Revisiting the Generic Transformer: Deconstructing a Strong Baseline for Time Series Foundation Models
作者: Yunshi Wen, Wesley M. Gifford, Chandra Reddy, Lam M. Nguyen, Jayant Kalagnanam, Anak Agung Julius
分类: cs.LG
发布日期: 2026-02-06
💡 一句话要点
重新审视通用Transformer:解构时间序列基础模型的强大基线
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 Transformer 基础模型 零样本学习 消融研究
📋 核心要点
- 现有时间序列基础模型研究的训练设置不统一,难以区分性能提升来自架构设计还是数据处理。
- 本文探索了标准patch Transformer在时间序列预测中的潜力,并设计了简单的训练流程。
- 实验表明,通用Transformer架构在零样本预测中达到了SOTA性能,并具有良好的可扩展性。
📝 摘要(中文)
近年来,时间序列基础模型发展迅速,但不同研究中异构的训练设置使得难以区分改进是源于架构创新还是数据工程。本文研究了标准patch Transformer的潜力,表明这种通用架构通过直接的训练协议即可实现最先进的零样本预测性能。我们进行了一项全面的消融研究,涵盖模型缩放、数据组成和训练技术,以分离高性能的关键要素。我们的发现确定了性能的关键驱动因素,同时证实了通用架构本身表现出卓越的可扩展性。通过严格控制这些变量,我们提供了关于多维度模型缩放的全面经验结果。我们发布了我们的开源模型和详细发现,为未来的研究建立一个透明、可复现的基线。
🔬 方法详解
问题定义:论文旨在解决时间序列预测问题,特别是零样本预测。现有时间序列基础模型的研究中,训练设置的异构性使得难以确定性能提升的真正来源,即是架构创新还是数据工程的贡献。因此,需要一个清晰、可复现的基线来评估新的模型和方法。
核心思路:论文的核心思路是重新审视通用的Transformer架构,并证明通过简单的训练协议,它可以达到甚至超过当前最先进的时间序列基础模型的性能。通过控制数据、训练和模型规模等变量,来确定影响性能的关键因素。
技术框架:论文采用标准的patch Transformer架构,将时间序列数据分割成patch,然后输入到Transformer编码器中进行处理。整个框架包括数据预处理(patching)、Transformer编码器和预测头三个主要模块。数据预处理将原始时间序列数据分割成固定长度的patch,Transformer编码器学习patch之间的关系,预测头则根据编码器的输出进行预测。
关键创新:论文的关键创新在于证明了通用Transformer架构在时间序列预测中的强大潜力,并提供了一个透明、可复现的基线。通过严格的消融研究,确定了影响性能的关键因素,例如模型规模、数据组成和训练技术。这与以往专注于复杂架构设计的论文形成对比。
关键设计:论文的关键设计包括:1) 使用标准的patch Transformer架构,避免引入复杂的定制化模块;2) 设计了简单的训练协议,包括数据增强和优化策略;3) 进行了全面的消融研究,系统地评估了不同因素对性能的影响。具体的参数设置和损失函数等细节在论文中有详细描述,例如使用了标准的Adam优化器和均方误差损失函数。
