Uniform Spectral Growth and Convergence of Muon in LoRA-Style Matrix Factorization
作者: Changmin Kang, Jihun Yun, Baekrok Shin, Yeseul Cho, Chulhee Yun
分类: cs.LG
发布日期: 2026-02-06
💡 一句话要点
提出均匀谱增长与收敛机制以优化LoRA风格矩阵分解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 谱梯度下降 低秩适应 矩阵分解 全局收敛 优化算法 大语言模型 奇异值分析
📋 核心要点
- 现有的优化方法在大语言模型训练中动态特性不明确,导致性能提升受限。
- 本文提出了谱梯度流(SpecGF)作为SpecGD的连续时间类比,分析了其在LoRA风格矩阵分解中的表现。
- 实验结果表明,SpecGF在几乎所有初始化条件下均能收敛到全局最小值,且在引入正则化后效果更佳。
📝 摘要(中文)
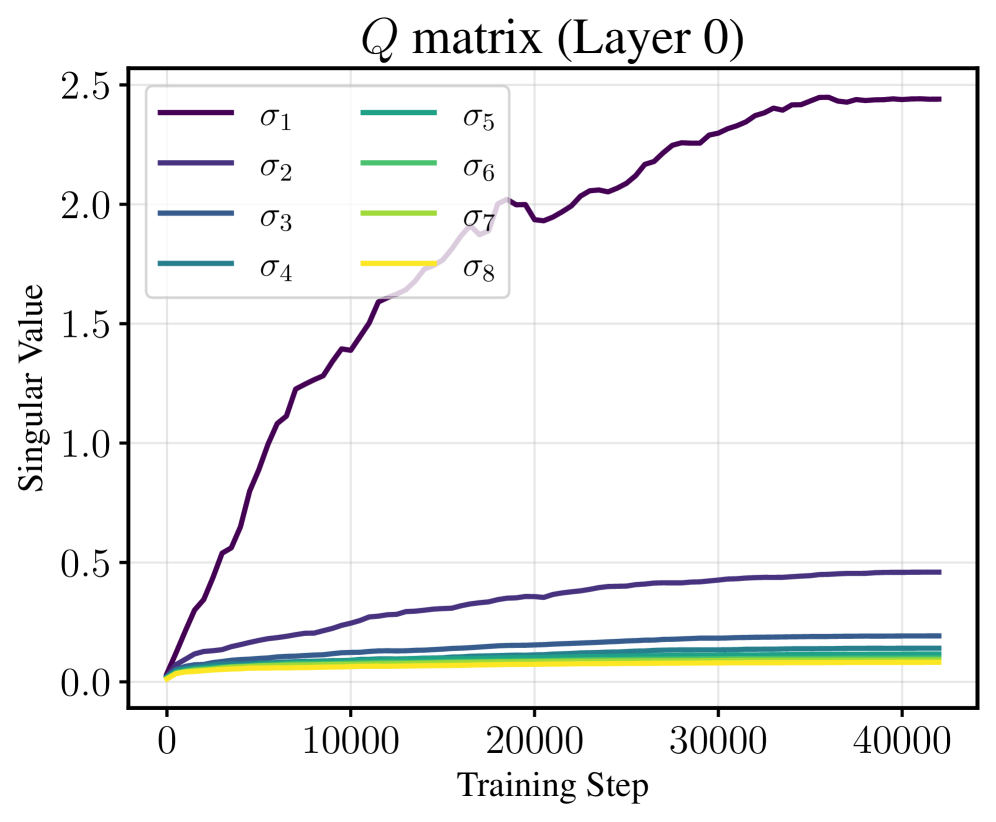
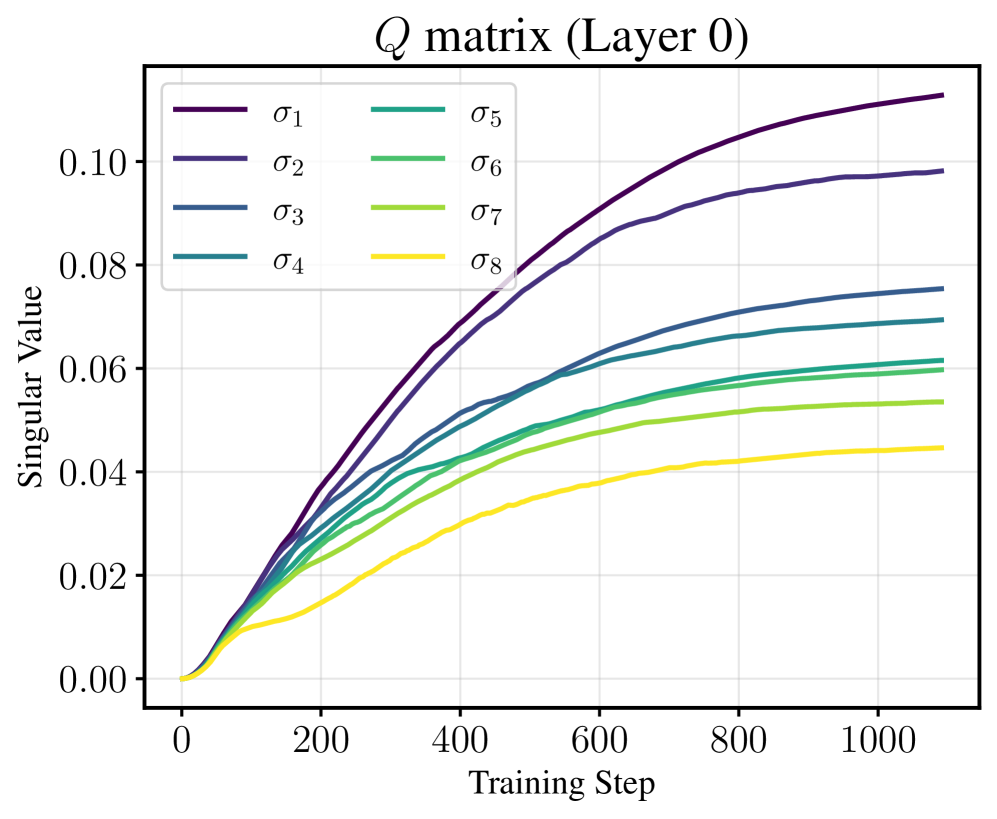
谱梯度下降(SpecGD)通过正交化矩阵参数更新,启发了如Muon等实用优化器,尽管在大语言模型(LLM)训练中表现良好,但其动态特性仍不够清晰。在低秩适应(LoRA)设置中,Muon在LLM微调中展现出独特的谱现象:尽管对两个因子分别进行正交化,LoRA乘积的奇异值却在谱上几乎均匀增长。基于此观察,本文分析了谱梯度流(SpecGF)在简化的LoRA风格矩阵分解中的表现,并证明了“等速”动态:所有奇异值以相同速率增长,较小的奇异值比较大的更早达到目标值。此外,本文还证明了在初始条件几乎全覆盖的情况下,SpecGF能够收敛到全局最小值,且在引入$ ext{l}_2$正则化后实现全局收敛。最后,实验验证了我们的理论。
🔬 方法详解
问题定义:本文旨在解决现有优化方法在大语言模型训练中的动态特性不明确的问题,尤其是在LoRA设置下的奇异值增长特性。
核心思路:通过分析谱梯度流(SpecGF),论文揭示了在LoRA风格矩阵分解中奇异值的均匀增长现象,提出了“等速”动态的概念。
技术框架:研究首先定义了LoRA风格的矩阵分解模型,然后引入谱梯度流的概念,分析其在该模型下的动态特性,最后通过理论证明和实验验证其收敛性。
关键创新:论文的主要创新在于揭示了在LoRA微调中奇异值的均匀增长特性,并证明了SpecGF在几乎所有初始化下的全局收敛性,这与传统的逐步学习方式形成鲜明对比。
关键设计:在模型设计中,采用了低秩因子化的方式来参数化权重更新,并引入了$ ext{l}_2$正则化以确保因子范数的有界性,从而实现全局收敛。实验中使用了标准的基线模型进行对比。
🖼️ 关键图片

📊 实验亮点
实验结果显示,谱梯度流在LoRA风格矩阵分解中实现了奇异值的均匀增长,且在引入$ ext{l}_2$正则化后,收敛速度显著提高,几乎所有初始化条件下均能达到全局最小值,验证了理论的有效性。
🎯 应用场景
