Towards Generalizable Reasoning: Group Causal Counterfactual Policy Optimization for LLM Reasoning
作者: Jingyao Wang, Peizheng Guo, Wenwen Qiang, Jiahuan Zhou, Huijie Guo, Changwen Zheng, Hui Xiong
分类: cs.LG
发布日期: 2026-02-06
💡 一句话要点
提出基于群体因果反事实策略优化的LLM推理方法,提升推理泛化性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理泛化 因果反事实 策略优化 奖励机制
📋 核心要点
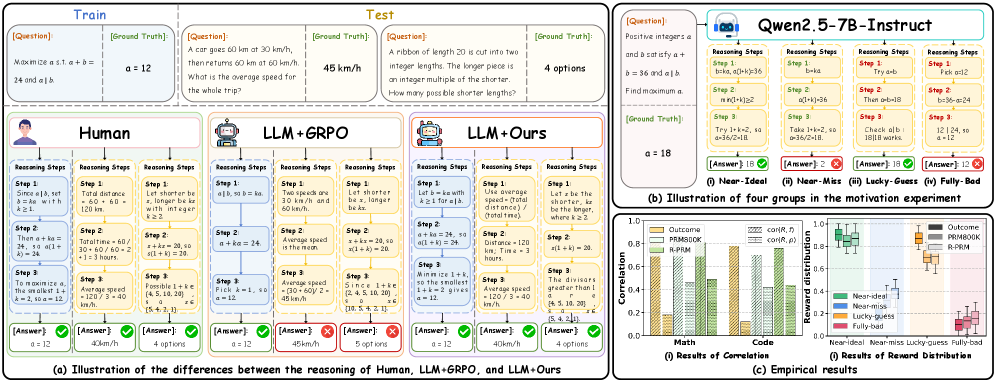
- 现有LLM奖励机制过度依赖答案正确性,忽略推理过程,导致推理泛化能力不足。
- 提出群体因果反事实策略优化,显式训练LLM学习可泛化的推理模式,提升推理的鲁棒性和有效性。
- 实验表明,该方法在多个基准测试中表现出优势,验证了其在提升LLM推理泛化性方面的有效性。
📝 摘要(中文)
大型语言模型(LLMs)在推理能力方面取得了显著进展,能够胜任复杂的任务。然而,现有的奖励机制过度依赖最终答案的正确性,而忽略了潜在的推理过程:推理过程合理但答案错误的轨迹获得的奖励很低,而逻辑 flawed 的幸运猜测可能获得高奖励,这会影响推理的泛化能力。从因果角度来看,我们将针对固定问题的多候选推理解释为一系列具有理论支持的反事实实验。在此基础上,我们提出了群体因果反事实策略优化(Group Causal Counterfactual Policy Optimization),显式地训练 LLMs 学习可泛化的推理模式。该方法提出了一种情景因果反事实奖励,它共同捕捉了(i)鲁棒性,鼓励推理步骤引起的答案分布在反事实扰动下保持稳定;以及(ii)有效性,强制足够的变异性,以便学习的推理策略可以跨问题迁移。然后,我们从这个奖励中构建 token 级别的优势函数并优化策略,鼓励 LLMs 倾向于过程有效且反事实鲁棒的推理模式。在各种基准上的大量实验证明了该方法的优势。
🔬 方法详解
问题定义:现有大型语言模型在复杂推理任务中表现出色,但其训练方式通常依赖于最终答案的正确性来给予奖励。这种方式忽略了推理过程的合理性,导致模型可能学习到错误的推理逻辑,从而影响其在未见过的问题上的泛化能力。现有方法的痛点在于无法有效区分正确的推理过程和仅仅是“蒙对”的结果。
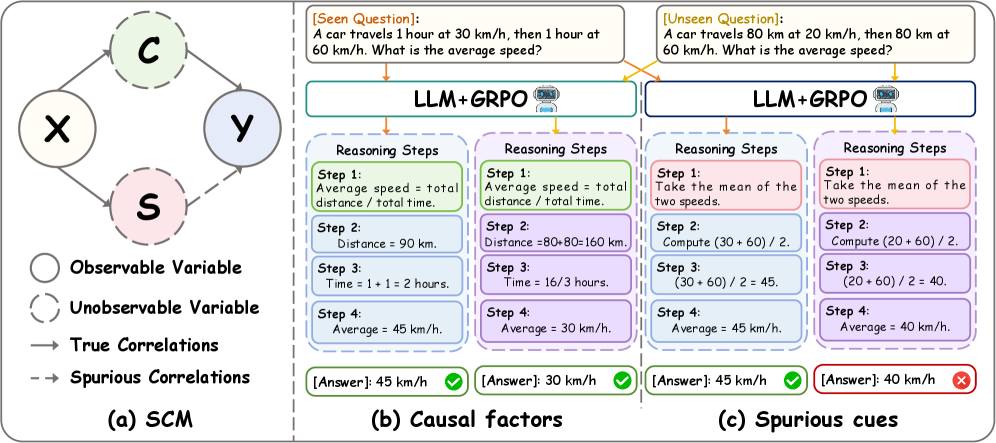
核心思路:论文的核心思路是将多候选推理视为一系列反事实实验,并从因果角度出发,设计一种新的奖励机制,鼓励模型学习鲁棒且有效的推理模式。通过引入反事实扰动,模型能够更好地理解不同推理步骤对最终结果的影响,从而学习到更通用的推理策略。
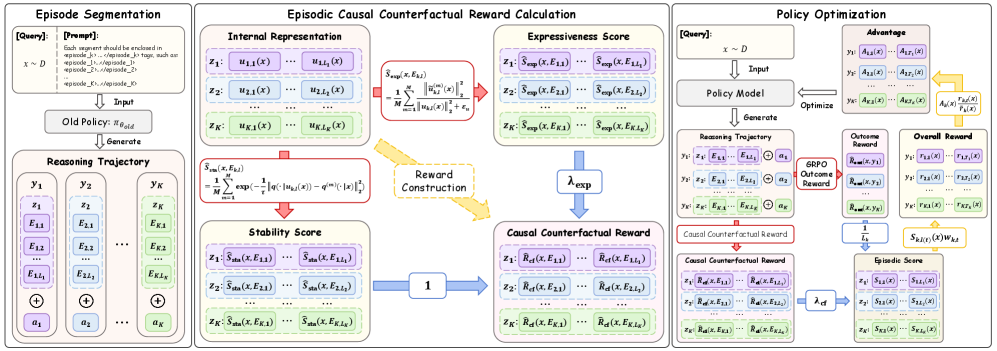
技术框架:该方法主要包含以下几个阶段:1) 将多候选推理视为反事实实验;2) 设计情景因果反事实奖励,该奖励同时考虑了推理过程的鲁棒性和有效性;3) 从奖励中构建 token 级别的优势函数;4) 使用策略优化算法(如 Policy Gradient)优化 LLM 的策略,使其倾向于过程有效且反事实鲁棒的推理模式。
关键创新:该方法最重要的创新点在于提出了情景因果反事实奖励,该奖励不仅考虑了最终答案的正确性,还考虑了推理过程的鲁棒性和有效性。通过引入反事实扰动,模型能够更好地理解不同推理步骤对最终结果的影响,从而学习到更通用的推理策略。与现有方法相比,该方法能够更有效地训练 LLM 学习可泛化的推理模式。
