From Kepler to Newton: Inductive Biases Guide Learned World Models in Transformers
作者: Ziming Liu, Sophia Sanborn, Surya Ganguli, Andreas Tolias
分类: cs.LG, cs.AI, physics.class-ph
发布日期: 2026-02-06
💡 一句话要点
引入归纳偏置,Transformer可学习开普勒定律并发现牛顿力学
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 归纳偏置 Transformer 物理定律 科学发现
📋 核心要点
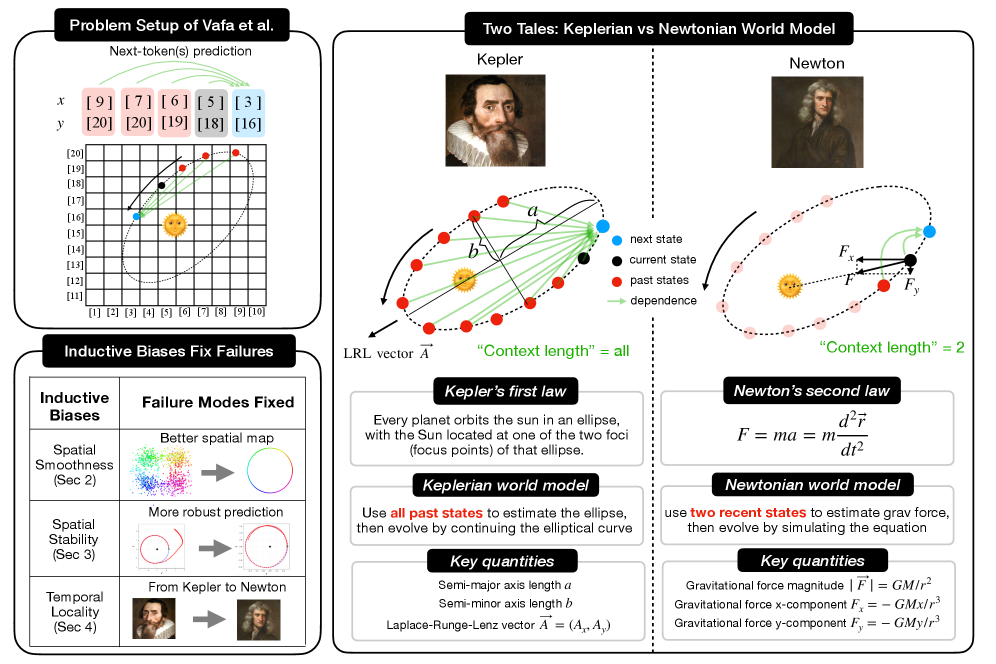
- 现有“AI物理学家”方法依赖领域先验知识,通用Transformer难以学习物理定律。
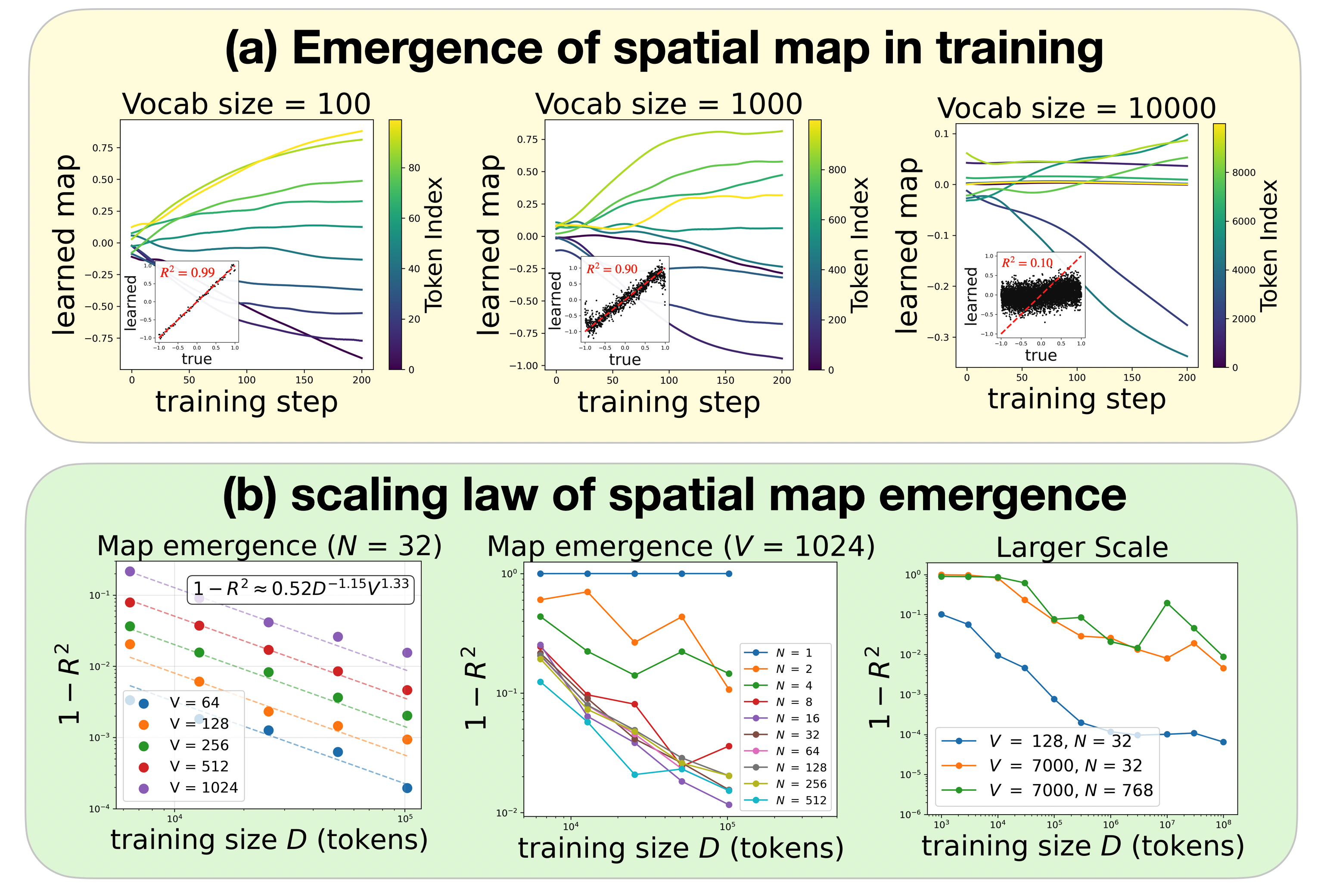
- 引入空间平滑性、稳定性和时间局部性三个归纳偏置,引导Transformer学习世界模型。
- 实验表明,引入归纳偏置的Transformer能学习开普勒定律并发现牛顿力学。
📝 摘要(中文)
通用人工智能架构能否超越预测,发现支配宇宙的物理定律?真正的智能依赖于“世界模型”,这是一种因果抽象,使智能体不仅能够预测未来状态,还能理解潜在的支配动态。虽然之前的“AI物理学家”方法成功地恢复了这些定律,但它们通常依赖于强大的、特定领域的先验知识,有效地“烘烤”了物理学。相反,Vafa等人最近表明,通用的Transformer无法获得这些世界模型,在没有捕捉到潜在物理定律的情况下实现了高预测精度。我们通过系统地引入三个最小的归纳偏置来弥合这一差距。我们表明,确保空间平滑性(通过将预测公式化为连续回归)和稳定性(通过使用噪声上下文进行训练以减轻误差累积)使通用的Transformer能够超越之前的失败,并学习一个连贯的开普勒世界模型,成功地将椭圆拟合到行星轨迹。然而,真正的物理洞察力需要第三个偏置:时间局部性。通过将注意力窗口限制在最近的过去——假设未来状态仅依赖于局部状态而不是复杂的历史——我们迫使模型放弃曲线拟合,并发现牛顿力表示。我们的结果表明,简单的架构选择决定了人工智能是成为曲线拟合器还是物理学家,这标志着朝着自动科学发现迈出的关键一步。
🔬 方法详解
问题定义:论文旨在解决通用Transformer在没有特定领域先验知识的情况下,无法学习到物理世界模型的问题。现有方法要么依赖于强先验,要么无法从数据中提取出物理定律,导致模型只能进行预测,而不能理解背后的因果关系。Transformer虽然具有强大的序列建模能力,但在学习物理规律方面表现不佳,常常沦为曲线拟合器,无法泛化到新的场景。
