Displacement-Resistant Extensions of DPO with Nonconvex $f$-Divergences
作者: Idan Pipano, Shoham Sabach, Kavosh Asadi, Mohammad Ghavamzadeh
分类: cs.LG
发布日期: 2026-02-06
备注: Published as a conference paper at ICLR 2026
💡 一句话要点
提出基于非凸f-散度的DPO扩展,提升奖励模型对概率偏移的抵抗性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 直接偏好优化 强化学习 语言模型对齐 f-散度 非凸优化
📋 核心要点
- 现有DPO方法依赖KL散度约束,限制了模型探索空间,且易出现概率偏移现象。
- 论文提出DPO-inducing条件,放宽了对f-散度的凸性要求,并引入displacement-resistant条件,抑制概率偏移。
- 论文设计了SquaredPO损失,在理论上保证了算法的有效性,并在实践中取得了与DPO相当的性能。
📝 摘要(中文)
本文针对语言模型对齐问题,通过直接优化RLHF目标来对齐语言模型:找到一个策略,该策略在最大化Bradley-Terry奖励的同时,通过KL散度惩罚保持接近参考策略。先前的工作表明,这种方法可以进一步推广:即使KL散度被具有凸生成函数f的f-散度族替换,原始问题仍然是易处理的。本文首先证明了f的凸性不是必需的。相反,我们确定了一个更通用的条件,称为DPO-inducing,它精确地描述了RLHF问题何时仍然是易处理的。我们的下一个贡献是建立f上的第二个条件,该条件对于防止概率偏移是必要的,概率偏移是一种已知的经验现象,其中获胜者和失败者响应的概率接近于零。我们将满足此条件的任何f称为displacement-resistant。最后,我们专注于一个特定的DPO-inducing和displacement-resistant的f,从而产生了我们新颖的SquaredPO损失。与DPO相比,这种新的损失提供了更强的理论保证,同时在实践中表现出竞争力。
🔬 方法详解
问题定义:论文旨在解决直接偏好优化(DPO)算法在对齐语言模型时,由于依赖KL散度约束而导致的探索空间受限以及容易出现的概率偏移问题。现有的DPO方法在优化奖励模型时,容易使得获胜和失败响应的概率趋近于零,影响模型的泛化能力和鲁棒性。
核心思路:论文的核心思路是放宽对f-散度的凸性要求,并引入新的约束条件来防止概率偏移。具体来说,论文提出了DPO-inducing条件,该条件精确地描述了RLHF问题何时仍然是易处理的,即使f-散度是非凸的。此外,论文还提出了displacement-resistant条件,该条件能够有效地防止获胜和失败响应的概率趋近于零。
技术框架:论文的技术框架主要包括以下几个部分:首先,重新定义了RLHF目标,将KL散度替换为更一般的f-散度。然后,推导了DPO-inducing条件,该条件保证了优化问题的可解性。接着,提出了displacement-resistant条件,该条件用于防止概率偏移。最后,基于这些理论结果,设计了一种新的损失函数,即SquaredPO损失。
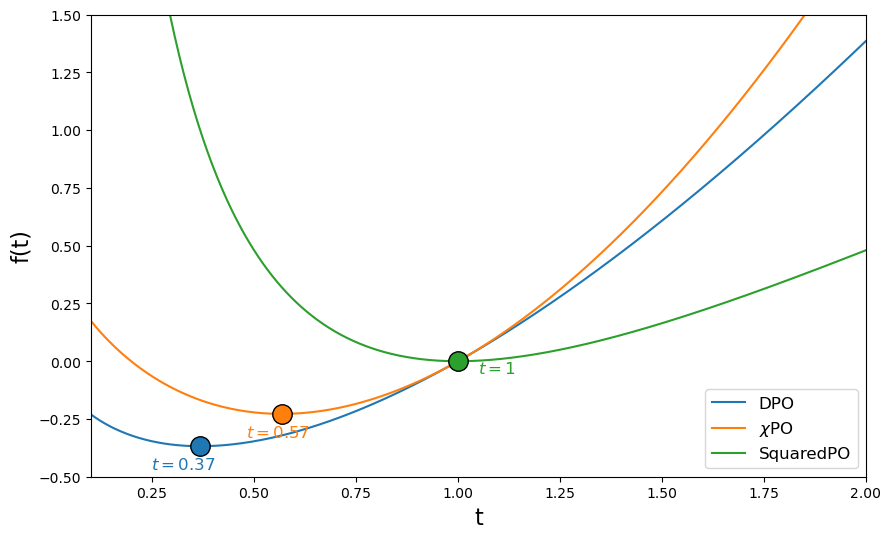
关键创新:论文最重要的技术创新点在于提出了DPO-inducing和displacement-resistant这两个条件。DPO-inducing条件放宽了对f-散度的限制,使得可以使用更广泛的f-散度来对齐语言模型。displacement-resistant条件则有效地解决了概率偏移问题,提高了模型的鲁棒性。与现有方法的本质区别在于,论文不再局限于凸的f-散度,而是探索了非凸f-散度的可能性,并提出了相应的理论保证。
