Reciprocal Latent Fields for Precomputed Sound Propagation
作者: Hugo Seuté, Pranai Vasudev, Etienne Richan, Louis-Xavier Buffoni
分类: cs.SD, cs.LG, eess.AS
发布日期: 2026-02-06
备注: Temporary pre-print, will be updated. In review at a conference
💡 一句话要点
提出互易潜在场(RLF),用于预计算声传播,显著降低内存占用。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 声传播 预计算 互易性 潜在空间 黎曼度量学习
📋 核心要点
- 现有波编码方法在大型环境中预计算声学参数时,面临着内存占用过大的挑战,限制了实时应用。
- 论文提出互易潜在场(RLF),利用可训练的潜在嵌入和对称解码函数,在保证声学互易性的前提下,实现高效的声学参数编码。
- 实验结果表明,RLF在显著降低内存占用的同时,保持了声音渲染的质量,主观听力测试表明其效果与ground-truth模拟相当。
📝 摘要(中文)
逼真的声音传播对于虚拟场景的沉浸感至关重要,但物理上精确的基于波的模拟在计算上对于实时应用来说仍然过于昂贵。波编码方法通过将给定场景的脉冲响应预计算并压缩成一组标量声学参数来解决这一限制,但在具有许多源-接收器对的大型环境中,这些参数可能会达到难以管理的大小。我们引入了互易潜在场(RLF),这是一种内存高效的框架,用于编码和预测这些声学参数。RLF框架采用可训练的潜在嵌入的体积网格,并使用对称函数进行解码,从而确保声学互易性。我们研究了各种解码器,并表明利用黎曼度量学习可以更好地重现复杂场景中的声学现象。实验验证表明,RLF在保持复制质量的同时,将内存占用减少了几个数量级。此外,类似MUSHRA的主观听力测试表明,通过RLF渲染的声音在感知上与ground-truth模拟无法区分。
