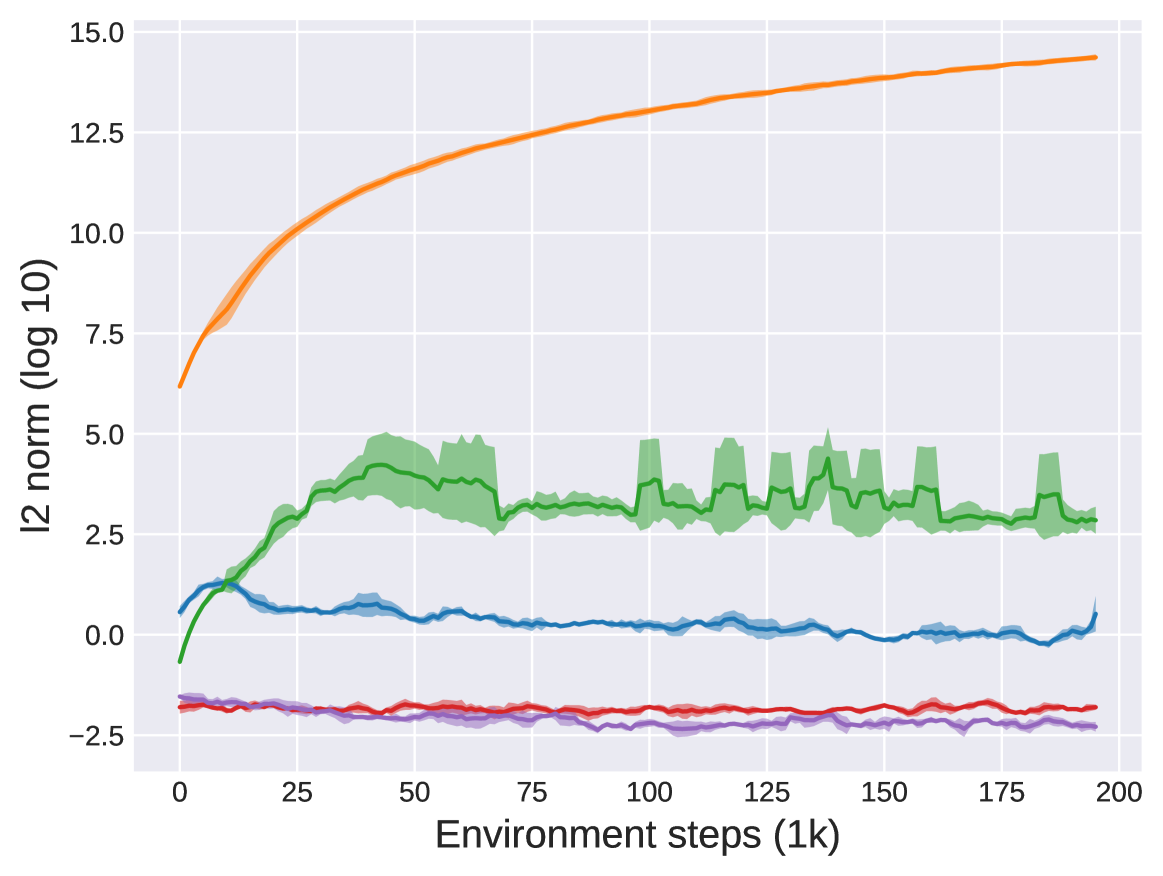
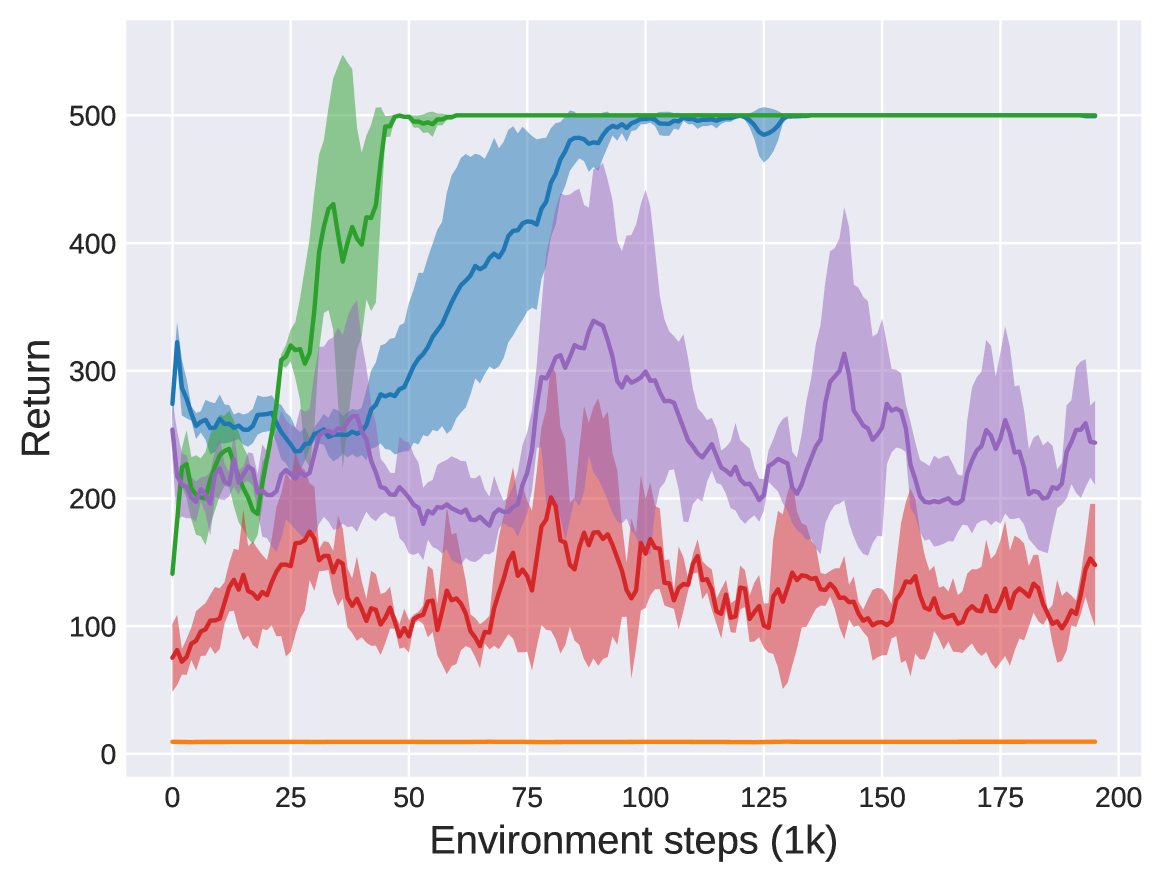
📊 实验亮点
实验结果表明,rsEAC算法在MuJoCo连续控制任务的风险变体中,能够显著优于现有的风险敏感强化学习算法。具体来说,rsEAC能够更稳定地学习到风险规避策略,并且在某些任务中取得了更高的平均回报。与基线方法相比,rsEAC的性能提升幅度明显,验证了其在风险敏感策略学习方面的有效性。
🎯 应用场景
该研究成果可应用于对安全性要求高的实际场景,例如自动驾驶、机器人操作、金融交易等。在这些场景中,智能体需要能够有效地规避风险,避免潜在的损失或危险。rsEAC算法提供了一种更稳定、更可靠的风险敏感策略学习方法,有助于提升智能体在这些场景中的表现。
📄 摘要(原文)
Model-free deep reinforcement learning (RL) algorithms have achieved tremendous success on a range of challenging tasks. However, safety concerns remain when these methods are deployed on real-world applications, necessitating risk-aware agents. A common utility for learning such risk-aware agents is the entropic risk measure, but current policy gradient methods optimizing this measure must perform high-variance and numerically unstable updates. As a result, existing risk-sensitive model-free approaches are limited to simple tasks and tabular settings. In this paper, we provide a comprehensive theoretical justification for policy gradient methods on the entropic risk measure, including on- and off-policy gradient theorems for the stochastic and deterministic policy settings. Motivated by theory, we propose risk-sensitive exponential actor-critic (rsEAC), an off-policy model-free approach that incorporates novel procedures to avoid the explicit representation of exponential value functions and their gradients, and optimizes its policy w.r.t the entropic risk measure. We show that rsEAC produces more numerically stable updates compared to existing approaches and reliably learns risk-sensitive policies in challenging risky variants of continuous tasks in MuJoCo.