🖼️ 关键图片

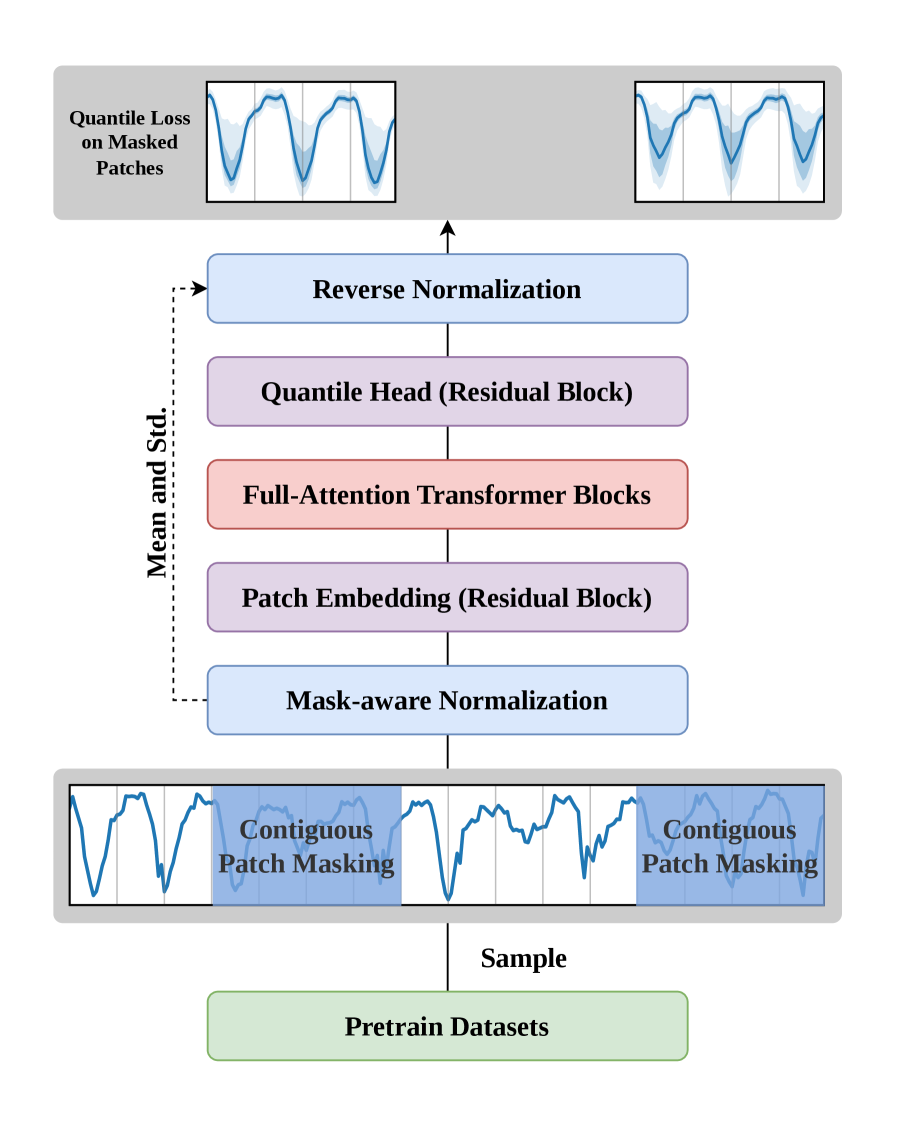
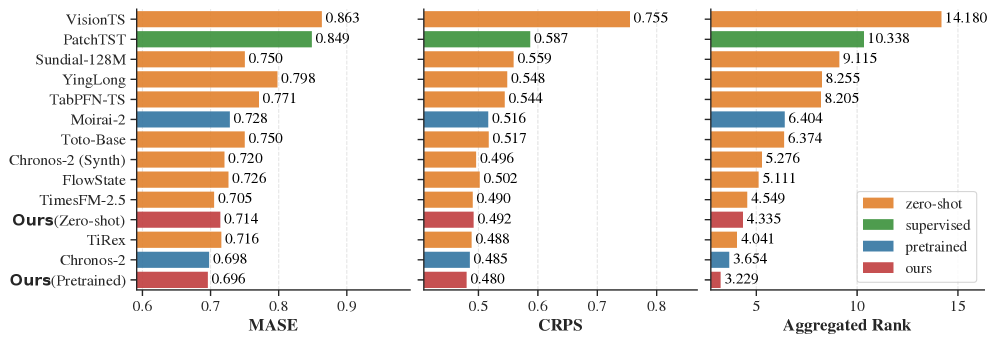
📊 实验亮点
实验结果表明,通用的patch Transformer架构在零样本时间序列预测任务中取得了最先进的性能。通过消融研究,论文确定了模型规模、数据组成和训练技术是影响性能的关键因素。该研究还提供了关于模型缩放的全面经验结果,并发布了开源模型和详细发现,为未来的研究建立了一个透明、可复现的基线。
🎯 应用场景
该研究成果可应用于各种时间序列预测场景,例如金融市场预测、能源需求预测、供应链管理和医疗健康监测等。通过提供一个强大的基线模型和清晰的性能影响因素分析,可以加速时间序列预测领域的研究进展,并为实际应用提供更可靠的解决方案。未来的研究可以基于此基线进行改进和扩展,探索更有效的模型架构和训练方法。
📄 摘要(原文)
The recent surge in Time Series Foundation Models has rapidly advanced the field, yet the heterogeneous training setups across studies make it difficult to attribute improvements to architectural innovations versus data engineering. In this work, we investigate the potential of a standard patch Transformer, demonstrating that this generic architecture achieves state-of-the-art zero-shot forecasting performance using a straightforward training protocol. We conduct a comprehensive ablation study that covers model scaling, data composition, and training techniques to isolate the essential ingredients for high performance. Our findings identify the key drivers of performance, while confirming that the generic architecture itself demonstrates excellent scalability. By strictly controlling these variables, we provide comprehensive empirical results on model scaling across multiple dimensions. We release our open-source model and detailed findings to establish a transparent, reproducible baseline for future research.