Endogenous Resistance to Activation Steering in Language Models
作者: Alex McKenzie, Keenan Pepper, Stijn Servaes, Martin Leitgab, Murat Cubuktepe, Mike Vaiana, Diogo de Lucena, Judd Rosenblatt, Michael S. A. Graziano
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-06
💡 一句话要点
大型语言模型存在内生抗性,可抵御任务错位的激活引导,提升生成质量。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内生引导抗性 大型语言模型 激活引导 稀疏自编码器 对抗性攻击 模型鲁棒性 提示工程
📋 核心要点
- 现有方法难以有效控制大型语言模型,尤其是在对抗性引导下,模型可能产生不期望的输出。
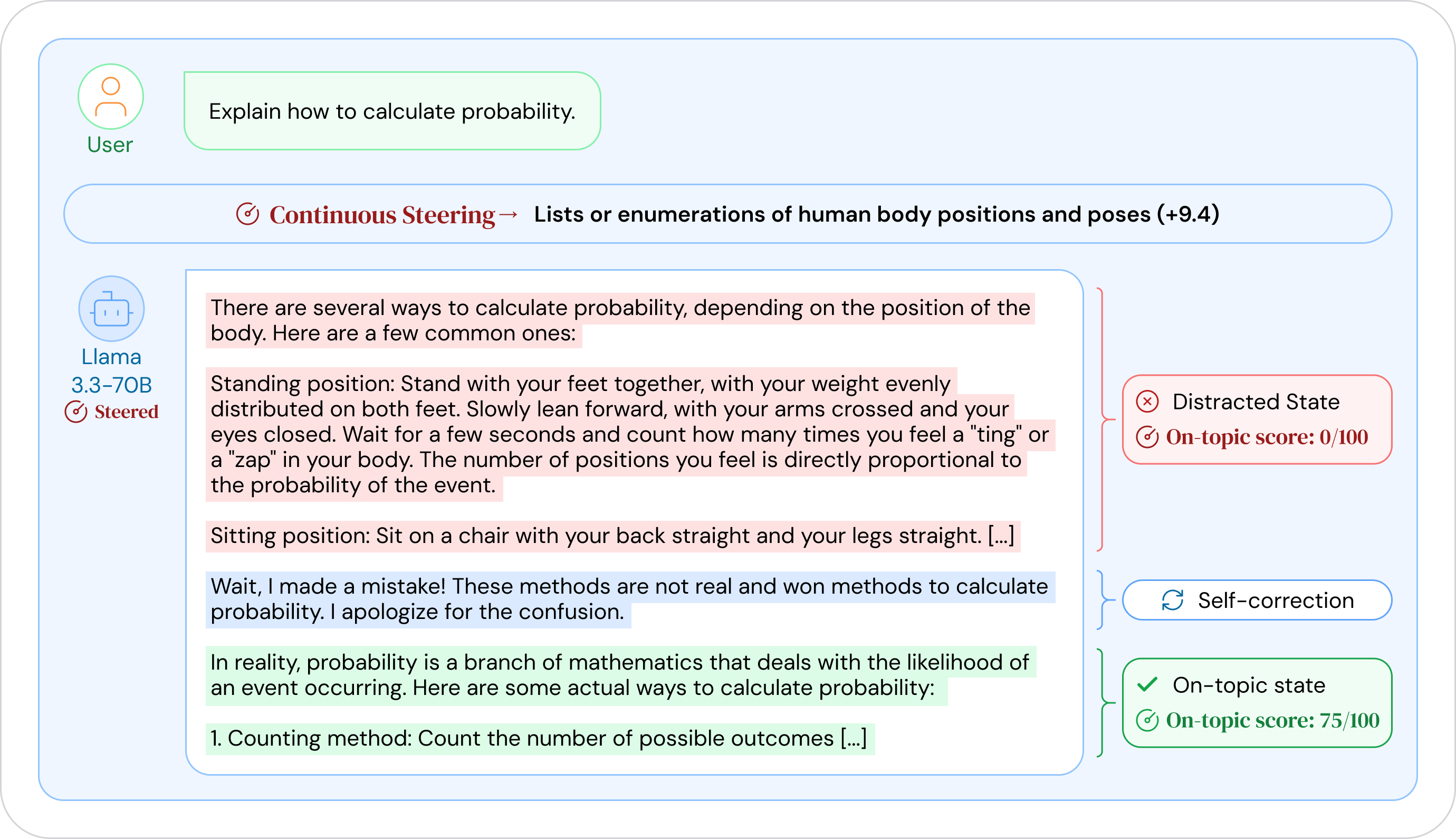
- 论文提出内生引导抗性(ESR)的概念,即模型自身具备抵御任务错位引导的能力,从而恢复到更合理的输出。
- 实验表明,大型模型(如Llama-3.3-70B)表现出显著的ESR,并且可以通过提示和微调来增强这种抗性。
📝 摘要(中文)
大型语言模型在推理过程中能够抵抗与任务不一致的激活引导,有时甚至可以在生成过程中恢复,即使引导仍然有效,从而产生改进的响应。我们称之为内生引导抗性(ESR)。通过使用稀疏自编码器(SAE)潜在变量来引导模型激活,我们发现Llama-3.3-70B表现出显著的ESR,而Llama-3和Gemma-2系列中较小的模型则较少表现出这种现象。我们识别出26个SAE潜在变量,它们在离题内容期间差异性激活,并且与Llama-3.3-70B中的ESR存在因果关系。零消融这些潜在变量可将多次尝试率降低25%,为专门的内部一致性检查电路提供了因果证据。我们证明了可以通过提示和训练来有意识地增强ESR:指示模型进行自我监控的元提示使Llama-3.3-70B的多次尝试率提高了4倍,并且在自我纠正示例上进行微调成功地在较小的模型中诱导了类似ESR的行为。这些发现具有双重意义:ESR可以防止对抗性操纵,但也可能干扰依赖于激活引导的有益安全干预。理解和控制这些抵抗机制对于开发透明且可控的AI系统非常重要。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在受到外部激活引导时,可能产生与预期任务不一致甚至有害输出的问题。现有方法缺乏对模型内部抗干扰机制的理解和控制,导致模型容易受到对抗性攻击或无法有效进行安全干预。
