On the Plasticity and Stability for Post-Training Large Language Models
作者: Wenwen Qiang, Ziyin Gu, Jiahuan Zhou, Jie Hu, Jingyao Wang, Changwen Zheng, Hui Xiong
分类: cs.LG
发布日期: 2026-02-06
💡 一句话要点
提出概率冲突解决(PCR)框架,提升后训练大语言模型的稳定性和可塑性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后训练 群体相对策略优化 训练稳定性 概率冲突解决
📋 核心要点
- 群体相对策略优化(GRPO)在训练中面临稳定性问题,需要在推理可塑性和通用能力保持之间进行权衡。
- 论文提出概率冲突解决(PCR)框架,将梯度建模为随机变量,通过不确定性感知的“软投影”机制动态仲裁冲突。
- 实验结果表明,PCR能够显著平滑训练轨迹,并在多种推理任务中取得更好的性能。
📝 摘要(中文)
训练稳定性是群体相对策略优化(GRPO)的关键瓶颈,通常表现为推理可塑性和通用能力保持之间的权衡。本文确定了一个根本原因是可塑性和稳定性梯度之间的几何冲突,这导致了破坏性干扰。我们认为,确定性投影方法对于GRPO来说是次优的,因为它们忽略了基于群体的梯度估计的内在随机性。为了解决这个问题,我们提出了概率冲突解决(PCR),这是一个将梯度建模为随机变量的贝叶斯框架。PCR通过一种不确定性感知的“软投影”机制动态地仲裁冲突,优化信噪比。大量的实验表明,PCR显著地平滑了训练轨迹,并在各种推理任务中取得了优异的性能。
🔬 方法详解
问题定义:论文旨在解决后训练大语言模型在使用群体相对策略优化(GRPO)时遇到的训练稳定性问题。现有方法,特别是确定性投影方法,在处理GRPO中固有的梯度估计随机性时表现不佳,导致可塑性和稳定性梯度之间的冲突,最终影响模型性能。现有方法的痛点在于无法有效平衡模型的推理可塑性和通用能力保持。
核心思路:论文的核心思路是将梯度视为随机变量,并利用贝叶斯框架来建模和解决可塑性和稳定性梯度之间的冲突。通过引入不确定性感知的“软投影”机制,PCR能够动态地仲裁这些冲突,从而优化信噪比,平滑训练轨迹。
技术框架:PCR框架主要包含以下几个阶段:1) 梯度估计:使用GRPO方法估计可塑性和稳定性梯度;2) 梯度建模:将梯度建模为随机变量,考虑其不确定性;3) 冲突仲裁:使用贝叶斯框架,基于梯度的不确定性,通过“软投影”机制动态仲裁冲突;4) 参数更新:根据仲裁后的梯度更新模型参数。
关键创新:PCR的关键创新在于其概率性的冲突解决方式。与传统的确定性投影方法不同,PCR考虑了梯度估计的内在随机性,并利用贝叶斯框架来建模这种不确定性。通过不确定性感知的“软投影”机制,PCR能够更有效地平衡可塑性和稳定性,从而提高训练的稳定性。
关键设计:PCR的关键设计包括:1) 将梯度建模为随机变量,通常假设为高斯分布;2) 使用贝叶斯推断来估计梯度的后验分布;3) 设计不确定性感知的“软投影”机制,该机制根据梯度不确定性的大小来调整投影的强度;4) 优化目标通常是最大化信噪比,即最大化有用信号的同时最小化噪声。
🖼️ 关键图片
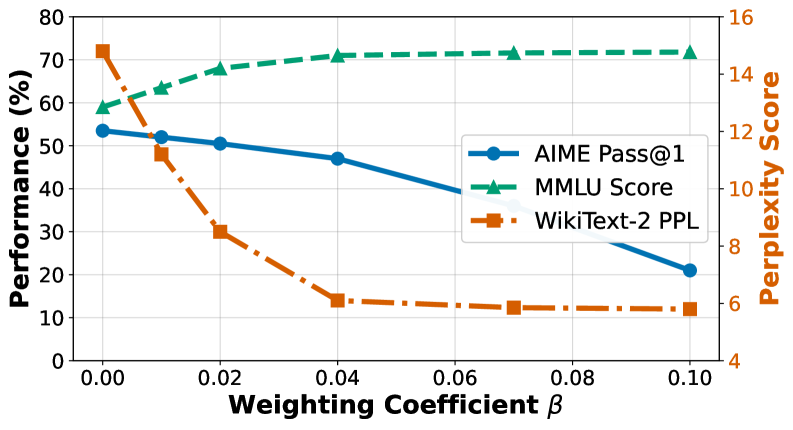
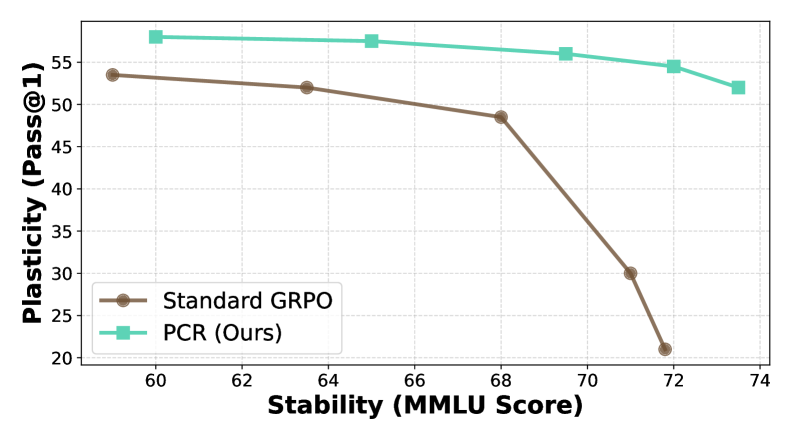

📊 实验亮点
实验结果表明,PCR能够显著平滑训练轨迹,并在各种推理任务中取得了优异的性能。具体来说,PCR在多个基准测试中超越了现有的GRPO方法,并在某些任务上取得了显著的性能提升。这些结果验证了PCR在提高后训练大语言模型的稳定性和可塑性方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要持续学习或微调的大语言模型场景,例如:领域知识迁移、任务适应、模型修复等。通过提高训练的稳定性和可塑性,PCR能够帮助大语言模型更好地适应新的数据和任务,提升其在实际应用中的性能和泛化能力。该方法还有潜力应用于其他机器学习模型的训练优化。
📄 摘要(原文)
Training stability remains a critical bottleneck for Group Relative Policy Optimization (GRPO), often manifesting as a trade-off between reasoning plasticity and general capability retention. We identify a root cause as the geometric conflict between plasticity and stability gradients, which leads to destructive interference. Crucially, we argue that deterministic projection methods are suboptimal for GRPO as they overlook the intrinsic stochasticity of group-based gradient estimates. To address this, we propose Probabilistic Conflict Resolution (PCR), a Bayesian framework that models gradients as random variables. PCR dynamically arbitrates conflicts via an uncertainty-aware ``soft projection'' mechanism, optimizing the signal-to-noise ratio. Extensive experiments demonstrate that PCR significantly smooths the training trajectory and achieves superior performance in various reasoning tasks.