NanoQuant: Efficient Sub-1-Bit Quantization of Large Language Models
作者: Hyochan Chong, Dongkyu Kim, Changdong Kim, Minseop Choi
分类: cs.LG
发布日期: 2026-02-06
备注: 26 pages. Hyochan Chong and Dongkyu Kim contributed equally to this work
💡 一句话要点
NanoQuant:首个实现大语言模型高效Sub-1-Bit量化的后训练量化方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型量化 后训练量化 二值化 低秩分解
📋 核心要点
- 现有权重仅量化方法难以在二值化压缩LLM时兼顾效率与精度,需要大量数据或引入额外存储。
- NanoQuant将量化建模为低秩二值分解,利用ADMM初始化二值矩阵和缩放因子,并通过重构进行微调。
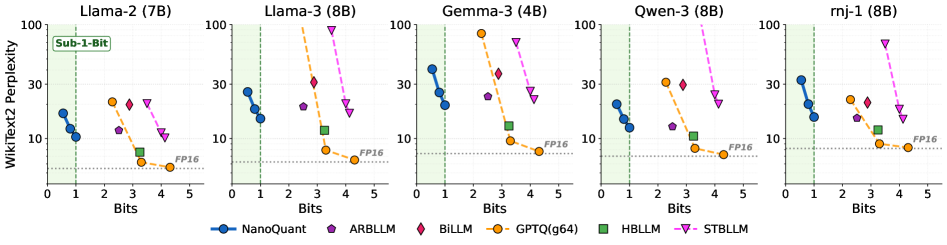
- NanoQuant在亚1比特压缩率下实现了SOTA精度,并能在消费级硬件上部署大型LLM,如在8GB GPU上运行70B模型。
📝 摘要(中文)
本文提出NanoQuant,这是首个将大型语言模型(LLMs)压缩到二值(1-bit)和亚1比特级别的后训练量化(PTQ)方法。现有方法在将模型高效压缩到二值级别时面临挑战,要么需要大量数据和计算资源,要么会产生额外的存储开销。NanoQuant将量化问题建模为低秩二值分解问题,并将全精度权重压缩为低秩二值矩阵和缩放因子。具体而言,它利用高效的交替方向乘子法(ADMM)来精确初始化潜在的二值矩阵和缩放因子,然后通过块和模型重构过程调整初始化的参数。NanoQuant在低内存后训练量化中建立了一个新的Pareto前沿,即使在亚1比特压缩率下也能实现最先进的精度。NanoQuant使得大规模部署在消费级硬件上成为可能。例如,它可以在单个H100上仅用13小时将Llama2-70B压缩25.8倍,从而使70B模型能够在消费级8 GB GPU上运行。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)权重仅量化方法,在压缩到二值(1-bit)甚至亚1比特级别时,面临着效率和精度之间的权衡问题。一些方法需要大量的训练数据和计算资源来进行量化,而另一些方法则会引入额外的存储开销,限制了它们在资源受限环境中的部署。
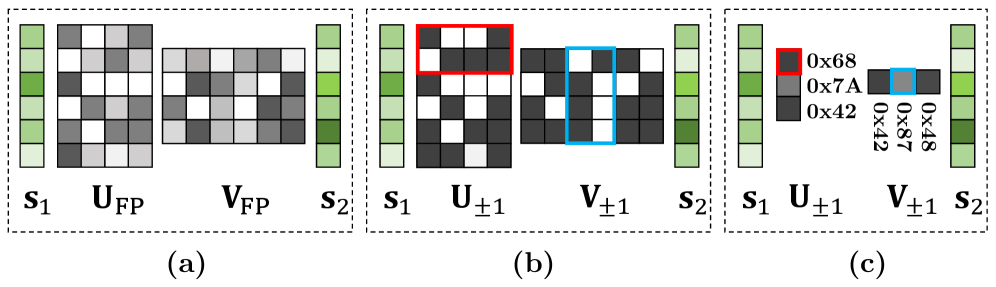
核心思路:NanoQuant的核心思路是将量化问题转化为一个低秩二值分解问题。具体来说,它试图将原始的全精度权重矩阵分解为两个低秩矩阵的乘积,其中一个矩阵是二值矩阵,另一个是缩放因子。通过这种方式,模型可以被压缩到非常低的比特级别,同时尽可能地保留原始模型的性能。这种设计的关键在于找到合适的二值矩阵和缩放因子,以最小化量化误差。
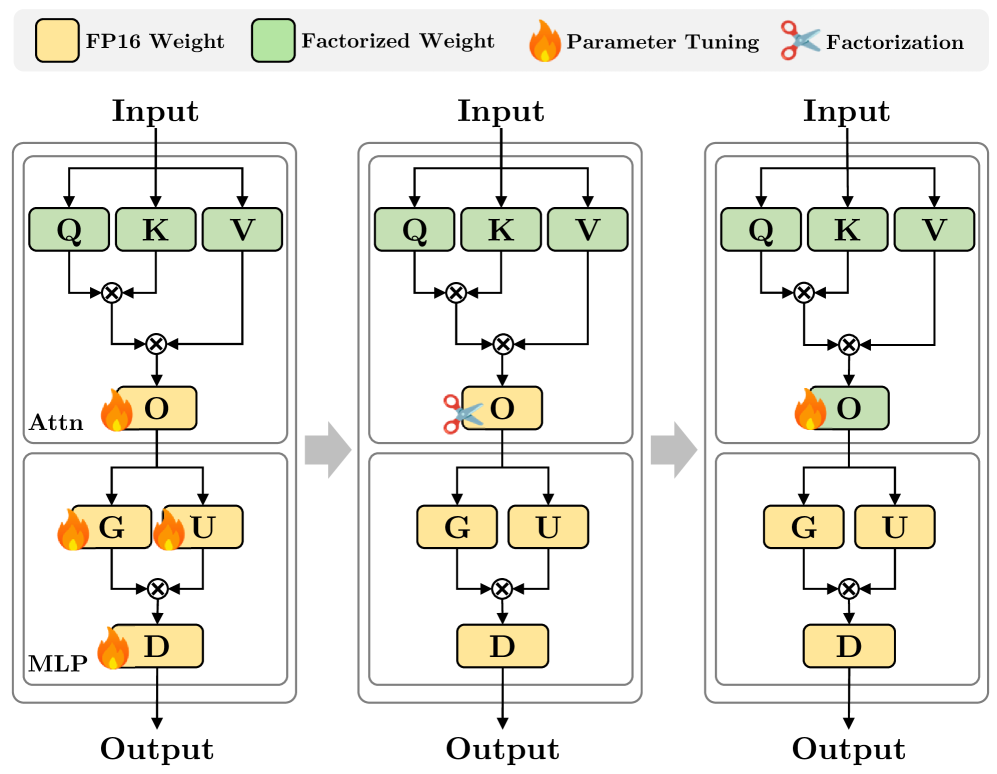
技术框架:NanoQuant的整体框架包括以下几个主要阶段:1) 初始化:使用高效的交替方向乘子法(ADMM)来初始化潜在的二值矩阵和缩放因子。ADMM能够有效地解决带有约束的优化问题,从而找到一个较好的初始解。2) 块和模型重构:在初始化之后,通过一个块和模型重构过程来进一步调整初始化的参数。这个过程旨在最小化量化后的模型与原始模型之间的差异,从而提高量化模型的精度。
关键创新:NanoQuant的关键创新在于它将量化问题建模为一个低秩二值分解问题,并利用ADMM进行初始化。这种方法能够有效地压缩模型到非常低的比特级别,同时保持较高的精度。与现有方法相比,NanoQuant不需要大量的训练数据,也不需要引入额外的存储开销,因此更加高效和实用。此外,通过块和模型重构过程,NanoQuant能够进一步提高量化模型的精度。