关键设计:论文的关键设计在于SquaredPO损失函数。该损失函数基于一个特定的DPO-inducing和displacement-resistant的f-散度。具体来说,SquaredPO损失函数可以表示为:loss = (reward_winner - reward_loser)^2 - beta * f(exp(reward_winner - reward_loser)),其中beta是一个超参数,用于控制正则化强度。该损失函数的设计旨在平衡奖励最大化和概率偏移抑制两个目标。
🖼️ 关键图片

📊 实验亮点
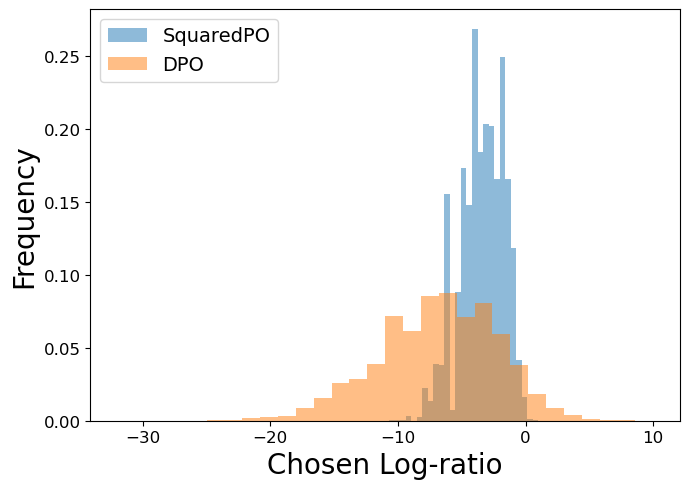
论文提出了SquaredPO损失,并在实验中验证了其有效性。实验结果表明,SquaredPO损失在与DPO损失相当的性能下,提供了更强的理论保证,并且能够有效地抑制概率偏移现象。这些结果表明,基于非凸f-散度的DPO扩展是一种有前景的语言模型对齐方法。
🎯 应用场景
该研究成果可应用于各种需要对齐语言模型的场景,例如对话系统、文本生成、机器翻译等。通过使用基于非凸f-散度的DPO扩展,可以提高模型的生成质量、鲁棒性和安全性,并减少概率偏移带来的负面影响。该研究对于提升语言模型的实际应用价值具有重要意义。
📄 摘要(原文)
DPO and related algorithms align language models by directly optimizing the RLHF objective: find a policy that maximizes the Bradley-Terry reward while staying close to a reference policy through a KL divergence penalty. Previous work showed that this approach could be further generalized: the original problem remains tractable even if the KL divergence is replaced by a family of $f$-divergence with a convex generating function $f$. Our first contribution is to show that convexity of $f$ is not essential. Instead, we identify a more general condition, referred to as DPO-inducing, that precisely characterizes when the RLHF problem remains tractable. Our next contribution is to establish a second condition on $f$ that is necessary to prevent probability displacement, a known empirical phenomenon in which the probabilities of the winner and the loser responses approach zero. We refer to any $f$ that satisfies this condition as displacement-resistant. We finally focus on a specific DPO-inducing and displacement-resistant $f$, leading to our novel SquaredPO loss. Compared to DPO, this new loss offers stronger theoretical guarantees while performing competitively in practice.