Optimal Learning-Rate Schedules under Functional Scaling Laws: Power Decay and Warmup-Stable-Decay
作者: Binghui Li, Zilin Wang, Fengling Chen, Shiyang Zhao, Ruiheng Zheng, Lei Wu
分类: stat.ML, cs.LG
发布日期: 2026-02-06 (更新: 2026-02-15)
💡 一句话要点
提出最优学习率调度以解决损失动态建模问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 学习率调度 功能缩放法则 损失动态 核回归 随机梯度下降 模型训练优化 相变分析
📋 核心要点
- 现有学习率调度方法在不同任务难度下的适应性不足,导致训练效率低下。
- 本文提出了一种基于功能缩放法则的最优学习率调度策略,能够根据任务难度动态调整学习率。
- 实验结果表明,所提方法在核回归任务中显著提高了训练效率,消除了对数次最优性问题。
📝 摘要(中文)
本研究在功能缩放法则框架下,探讨了最优学习率调度(LRS),该框架能够准确建模线性回归和大型语言模型(LLM)预训练的损失动态。通过分析损失动态的源指数和容量指数,本文在固定训练时间内推导出最优LRS,并揭示了明显的相变。在简单任务中,最优调度遵循幂衰减,而在困难任务中则表现为热身-稳定-衰减结构。我们还分析了形状固定的调度策略,并将幂衰减LRS应用于核回归的一次性随机梯度下降,证明了最后一次迭代达到了精确的最小最大最优率,消除了先前分析中的对数次最优性。数值实验验证了我们的理论预测。
🔬 方法详解
问题定义:本文旨在解决学习率调度在不同任务难度下的适应性问题,现有方法未能有效建模损失动态,导致训练效率低下。
核心思路:通过功能缩放法则框架,分析损失动态中的源指数和容量指数,推导出最优学习率调度策略,以适应不同的任务难度。
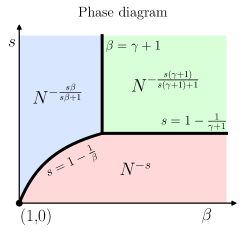
技术框架:整体架构包括损失动态建模、最优学习率推导和相变分析三个主要模块,分别处理不同任务的学习率调度。
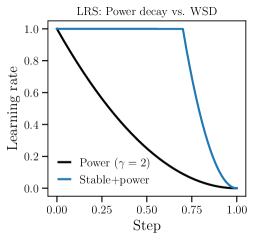
关键创新:最重要的创新在于提出了在简单任务中遵循幂衰减的学习率调度和在困难任务中采用热身-稳定-衰减结构的策略,这与现有方法的固定调度方式有本质区别。
关键设计:关键参数包括源指数和容量指数的选择,损失函数的设计,以及学习率的峰值设置,确保在不同训练阶段的有效性。具体的学习率调度公式也被详细推导。
🖼️ 关键图片
📊 实验亮点
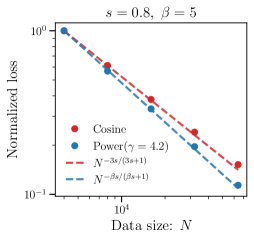
实验结果显示,所提幂衰减学习率调度在核回归任务中,最后一次迭代达到了精确的最小最大最优率,相较于传统方法消除了对数次最优性,显著提升了训练效率,验证了理论预测的准确性。
🎯 应用场景
该研究的潜在应用领域包括机器学习模型的训练优化,尤其是在处理复杂任务时的学习率调度。通过提高训练效率,能够加速模型收敛,降低计算成本,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
We study optimal learning-rate schedules (LRSs) under the functional scaling law (FSL) framework introduced in Li et al. (2025), which accurately models the loss dynamics of both linear regression and large language model (LLM) pre-training. Within FSL, loss dynamics are governed by two exponents: a source exponent $s>0$ controlling the rate of signal learning, and a capacity exponent $β>1$ determining the rate of noise forgetting. Focusing on a fixed training horizon $N$, we derive the optimal LRSs and reveal a sharp phase transition. In the easy-task regime $s \ge 1 - 1/β$, the optimal schedule follows a power decay to zero, $η^*(z) = η_{\mathrm{peak}}(1 - z/N)^{2β- 1}$, where the peak learning rate scales as $η_{\mathrm{peak}} \eqsim N^{-ν}$ for an explicit exponent $ν= ν(s,β)$. In contrast, in the hard-task regime $s < 1 - 1/β$, the optimal LRS exhibits a warmup-stable-decay (WSD) (Hu et al. (2024)) structure: it maintains the largest admissible learning rate for most of training and decays only near the end, with the decay phase occupying a vanishing fraction of the horizon. We further analyze optimal shape-fixed schedules, where only the peak learning rate is tuned -- a strategy widely adopted in practiceand characterize their strengths and intrinsic limitations. This yields a principled evaluation of commonly used schedules such as cosine and linear decay. Finally, we apply the power-decay LRS to one-pass stochastic gradient descent (SGD) for kernel regression and show the last iterate attains the exact minimax-optimal rate, eliminating the logarithmic suboptimality present in prior analyses. Numerical experiments corroborate our theoretical predictions.