核心思路:论文的核心思路是通过引入最小的归纳偏置,引导Transformer学习物理世界模型。具体来说,论文提出了三个关键的归纳偏置:空间平滑性、稳定性和时间局部性。空间平滑性通过连续回归的方式,鼓励模型学习平滑的轨迹;稳定性通过噪声训练,减少误差累积;时间局部性通过限制注意力窗口,迫使模型关注局部状态,从而发现牛顿力学。
技术框架:论文使用Transformer作为基础架构,输入是行星的轨迹数据,输出是预测的未来轨迹。模型训练过程中,逐步引入三个归纳偏置。首先,将预测任务定义为连续回归,鼓励空间平滑性。其次,在训练数据中加入噪声,提高模型的鲁棒性,防止误差累积。最后,限制Transformer的注意力窗口,只关注最近的过去,强制模型学习局部依赖关系。
关键创新:论文最重要的技术创新在于系统性地引入了三个最小的归纳偏置,并证明了这些偏置对于Transformer学习物理世界模型至关重要。与以往依赖强先验的方法不同,该方法只引入了非常弱的假设,就能使Transformer从数据中学习到物理定律。此外,论文还揭示了时间局部性对于发现牛顿力学的重要性,这为未来的研究提供了新的方向。
关键设计:论文的关键设计包括:1) 使用均方误差损失函数进行连续回归;2) 在训练数据中加入高斯噪声,噪声水平根据经验选择;3) 使用滑动窗口注意力机制,限制注意力窗口的大小。注意力窗口的大小是一个重要的超参数,需要根据具体任务进行调整。论文还探索了不同的网络结构,发现更深的网络能够更好地学习物理规律。
🖼️ 关键图片

📊 实验亮点
实验结果表明,引入空间平滑性和稳定性的Transformer能够学习开普勒世界模型,成功拟合行星轨迹。进一步引入时间局部性后,模型能够发现牛顿力表示,表明模型已经理解了物理定律,而不仅仅是进行曲线拟合。与没有引入归纳偏置的Transformer相比,该方法的预测精度和泛化能力都得到了显著提升。
🎯 应用场景
该研究成果可应用于自动科学发现、机器人控制、物理仿真等领域。通过引入合适的归纳偏置,可以使AI系统更有效地学习物理世界的规律,从而实现更智能的决策和控制。例如,在机器人控制中,可以利用学习到的物理模型来预测机器人的运动轨迹,从而实现更精确的控制。在物理仿真中,可以利用学习到的物理定律来加速仿真过程,并提高仿真精度。
📄 摘要(原文)
Can general-purpose AI architectures go beyond prediction to discover the physical laws governing the universe? True intelligence relies on "world models" -- causal abstractions that allow an agent to not only predict future states but understand the underlying governing dynamics. While previous "AI Physicist" approaches have successfully recovered such laws, they typically rely on strong, domain-specific priors that effectively "bake in" the physics. Conversely, Vafa et al. recently showed that generic Transformers fail to acquire these world models, achieving high predictive accuracy without capturing the underlying physical laws. We bridge this gap by systematically introducing three minimal inductive biases. We show that ensuring spatial smoothness (by formulating prediction as continuous regression) and stability (by training with noisy contexts to mitigate error accumulation) enables generic Transformers to surpass prior failures and learn a coherent Keplerian world model, successfully fitting ellipses to planetary trajectories. However, true physical insight requires a third bias: temporal locality. By restricting the attention window to the immediate past -- imposing the simple assumption that future states depend only on the local state rather than a complex history -- we force the model to abandon curve-fitting and discover Newtonian force representations. Our results demonstrate that simple architectural choices determine whether an AI becomes a curve-fitter or a physicist, marking a critical step toward automated scientific discovery.