🔬 方法详解
问题定义:论文旨在解决预计算声传播中,波编码方法在大规模场景下内存占用过大的问题。现有方法需要存储大量源-接收器对的脉冲响应,导致内存需求随着场景复杂度和源/接收器数量的增加而迅速增长,难以满足实时应用的需求。
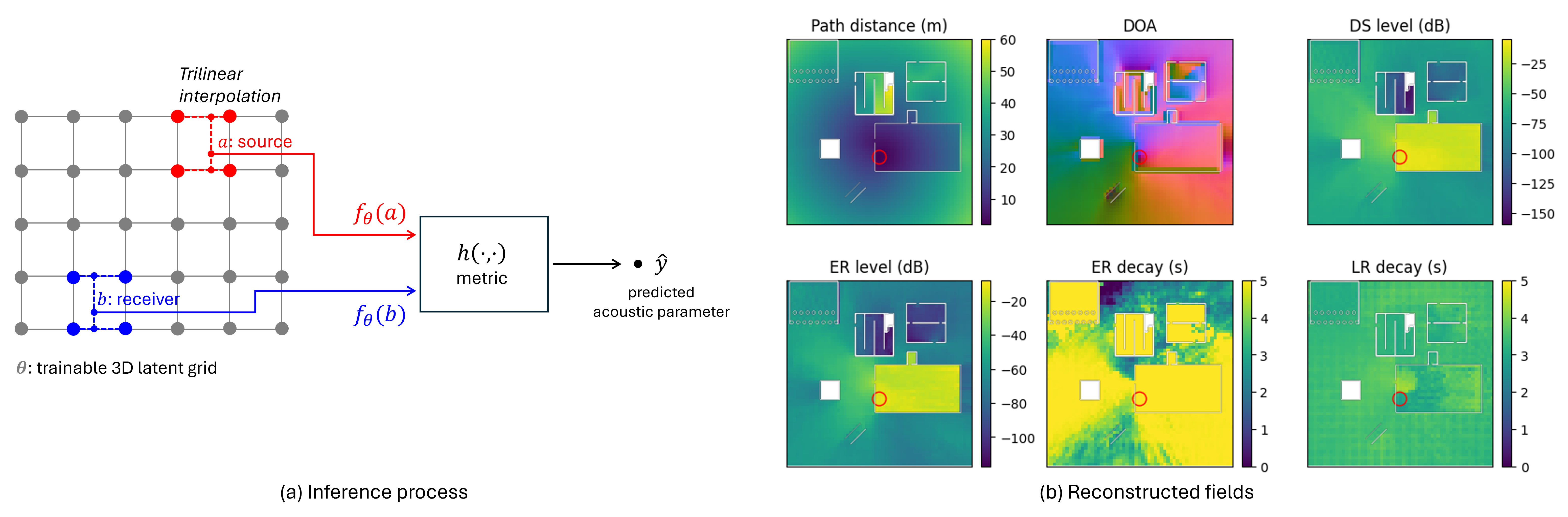
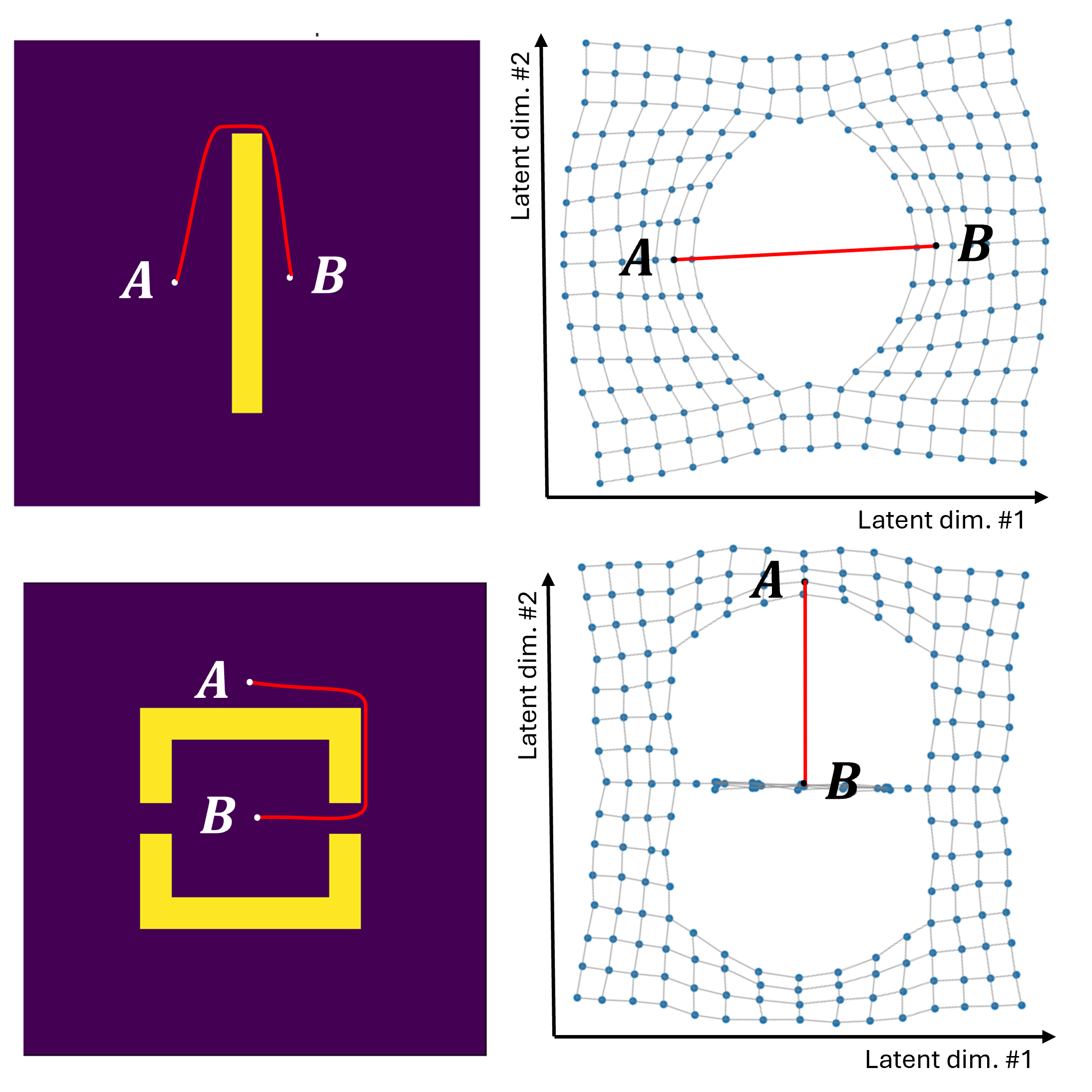
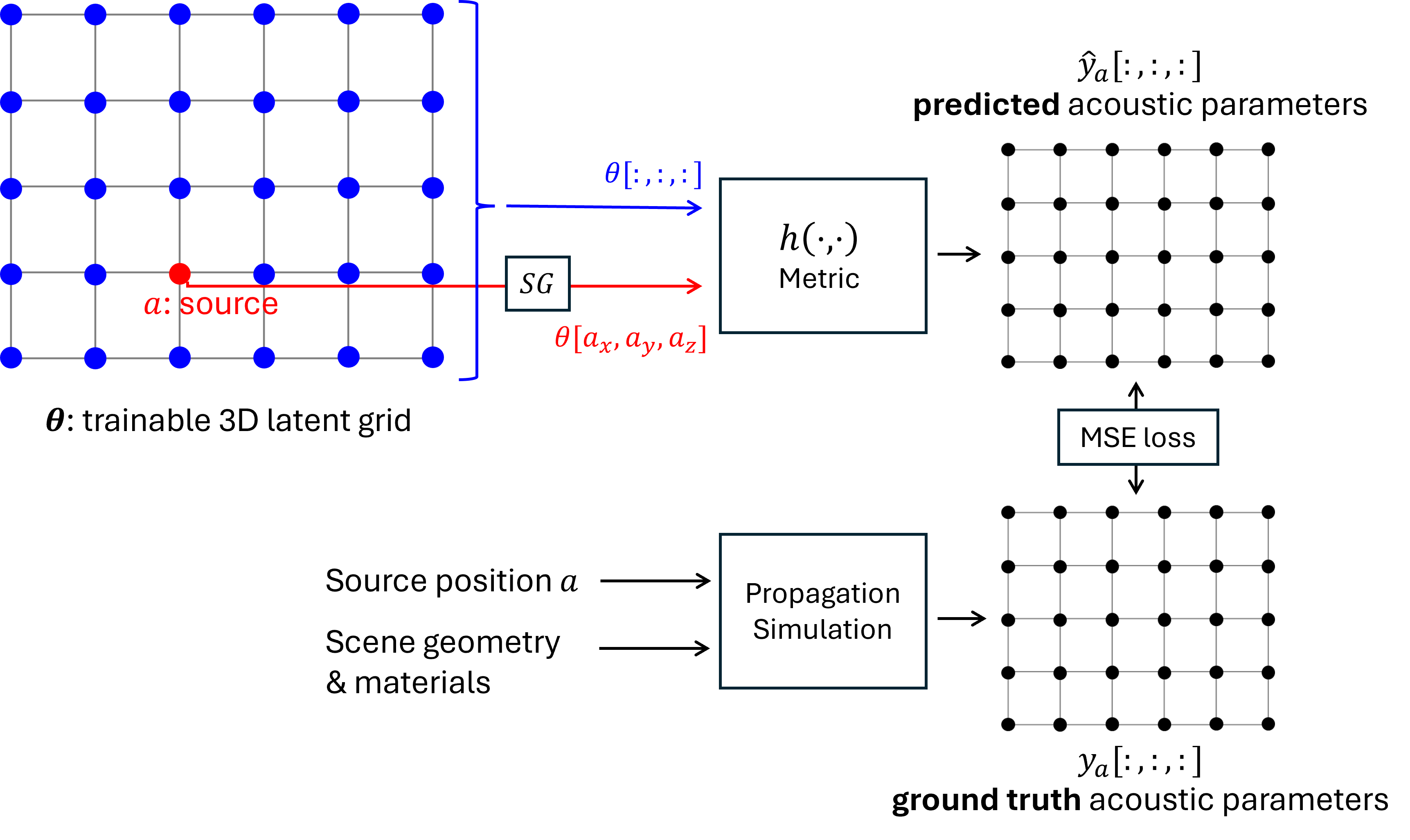
核心思路:论文的核心思路是利用低维的潜在空间来表示声学参数,并通过学习到的解码器将潜在空间映射回声学参数。关键在于设计一个能够保证声学互易性的潜在空间表示和解码器。声学互易性是指声源和接收器的位置互换后,声学参数应该保持不变。
技术框架:RLF框架包含以下主要模块:1) 潜在嵌入网格:将场景划分为一个三维网格,每个网格单元对应一个可训练的潜在嵌入向量。2) 对称解码器:接收两个位置(源和接收器)对应的潜在嵌入向量,并输出相应的声学参数。解码器被设计成对称函数,以保证声学互易性。3) 黎曼度量学习:利用黎曼度量学习来优化潜在空间,使其更好地反映声学现象。
关键创新:RLF的关键创新在于:1) 互易性保证:通过对称解码器设计,显式地保证了声学互易性,避免了后处理或约束。2) 内存效率:通过使用低维潜在空间表示声学参数,显著降低了内存占用。3) 黎曼度量学习:利用黎曼度量学习来优化潜在空间,提高了声学参数的重建质量。