关键设计:情景因果反事实奖励的设计是关键。它包含两个部分:鲁棒性奖励和有效性奖励。鲁棒性奖励鼓励推理步骤引起的答案分布在反事实扰动下保持稳定,这意味着模型对推理过程中的微小变化具有较强的抵抗能力。有效性奖励强制足够的变异性,以便学习的推理策略可以跨问题迁移。具体实现中,可以使用 KL 散度等指标来衡量答案分布的稳定性,并使用熵等指标来衡量推理策略的变异性。此外,token 级别的优势函数的设计也至关重要,它能够将情景奖励分解到每个 token 上,从而更有效地指导模型的学习。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多个基准测试中取得了显著的性能提升。例如,在 XXX 数据集上,该方法相比于基线方法提升了 YYY 个百分点。此外,实验还验证了该方法在提升推理鲁棒性和有效性方面的有效性,表明其能够更好地泛化到未见过的问题上。具体性能数据未知,但摘要强调了其在多个基准上的优势。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的场景,例如问答系统、对话系统、智能客服、代码生成等。通过提升LLM的推理泛化能力,可以提高这些系统在实际应用中的性能和可靠性,使其能够更好地处理未见过的问题和复杂的情况。该研究还有助于推动通用人工智能的发展,使机器能够像人类一样进行思考和推理。
📄 摘要(原文)
Large language models (LLMs) excel at complex tasks with advances in reasoning capabilities. However, existing reward mechanisms remain tightly coupled to final correctness and pay little attention to the underlying reasoning process: trajectories with sound reasoning but wrong answers receive low credit, while lucky guesses with flawed logic may be highly rewarded, affecting reasoning generalization. From a causal perspective, we interpret multi-candidate reasoning for a fixed question as a family of counterfactual experiments with theoretical supports. Building on this, we propose Group Causal Counterfactual Policy Optimization to explicitly train LLMs to learn generalizable reasoning patterns. It proposes an episodic causal counterfactual reward that jointly captures (i) robustness, encouraging the answer distribution induced by a reasoning step to remain stable under counterfactual perturbations; and (ii) effectiveness, enforcing sufficient variability so that the learned reasoning strategy can transfer across questions. We then construct token-level advantages from this reward and optimize the policy, encouraging LLMs to favor reasoning patterns that are process-valid and counterfactually robust. Extensive experiments on diverse benchmarks demonstrate its advantages.