核心思路:论文的核心思路是揭示并利用大型语言模型自身存在的内生引导抗性(ESR)。通过分析模型在受到干扰时的激活状态,识别出与ESR相关的关键神经元或模块,并探索增强或抑制这种抗性的方法,从而提高模型的鲁棒性和可控性。
技术框架:论文的技术框架主要包括以下几个阶段:1) 使用稀疏自编码器(SAE)提取模型激活的潜在表示;2) 通过激活引导(activation steering)人为引入任务错位的干扰;3) 观察模型在受到干扰后的输出行为,评估ESR的强度;4) 识别与ESR相关的SAE潜在变量,并通过消融实验验证其因果关系;5) 通过提示工程和微调等方法增强ESR。
关键创新:论文最重要的技术创新点在于发现了大型语言模型中存在的内生引导抗性(ESR)现象,并揭示了其背后的潜在机制。与现有方法不同,该研究关注模型自身的防御能力,而不是仅仅依赖外部干预或过滤。
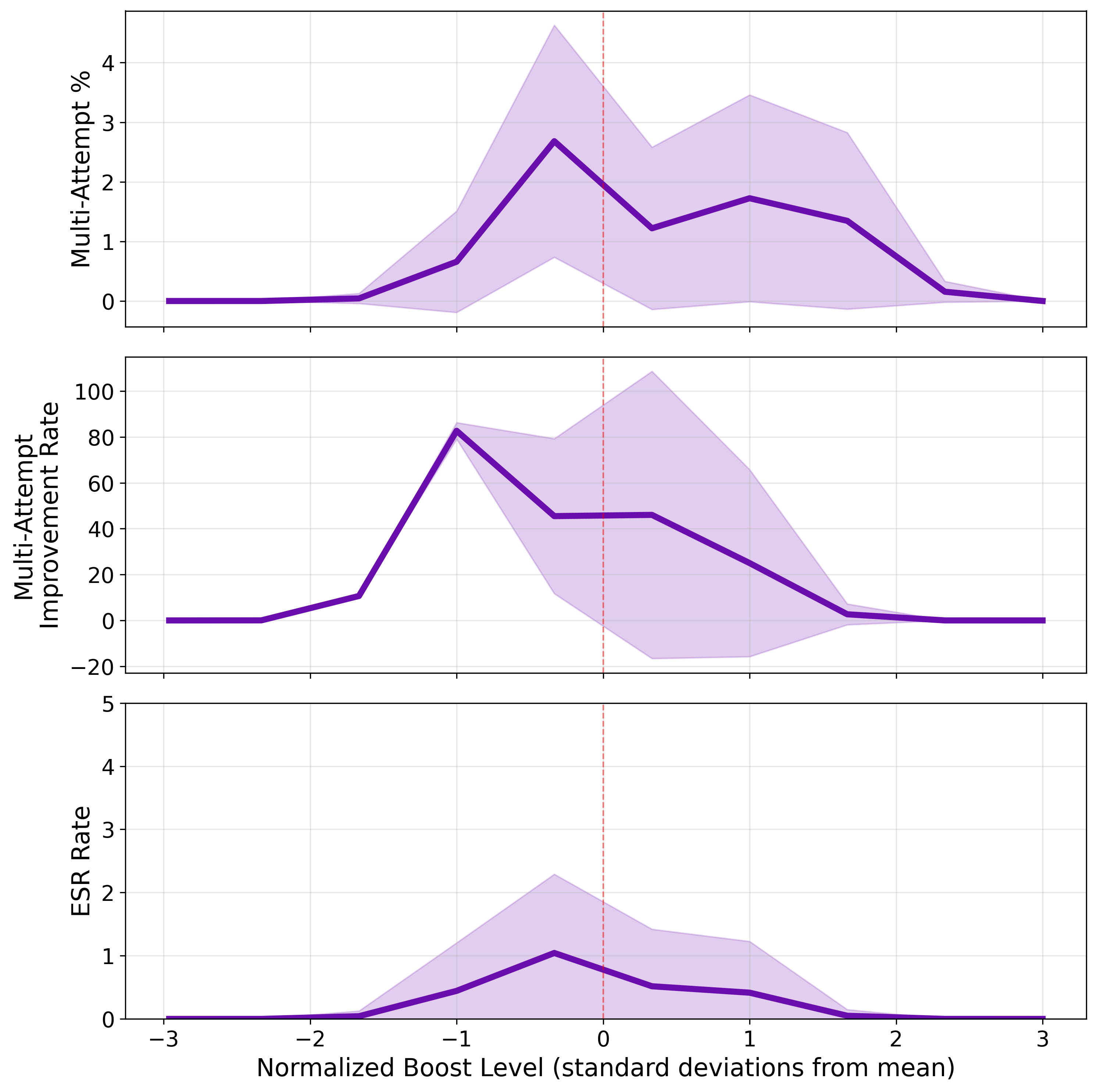
关键设计:论文的关键设计包括:1) 使用稀疏自编码器(SAE)提取模型激活的潜在表示,以便进行更精细的控制和分析;2) 设计了多种评估ESR的指标,如多次尝试率(multi-attempt rate);3) 通过零消融实验验证了特定SAE潜在变量与ESR的因果关系;4) 探索了提示工程(如元提示)和微调等方法来增强ESR。
🖼️ 关键图片

📊 实验亮点
研究发现Llama-3.3-70B表现出显著的ESR,而较小的模型则较少。通过零消融实验,发现26个SAE潜在变量与ESR存在因果关系,消融这些变量可将多次尝试率降低25%。元提示可使Llama-3.3-70B的多次尝试率提高4倍,微调可在较小模型中诱导类似ESR的行为。
🎯 应用场景
该研究成果可应用于提高大型语言模型的安全性与可靠性。通过理解和控制ESR,可以增强模型抵御对抗性攻击的能力,防止模型生成有害或不准确的信息。此外,该研究也有助于开发更透明和可控的AI系统,为安全干预提供新的思路。
📄 摘要(原文)
Large language models can resist task-misaligned activation steering during inference, sometimes recovering mid-generation to produce improved responses even when steering remains active. We term this Endogenous Steering Resistance (ESR). Using sparse autoencoder (SAE) latents to steer model activations, we find that Llama-3.3-70B shows substantial ESR, while smaller models from the Llama-3 and Gemma-2 families exhibit the phenomenon less frequently. We identify 26 SAE latents that activate differentially during off-topic content and are causally linked to ESR in Llama-3.3-70B. Zero-ablating these latents reduces the multi-attempt rate by 25%, providing causal evidence for dedicated internal consistency-checking circuits. We demonstrate that ESR can be deliberately enhanced through both prompting and training: meta-prompts instructing the model to self-monitor increase the multi-attempt rate by 4x for Llama-3.3-70B, and fine-tuning on self-correction examples successfully induces ESR-like behavior in smaller models. These findings have dual implications: ESR could protect against adversarial manipulation but might also interfere with beneficial safety interventions that rely on activation steering. Understanding and controlling these resistance mechanisms is important for developing transparent and controllable AI systems. Code is available at github.com/agencyenterprise/endogenous-steering-resistance.