关键设计:NanoQuant的关键设计包括:1) 使用ADMM进行初始化,这需要仔细选择ADMM的参数,以确保算法的收敛性和效率。2) 块和模型重构过程,这需要设计合适的损失函数来衡量量化后的模型与原始模型之间的差异。3) 低秩分解的秩的选择,这需要在压缩率和精度之间进行权衡。论文中可能还包含一些其他的技术细节,例如如何处理不同类型的权重矩阵,以及如何优化量化过程的计算效率。
🖼️ 关键图片
📊 实验亮点
NanoQuant在压缩Llama2-70B模型上表现出色,仅用单个H100 GPU上的13小时,实现了25.8倍的压缩。更重要的是,它使得在消费级8GB GPU上运行70B参数的LLM成为可能。这些结果表明NanoQuant在低内存后训练量化方面达到了新的Pareto前沿,即使在亚1比特压缩率下也能保持领先的精度。
🎯 应用场景
NanoQuant在资源受限的边缘设备上部署大型语言模型方面具有广阔的应用前景。例如,可以在智能手机、嵌入式系统和物联网设备上运行复杂的LLM,从而实现本地化的自然语言处理和人工智能服务。此外,该技术还可以用于降低数据中心的存储和计算成本,提高LLM的部署效率。未来,NanoQuant有望推动LLM在更多领域的应用,例如智能助手、自动驾驶和医疗诊断。
📄 摘要(原文)
Weight-only quantization has become a standard approach for efficiently serving large language models (LLMs). However, existing methods fail to efficiently compress models to binary (1-bit) levels, as they either require large amounts of data and compute or incur additional storage. In this work, we propose NanoQuant, the first post-training quantization (PTQ) method to compress LLMs to both binary and sub-1-bit levels. NanoQuant formulates quantization as a low-rank binary factorization problem, and compresses full-precision weights to low-rank binary matrices and scales. Specifically, it utilizes an efficient alternating direction method of multipliers (ADMM) method to precisely initialize latent binary matrices and scales, and then tune the initialized parameters through a block and model reconstruction process. Consequently, NanoQuant establishes a new Pareto frontier in low-memory post-training quantization, achieving state-of-the-art accuracy even at sub-1-bit compression rates. NanoQuant makes large-scale deployment feasible on consumer hardware. For example, it compresses Llama2-70B by 25.8$\times$ in just 13 hours on a single H100, enabling a 70B model to operate on a consumer 8 GB GPU.