Soft Forward-Backward Representations for Zero-shot Reinforcement Learning with General Utilities
作者: Marco Bagatella, Thomas Rupf, Georg Martius, Andreas Krause
分类: cs.LG
发布日期: 2026-02-06
💡 一句话要点
提出软前向-后向表示,用于解决通用效用函数下的零样本强化学习问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 零样本强化学习 通用效用函数 前向-后向算法 最大熵 离线强化学习 策略优化 机器人控制
📋 核心要点
- 传统零样本强化学习方法在处理通用效用函数时存在局限性,无法直接优化分布匹配或纯探索等复杂任务。
- 提出一种基于最大熵的软前向-后向算法,从离线数据中学习随机策略,并结合零阶搜索优化通用效用函数。
- 实验表明,该方法在保留前向-后向算法优点的同时,能够有效解决更广泛的强化学习问题。
📝 摘要(中文)
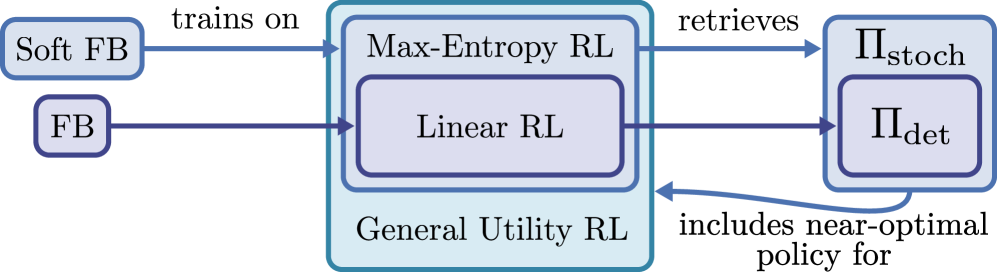
本文针对零样本强化学习(RL)领域,利用无标签离线数据提取多样化行为。特别地,前向-后向算法(FB)能够检索出一系列策略,近似解决任何标准RL问题(具有可加奖励,且与占用度量呈线性关系),但需要足够的容量。本文在保留零样本特性的同时,解决了更广泛的通用效用函数下的RL问题,其中目标是占用度量的任意可微函数。这种设置更具表达性,可以捕捉诸如分布匹配或纯探索等任务,这些任务可能无法简化为可加奖励。我们展示了这种额外的复杂性可以通过一种新颖的、最大熵(软)的前向-后向算法变体来捕捉,该算法从离线数据中恢复一系列随机策略。当与紧凑策略嵌入上的零阶搜索相结合时,该算法可以避开迭代优化方案,并在测试时直接优化通用效用函数。在教学和高维实验中,我们证明了我们的方法保留了FB算法的良好特性,同时将其范围扩展到更通用的RL问题。
🔬 方法详解
问题定义:论文旨在解决通用效用函数下的零样本强化学习问题。传统的强化学习方法通常依赖于可加奖励函数,难以处理诸如分布匹配或纯探索等复杂任务。现有的前向-后向算法虽然在标准RL问题上表现良好,但在处理通用效用函数时存在局限性,需要进行改进和扩展。
核心思路:论文的核心思路是利用最大熵原则,提出一种软前向-后向算法。通过引入熵正则化,鼓励策略的多样性,从而更好地探索状态空间,并适应不同的通用效用函数。此外,结合零阶搜索,直接在策略嵌入空间中优化通用效用函数,避免了传统的迭代优化过程。
技术框架:整体框架包括离线数据收集、软前向-后向算法学习策略族、以及零阶搜索优化三个主要阶段。首先,从离线数据中学习得到一系列随机策略,这些策略构成一个策略族。然后,利用零阶搜索算法,在策略嵌入空间中搜索最优策略,以最大化给定的通用效用函数。该框架避免了传统的策略迭代或值迭代等优化过程,可以直接优化通用效用函数。
关键创新:最重要的技术创新点在于软前向-后向算法的提出。该算法通过引入最大熵正则化,鼓励策略的多样性,从而更好地适应不同的通用效用函数。与传统的前向-后向算法相比,软前向-后向算法能够学习到更丰富的策略族,从而更好地解决复杂强化学习问题。
关键设计:软前向-后向算法的关键设计包括熵正则化系数的选择、策略嵌入空间的维度、以及零阶搜索算法的参数设置。熵正则化系数控制策略的多样性,需要根据具体问题进行调整。策略嵌入空间的维度决定了策略的表达能力,需要根据状态空间和动作空间的复杂度进行选择。零阶搜索算法的参数设置,如搜索步长和迭代次数,会影响搜索效率和最终性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在教学实验和高维实验中均取得了良好的效果。与传统的前向-后向算法相比,该方法能够更好地解决通用效用函数下的强化学习问题。具体的性能数据和提升幅度在论文中有详细的展示,表明该方法具有较强的实用价值。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、推荐系统等领域。例如,在机器人控制中,可以利用该方法学习机器人的多种运动技能,并根据不同的任务目标进行组合。在游戏AI中,可以利用该方法训练AI玩家,使其能够适应不同的游戏规则和环境。在推荐系统中,可以利用该方法优化推荐策略,提高用户满意度。
📄 摘要(原文)
Recent advancements in zero-shot reinforcement learning (RL) have facilitated the extraction of diverse behaviors from unlabeled, offline data sources. In particular, forward-backward algorithms (FB) can retrieve a family of policies that can approximately solve any standard RL problem (with additive rewards, linear in the occupancy measure), given sufficient capacity. While retaining zero-shot properties, we tackle the greater problem class of RL with general utilities, in which the objective is an arbitrary differentiable function of the occupancy measure. This setting is strictly more expressive, capturing tasks such as distribution matching or pure exploration, which may not be reduced to additive rewards. We show that this additional complexity can be captured by a novel, maximum entropy (soft) variant of the forward-backward algorithm, which recovers a family of stochastic policies from offline data. When coupled with zero-order search over compact policy embeddings, this algorithm can sidestep iterative optimization schemes, and optimizes general utilities directly at test-time. Across both didactic and high-dimensional experiments, we demonstrate that our method retains favorable properties of FB algorithms, while also extending their range to more general RL problems.