FlowDA: Accurate, Low-Latency Weather Data Assimilation via Flow Matching
作者: Ran Cheng, Lailai Zhu
分类: cs.LG
发布日期: 2026-02-06
💡 一句话要点
FlowDA:基于Flow Matching的精准低延迟天气数据同化框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据同化 Flow Matching 天气预测 生成模型 低延迟 机器学习 SetConv Aurora模型
📋 核心要点
- 传统变分数据同化方法计算成本高昂,成为机器学习天气预测流程的瓶颈。
- FlowDA利用Flow Matching,通过SetConv嵌入观测信息并微调Aurora模型,实现高效数据同化。
- 实验表明,FlowDA在不同观测率下均优于基线方法,且对噪声具有鲁棒性,循环同化性能稳定。
📝 摘要(中文)
数据同化(DA)是现代天气预测的基础组成部分,但由于依赖传统的变分方法,它仍然是基于机器学习(ML)的预测流程中的主要计算瓶颈。最近基于生成式ML的DA方法提供了一种有希望的替代方案,但通常需要许多采样步骤,并且在具有循环同化的长时程自回归展开下会遭受误差累积。我们提出了FlowDA,一个基于flow matching的低延迟天气尺度生成式DA框架。FlowDA通过基于SetConv的嵌入来调节观测,并微调Aurora基础模型,以提供准确、高效和稳健的分析。在观测率从3.9%降低到0.1%的实验中,FlowDA表现出优于具有相似可调参数大小的强大基线的性能。FlowDA进一步显示出对观测噪声的鲁棒性,以及在长时程自回归循环DA中的稳定性能。总的来说,FlowDA为数据驱动的DA指出了一个高效且可扩展的方向。
🔬 方法详解
问题定义:论文旨在解决天气预测中数据同化过程计算量大、延迟高的问题。传统变分方法计算复杂度高,而基于生成模型的现有方法采样步骤多,且在长时程预测中容易累积误差,导致预测精度下降。
核心思路:论文的核心思路是利用Flow Matching技术,将数据同化过程建模为一个连续的概率流。通过学习一个将观测数据映射到天气状态的连续变换,可以高效地生成分析结果,避免了传统方法中复杂的优化过程和生成模型中大量的采样步骤。
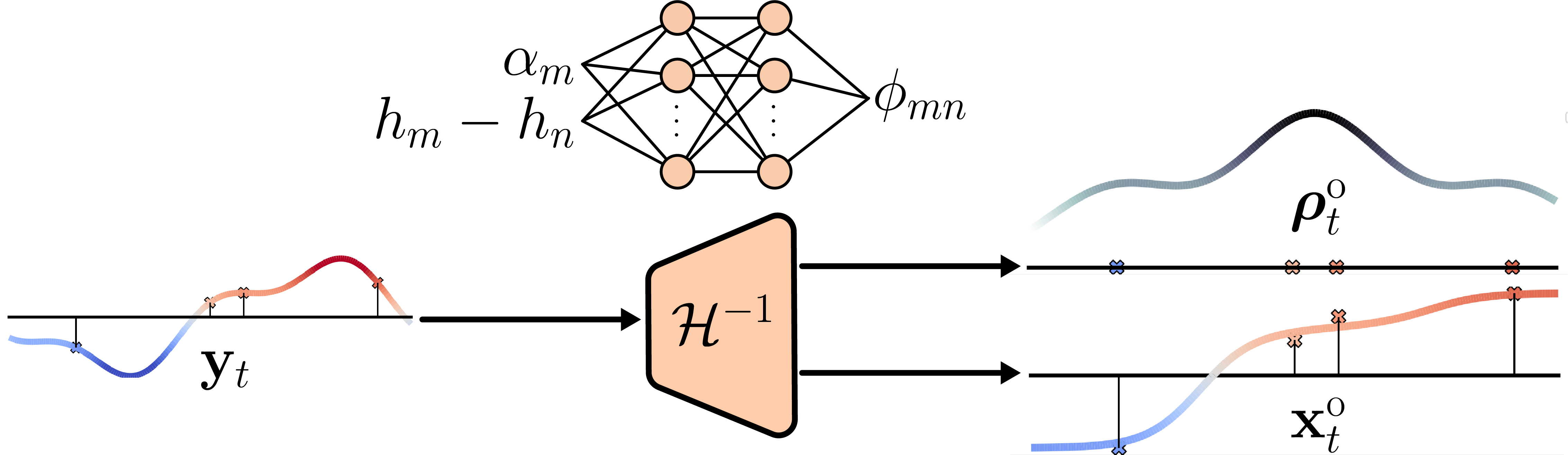
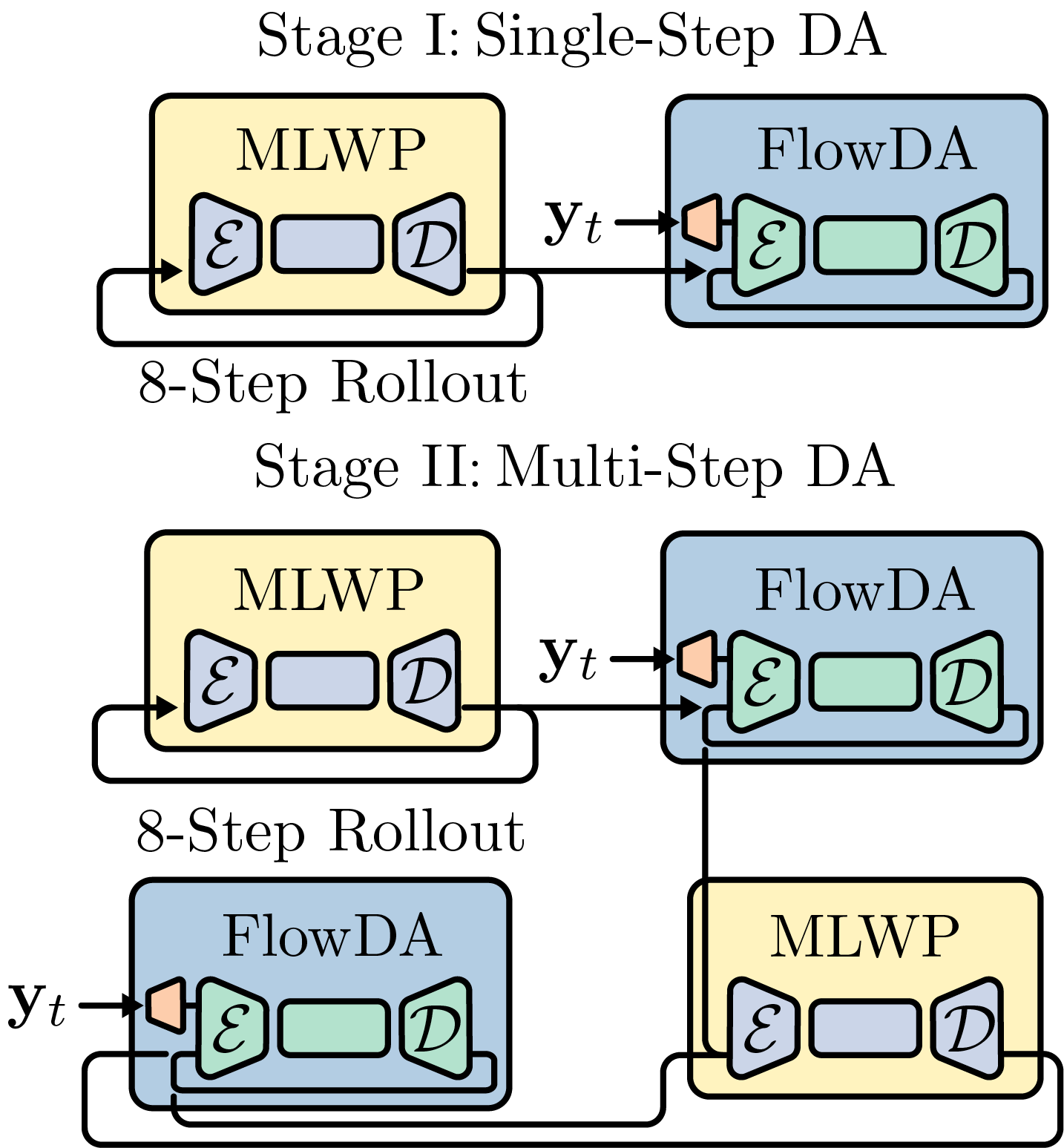
技术框架:FlowDA框架主要包含以下几个模块:1) 基于SetConv的观测嵌入模块:用于处理不同观测位置和类型的观测数据,生成观测信息的嵌入表示。2) 基于Flow Matching的生成模型:学习一个连续的概率流,将观测嵌入映射到天气状态。论文选择Aurora作为基础模型并进行微调。3) 循环同化模块:将分析结果作为下一步预测的初始状态,进行长时程的自回归预测和数据同化。
关键创新:FlowDA的关键创新在于将Flow Matching技术应用于天气数据同化,实现了低延迟和高精度的分析。与传统方法相比,Flow Matching避免了复杂的优化过程;与基于生成模型的方法相比,Flow Matching减少了采样步骤,降低了计算成本和误差累积的风险。
