Dynamics-Aligned Shared Hypernetworks for Zero-Shot Actuator Inversion
作者: Jan Benad, Pradeep Kr. Banerjee, Frank Röder, Nihat Ay, Martin V. Butz, Manfred Eppe
分类: cs.LG, cs.AI
发布日期: 2026-02-06
💡 一句话要点
提出DMA*-SH框架,通过动态对齐的共享超网络解决零样本执行器反演问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 零样本学习 执行器反演 超网络 情境强化学习 动态模型 归纳偏置
📋 核心要点
- 情境强化学习中,零样本泛化面临挑战,尤其是在潜在情境需要从数据中推断时,执行器反演问题尤为突出。
- DMA*-SH框架通过共享超网络生成适配器权重,在动态模型、策略和价值函数间共享,引入与执行器反演匹配的归纳偏置。
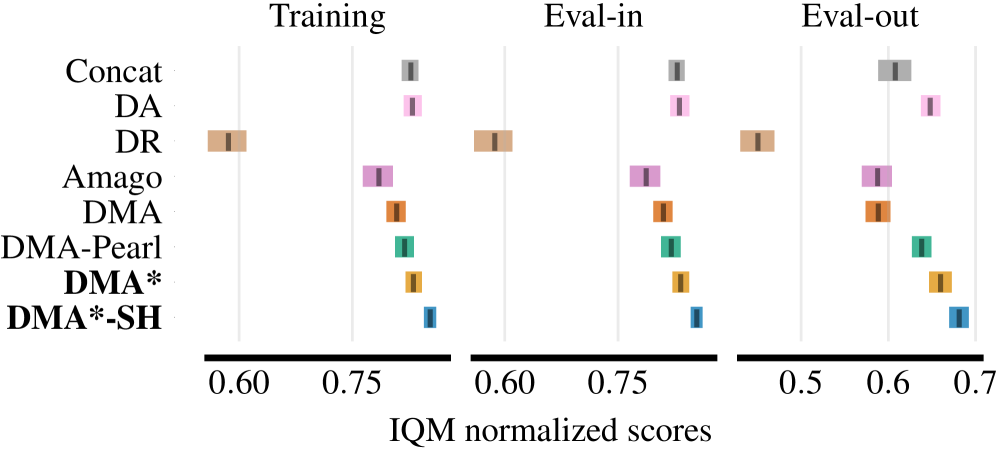
- 在执行器反演基准(AIB)测试中,DMA*-SH实现了零样本泛化,显著优于领域随机化和标准情境感知基线。
📝 摘要(中文)
本文针对情境强化学习中的零样本泛化难题,特别是当情境是潜在的且必须从数据中推断时,提出了一种名为DMA-SH的框架。该框架利用单个超网络,仅通过动态预测进行训练,生成一组小的适配器权重,这些权重在动态模型、策略和动作价值函数之间共享。这种共享调制赋予了与执行器反演相匹配的归纳偏置,同时输入/输出归一化和随机输入掩码稳定了情境推断,促进了方向集中的表示。论文通过超网络调制的表达能力分离结果提供了理论支持,并通过策略梯度方差界限的方差分解,形式化了模式内压缩如何改善执行器反演下的学习。为了评估,论文引入了执行器反演基准(AIB),这是一套旨在隔离不连续情境到动态交互的环境。在AIB的保留执行器反演任务上,DMA-SH实现了零样本泛化,优于领域随机化111.8%,超过标准情境感知基线16.1%。
🔬 方法详解
问题定义:论文旨在解决情境强化学习中的零样本执行器反演问题。在执行器反演场景下,相同的动作在不同的潜在情境下会产生相反的物理效果,这使得智能体难以学习有效的策略。现有的方法,如领域随机化,泛化能力有限,而标准的情境感知方法难以有效地推断和利用潜在情境信息。
核心思路:论文的核心思路是利用一个共享的超网络来生成适配器权重,这些权重用于调制动态模型、策略和动作价值函数。通过这种共享调制,模型能够学习到与执行器反演问题相匹配的归纳偏置,从而提高零样本泛化能力。此外,输入/输出归一化和随机输入掩码技术用于稳定情境推断,促进方向集中的表示。
技术框架:DMA*-SH框架包含以下主要模块:1) 一个超网络,用于生成适配器权重;2) 一个动态模型,用于预测环境的下一个状态;3) 一个策略网络,用于选择动作;4) 一个动作价值函数,用于评估动作的价值。超网络仅通过动态预测进行训练,生成的适配器权重被共享到动态模型、策略和动作价值函数中。输入/输出归一化和随机输入掩码被应用于输入数据,以稳定情境推断。
关键创新:最重要的技术创新点在于使用动态对齐的共享超网络来学习与执行器反演问题相匹配的归纳偏置。与传统的领域随机化和情境感知方法不同,DMA*-SH框架通过共享调制实现了更好的零样本泛化能力。此外,论文还提供了超网络调制的表达能力分离结果和策略梯度方差界限的方差分解,为该方法的有效性提供了理论支持。
关键设计:超网络采用多层感知机(MLP)结构,输入是环境状态和动作,输出是适配器权重。适配器权重用于调制动态模型、策略和动作价值函数的参数。损失函数主要基于动态预测误差。输入/输出归一化采用均值和方差归一化,随机输入掩码随机地将输入的一部分设置为零。具体参数设置(如网络层数、神经元数量、学习率等)根据具体环境进行调整。
🖼️ 关键图片


📊 实验亮点
DMA-SH在执行器反演基准(AIB)上取得了显著的性能提升,在零样本泛化任务中,DMA-SH优于领域随机化111.8%,超过标准情境感知基线16.1%。这些结果表明,DMA*-SH框架能够有效地学习与执行器反演问题相匹配的归纳偏置,从而提高零样本泛化能力。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶等领域,尤其是在环境动态变化或存在潜在情境的场景下。例如,在机器人操作中,机械臂可能需要在不同的负载或摩擦条件下执行相同的任务,DMA*-SH框架可以帮助机器人适应这些变化,提高其鲁棒性和泛化能力。此外,该方法还可以用于模拟器到真实世界的迁移学习,减少对大量真实世界数据的依赖。
📄 摘要(原文)
Zero-shot generalization in contextual reinforcement learning remains a core challenge, particularly when the context is latent and must be inferred from data. A canonical failure mode is actuator inversion, where identical actions produce opposite physical effects under a latent binary context. We propose DMA-SH, a framework where a single hypernetwork, trained solely via dynamics prediction, generates a small set of adapter weights shared across the dynamics model, policy, and action-value function. This shared modulation imparts an inductive bias matched to actuator inversion, while input/output normalization and random input masking stabilize context inference, promoting directionally concentrated representations. We provide theoretical support via an expressivity separation result for hypernetwork modulation, and a variance decomposition with policy-gradient variance bounds that formalize how within-mode compression improves learning under actuator inversion. For evaluation, we introduce the Actuator Inversion Benchmark (AIB), a suite of environments designed to isolate discontinuous context-to-dynamics interactions. On AIB's held-out actuator-inversion tasks, DMA-SH achieves zero-shot generalization, outperforming domain randomization by 111.8% and surpassing a standard context-aware baseline by 16.1%.