该研究的潜在应用领域包括大语言模型的训练与优化,尤其是在需要高效参数更新和收敛性的场景中。通过改进优化算法,能够提升模型的训练效率和最终性能,具有重要的实际价值和未来影响。
📄 摘要(原文)
Spectral gradient descent (SpecGD) orthogonalizes the matrix parameter updates and has inspired practical optimizers such as Muon. They often perform well in large language model (LLM) training, but their dynamics remain poorly understood. In the low-rank adaptation (LoRA) setting, where weight updates are parameterized as a product of two low-rank factors, we find a distinctive spectral phenomenon under Muon in LoRA fine-tuning of LLMs: singular values of the LoRA product show near-uniform growth across the spectrum, despite orthogonalization being performed on the two factors separately. Motivated by this observation, we analyze spectral gradient flow (SpecGF)-a continuous-time analogue of SpecGD-in a simplified LoRA-style matrix factorization setting and prove "equal-rate" dynamics: all singular values grow at equal rates up to small deviations. Consequently, smaller singular values attain their target values earlier than larger ones, sharply contrasting with the largest-first stepwise learning observed in standard gradient flow. Moreover, we prove that SpecGF in our setting converges to global minima from almost all initializations, provided the factor norms remain bounded; with $\ell_2$ regularization, we obtain global convergence. Lastly, we corroborate our theory with experiments in the same setting.