On the Non-Identifiability of Steering Vectors in Large Language Models
作者: Sohan Venkatesh, Ashish Mahendran Kurapath
分类: cs.LG, cs.AI
发布日期: 2026-02-06 (更新: 2026-02-16)
备注: 17 pages, 7 figures, 4 tables
💡 一句话要点
揭示大语言模型Steering Vector的非唯一性,挑战现有可解释性方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可解释性 Steering向量 非唯一性 激活干预
📋 核心要点
- 现有激活Steering方法假设Steering向量可唯一确定,但该假设缺乏理论支撑,可能导致对LLM内部表示的误解。
- 该研究证明Steering向量本质上是非唯一可识别的,存在大量行为上无法区分的干预措施,挑战了现有可解释性方法。
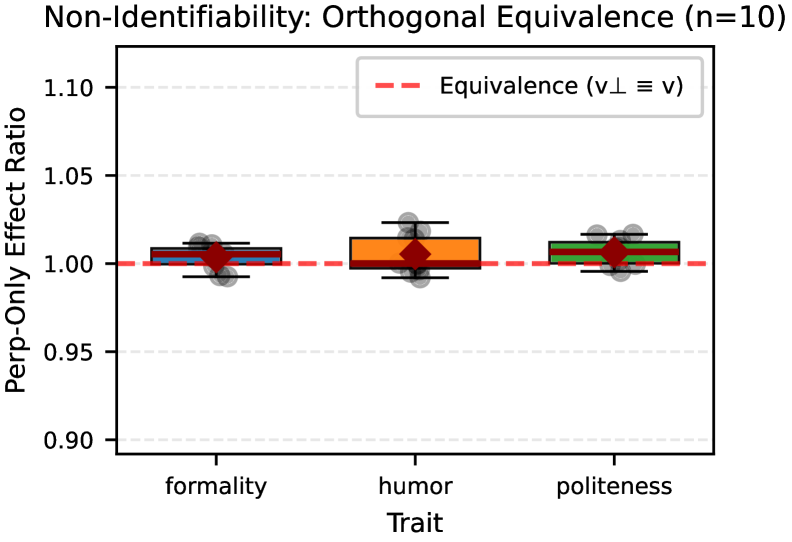
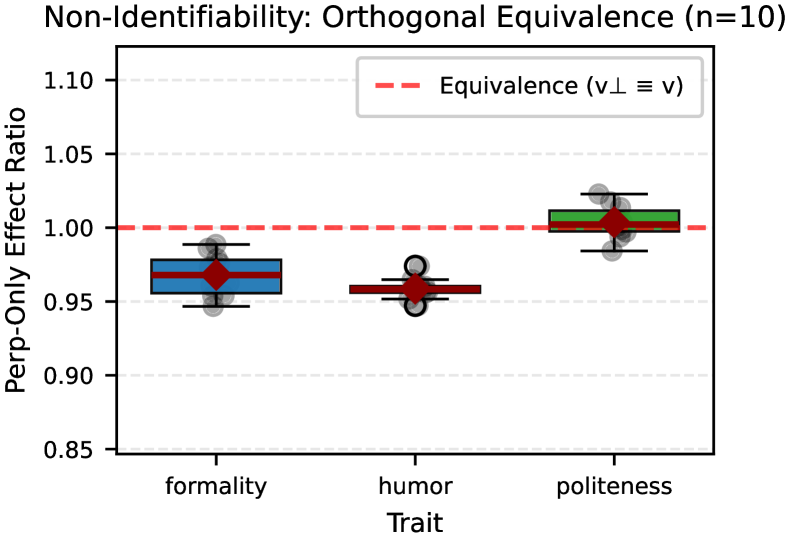
- 实验表明,正交扰动对Steering效果影响甚微,证明了非唯一性是稳健的几何属性,在不同prompt分布下依然成立。
📝 摘要(中文)
激活Steering方法被广泛用于控制大语言模型(LLM)的行为,并常被解释为揭示了有意义的内部表示。这种解释假设Steering方向是可识别的,并且可以从输入-输出行为中唯一恢复。本文表明,在白盒单层访问下,由于行为上无法区分的干预措施存在大量等价类,Steering向量从根本上是不可识别的。实证结果表明,正交扰动实现了近乎等效的效力,并且在多个模型和特征上的效应量可以忽略不计。重要的是,本文表明,非识别性是一种稳健的几何属性,它在不同的prompt分布中持续存在。这些发现揭示了基本的可解释性限制,并强调需要超出行为测试的结构约束,以实现可靠的对齐干预。
🔬 方法详解
问题定义:现有激活Steering方法旨在通过调整LLM内部激活向量的方向来控制其行为。一个关键假设是,这些Steering向量是可唯一识别的,即特定的行为改变对应于唯一的内部表示调整。然而,这个假设缺乏严格的理论验证,并且可能导致对LLM内部工作机制的错误理解。现有方法主要依赖于输入-输出行为来推断内部表示,忽略了可能存在多种内部干预产生相同外部行为的情况。
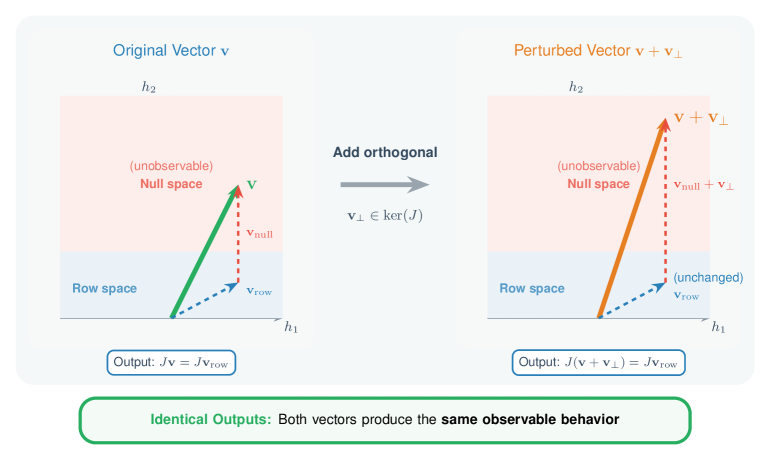
核心思路:本文的核心思路是证明Steering向量的非唯一可识别性。具体来说,即使在可以完全访问模型内部状态(白盒访问)的情况下,也存在大量不同的Steering向量,它们在行为上是无法区分的。这意味着,仅仅通过观察模型的输入-输出行为,无法确定唯一的Steering方向。这种非唯一性源于LLM内部表示空间的复杂几何结构,使得不同的干预措施可能产生相同的效果。
技术框架:本文采用白盒单层访问的方式,直接干预LLM的内部激活向量。研究人员首先确定一个目标行为(例如,使模型更积极),然后尝试找到一个Steering向量,使得沿着该方向调整激活向量可以实现该目标行为。接下来,研究人员生成一系列与原始Steering向量正交的扰动向量,并评估这些扰动向量对模型行为的影响。如果这些扰动向量也能实现类似的目标行为,则表明Steering向量不是唯一可识别的。