关键设计:1) 解码器结构:论文研究了多种解码器结构,包括MLP、线性回归等。2) 损失函数:损失函数包括重建损失和互易性损失。重建损失用于衡量重建的声学参数与ground-truth之间的差异,互易性损失用于进一步加强互易性约束。3) 黎曼度量:论文使用黎曼度量学习来优化潜在空间,使其更好地反映声学现象。具体来说,论文学习了一个黎曼度量张量,用于衡量潜在空间中不同方向上的距离。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RLF在保持声音渲染质量的同时,将内存占用降低了几个数量级。主观听力测试(MUSHRA-like)表明,通过RLF渲染的声音在感知上与ground-truth模拟无法区分。具体而言,RLF在复杂场景中实现了与ground-truth相当的声学效果,同时内存占用仅为传统方法的1/100甚至更低。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实、游戏开发等领域,为用户提供更具沉浸感和真实感的声音体验。通过降低声传播计算的内存需求,使得在资源受限的设备上实现高质量的声渲染成为可能,例如移动VR/AR设备。未来,该技术可以进一步扩展到更复杂的声学场景,例如包含动态声源和几何体的场景。
📄 摘要(原文)
Realistic sound propagation is essential for immersion in a virtual scene, yet physically accurate wave-based simulations remain computationally prohibitive for real-time applications. Wave coding methods address this limitation by precomputing and compressing impulse responses of a given scene into a set of scalar acoustic parameters, which can reach unmanageable sizes in large environments with many source-receiver pairs. We introduce Reciprocal Latent Fields (RLF), a memory-efficient framework for encoding and predicting these acoustic parameters. The RLF framework employs a volumetric grid of trainable latent embeddings decoded with a symmetric function, ensuring acoustic reciprocity. We study a variety of decoders and show that leveraging Riemannian metric learning leads to a better reproduction of acoustic phenomena in complex scenes. Experimental validation demonstrates that RLF maintains replication quality while reducing the memory footprint by several orders of magnitude. Furthermore, a MUSHRA-like subjective listening test indicates that sound rendered via RLF is perceptually indistinguishable from ground-truth simulations.