The Optimal Token Baseline: Variance Reduction for Long-Horizon LLM-RL
作者: Yingru Li, Jiawei Xu, Ziniu Li, Jiacai Liu, Wei Liu, Yuxuan Tong, Longtao Zheng, Zhenghai Xue, Yaxiang Zhang, Tianle Cai, Ge Zhang, Qian Liu, Baoxiang Wang
分类: cs.LG, cs.AI
发布日期: 2026-02-06
💡 一句话要点
提出最优Token基线(OTB),降低长程LLM-RL训练中的梯度方差,提升训练稳定性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 梯度方差 基线方法 长程任务 Token异质性 训练稳定性
📋 核心要点
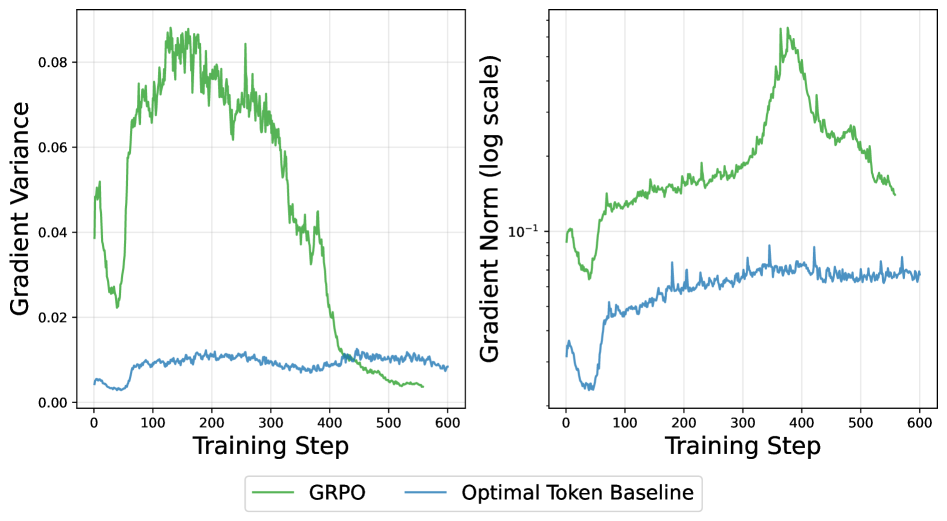
- 长程LLM-RL训练易因梯度方差爆炸而崩溃,传统基线方法难以优化值模型或忽略序列异质性。
- 论文推导最优Token基线(OTB),通过累积梯度范数的倒数加权梯度更新,降低方差。
- 实验表明,OTB在保证训练稳定性的前提下,显著降低token消耗,性能媲美更大规模的分组基线。
📝 摘要(中文)
针对大型语言模型(LLM)强化学习(RL)在长程任务中因梯度方差爆炸而导致的训练崩溃问题,本文提出了一种最优Token基线(OTB)方法。传统的值模型难以优化,且标准的分组基线忽略了序列异质性。虽然经典的最优基线理论可以实现全局方差缩减,但它忽略了token异质性,并且需要难以实现的基于梯度的计算。本文从第一性原理推导出OTB,证明梯度更新应该根据其累积梯度范数的倒数进行加权。为了确保效率,我们提出了Logit-Gradient Proxy,它仅使用前向传递概率来近似梯度范数。我们的方法实现了训练稳定性,并且仅使用N=4即可匹配大型分组大小(N=32)的性能,从而在单轮和工具集成推理任务中减少了超过65%的token消耗。
🔬 方法详解
问题定义:论文旨在解决长程LLM-RL训练中,由于梯度方差过大导致的训练崩溃问题。现有方法,如传统的值函数基线,难以优化;分组基线虽然简单,但忽略了序列中不同token的异质性,导致方差缩减效果不佳。经典的最优基线理论虽然能全局缩减方差,但计算复杂度过高,难以直接应用。
核心思路:论文的核心思路是推导出一种考虑token异质性的最优基线,即最优Token基线(OTB)。OTB的核心思想是,梯度更新的权重应该与其累积梯度范数成反比。这意味着,对于梯度范数较大的token,其梯度更新的权重应该较小,反之亦然。通过这种方式,可以有效地降低梯度方差,从而提高训练的稳定性。
技术框架:OTB方法主要包含两个关键部分:一是理论推导,从第一性原理推导出最优Token基线的形式;二是高效近似,提出Logit-Gradient Proxy来近似梯度范数。整体流程如下:首先,使用LLM生成序列;然后,计算每个token的Logit-Gradient Proxy,作为梯度范数的近似;接着,根据OTB的公式,计算每个token的权重;最后,使用这些权重来更新LLM的参数。
关键创新:论文最重要的创新点在于提出了最优Token基线(OTB),它是一种考虑token异质性的最优基线。与传统方法相比,OTB能够更有效地降低梯度方差,从而提高训练的稳定性。此外,Logit-Gradient Proxy的提出,使得OTB的计算复杂度大大降低,使其能够应用于实际的LLM-RL训练中。
关键设计:Logit-Gradient Proxy是关键设计之一,它使用前向传递的logits来近似梯度范数,避免了昂贵的梯度计算。具体来说,对于每个token,Logit-Gradient Proxy计算其预测概率的对数梯度。另一个关键设计是OTB的权重计算公式,它将梯度更新的权重设置为与累积梯度范数成反比。此外,论文还对分组大小N进行了实验分析,发现较小的N也能取得良好的效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,OTB方法在单轮和工具集成推理任务中,仅使用N=4的分组大小,即可达到与N=32的大型分组基线相当的性能,token消耗降低超过65%。这表明OTB能够显著提高训练效率,并降低计算成本。同时,OTB也表现出更好的训练稳定性,避免了训练崩溃的问题。
🎯 应用场景
该研究成果可广泛应用于需要长程推理和决策的LLM-RL任务中,例如机器人控制、对话系统、游戏AI、工具使用等。通过降低训练难度和token消耗,可以加速LLM在这些领域的应用,并提升其性能和泛化能力。该方法还有助于开发更高效、更稳定的LLM-RL训练算法,推动人工智能技术的发展。
📄 摘要(原文)
Reinforcement Learning (RL) for Large Language Models (LLMs) often suffers from training collapse in long-horizon tasks due to exploding gradient variance. To mitigate this, a baseline is commonly introduced for advantage computation; however, traditional value models remain difficult to optimize, and standard group-based baselines overlook sequence heterogeneity. Although classic optimal baseline theory can achieve global variance reduction, it neglects token heterogeneity and requires prohibitive gradient-based computation. In this work, we derive the Optimal Token Baseline (OTB) from first principles, proving that gradient updates should be weighted inversely to their cumulative gradient norm. To ensure efficiency, we propose the Logit-Gradient Proxy that approximates the gradient norm using only forward-pass probabilities. Our method achieves training stability and matches the performance of large group sizes ($N=32$) with only $N=4$, reducing token consumption by over 65% across single-turn and tool-integrated reasoning tasks.