关键创新:本文最重要的技术创新在于证明了Steering向量的非唯一可识别性。与现有方法不同,本文不仅关注于找到一个Steering向量来实现目标行为,更重要的是,证明了存在大量其他Steering向量可以实现相同的行为。这种非唯一性揭示了现有激活Steering方法的一个根本局限性,即它们无法准确地揭示LLM的内部表示。
关键设计:本文的关键设计包括:1) 使用正交扰动来生成与原始Steering向量不同的干预措施;2) 采用多种模型和特征进行实验,以验证非唯一性的普遍性;3) 在不同的prompt分布下进行实验,以评估非唯一性的稳健性。此外,本文还使用了效应量分析来量化不同干预措施之间的差异,并证明正交扰动对模型行为的影响可以忽略不计。
🖼️ 关键图片
📊 实验亮点
实验结果表明,与原始Steering向量正交的扰动向量能够实现近乎等效的Steering效果,且效应量可以忽略不计。该结论在多个模型(未知)和多种特征(未知)上得到验证,并且在不同的prompt分布下保持稳健。这些结果有力地支持了Steering向量非唯一可识别性的结论。
🎯 应用场景
该研究成果对LLM的可解释性和对齐具有重要意义。它表明,仅仅依赖于行为测试来推断LLM的内部表示是不可靠的。未来的研究需要探索更强的结构约束,例如引入正则化项或使用更精细的干预方法,以实现更可靠的对齐干预。此外,该研究也提醒研究人员在解释LLM内部表示时要更加谨慎,避免过度解读。
📄 摘要(原文)
Activation steering methods are widely used to control large language model (LLM) behavior and are often interpreted as revealing meaningful internal representations. This interpretation assumes steering directions are identifiable and uniquely recoverable from input-output behavior. We show that, under white-box single-layer access, steering vectors are fundamentally non-identifiable due to large equivalence classes of behaviorally indistinguishable interventions. Empirically, we show that orthogonal perturbations achieve near-equivalent efficacy with negligible effect sizes across multiple models and traits. Critically, we show that the non-identifiability is a robust geometric property that persists across diverse prompt distributions. These findings reveal fundamental interpretability limits and highlight the need for structural constraints beyond behavioral testing to enable reliable alignment interventions.