关键设计:FlowDA的关键设计包括:1) 使用SetConv处理观测数据,能够灵活地处理不同位置和类型的观测信息。2) 选择Aurora作为基础模型,并进行微调,利用了预训练模型的知识,提高了模型的泛化能力。3) 使用Flow Matching损失函数训练生成模型,保证了生成结果的准确性和一致性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FlowDA在观测率从3.9%降低到0.1%的情况下,性能优于具有相似参数量的基线方法。FlowDA还表现出对观测噪声的鲁棒性,并且在长时程自回归循环数据同化中表现出稳定的性能。这些结果表明,FlowDA是一种高效且可扩展的数据同化方法。
🎯 应用场景
FlowDA在气象预报领域具有广泛的应用前景,可以用于提高短期和长期天气预报的准确性和效率。该方法还可以应用于气候变化研究、环境监测和灾害预警等领域,为决策者提供更可靠的信息支持。此外,FlowDA的框架也可以推广到其他需要数据同化的领域,例如海洋预测和空间天气预报。
📄 摘要(原文)
Data assimilation (DA) is a fundamental component of modern weather prediction, yet it remains a major computational bottleneck in machine learning (ML)-based forecasting pipelines due to reliance on traditional variational methods. Recent generative ML-based DA methods offer a promising alternative but typically require many sampling steps and suffer from error accumulation under long-horizon auto-regressive rollouts with cycling assimilation. We propose FlowDA, a low-latency weather-scale generative DA framework based on flow matching. FlowDA conditions on observations through a SetConv-based embedding and fine-tunes the Aurora foundation model to deliver accurate, efficient, and robust analyses. Experiments across observation rates decreasing from $3.9\%$ to $0.1\%$ demonstrate superior performance of FlowDA over strong baselines with similar tunable-parameter size. FlowDA further shows robustness to observational noise and stable performance in long-horizon auto-regressive cycling DA. Overall, FlowDA points to an efficient and scalable direction for data-driven DA.