Online Adaptive Reinforcement Learning with Echo State Networks for Non-Stationary Dynamics
作者: Aoi Yoshimura, Gouhei Tanaka
分类: cs.LG
发布日期: 2026-02-06
备注: Submitted to IJCNN 2026
💡 一句话要点
提出基于回声状态网络的在线自适应强化学习,解决非平稳动态环境下的控制问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 在线自适应 回声状态网络 储层计算 非平稳环境
📋 核心要点
- 现有强化学习方法在非平稳环境中泛化性差,领域随机化和元学习方法计算成本高,难以实时部署。
- 利用回声状态网络作为自适应模块,将观测历史编码为上下文表示,并使用递归最小二乘法在线更新权重。
- 实验表明,该方法在CartPole和HalfCheetah任务中,优于领域随机化等基线方法,实现了快速稳定的自适应。
📝 摘要(中文)
在模拟环境中训练的强化学习(RL)策略在部署到真实世界时,由于非平稳动态特性,性能通常会严重下降。虽然领域随机化(DR)和元学习(meta-RL)已被提出用于解决这个问题,但它们通常依赖于大量的预训练、特权信息或高计算成本,限制了它们在实时和边缘系统中的应用。本文提出了一种基于储层计算的轻量级在线自适应RL框架。具体来说,我们集成了一个回声状态网络(ESN)作为自适应模块,将最近的观测历史编码为潜在的上下文表示,并使用递归最小二乘法(RLS)在线更新其读出权重。这种设计无需反向传播、预训练或访问特权信息即可实现快速自适应。我们在CartPole和HalfCheetah任务上评估了所提出的方法,这些任务具有严重且突然的环境变化,包括周期性外部干扰和极端的摩擦变化。实验结果表明,所提出的方法在超出分布的动态下明显优于DR和代表性的自适应基线,在几个控制步骤内实现了稳定的自适应。值得注意的是,该方法成功地处理了episode内的环境变化,而无需重置策略。由于其计算效率和稳定性,所提出的框架为非平稳环境中的在线自适应提供了一种实用的解决方案,非常适合真实世界的机器人控制和边缘部署。
🔬 方法详解
问题定义:论文旨在解决强化学习策略在非平稳动态环境中部署时性能下降的问题。现有方法,如领域随机化和元学习,虽然可以提高泛化能力,但通常需要大量的预训练数据、特权信息或者计算资源,这限制了它们在实时性和资源受限的边缘设备上的应用。因此,如何在计算资源有限的情况下,使强化学习策略能够快速适应环境变化是一个关键挑战。
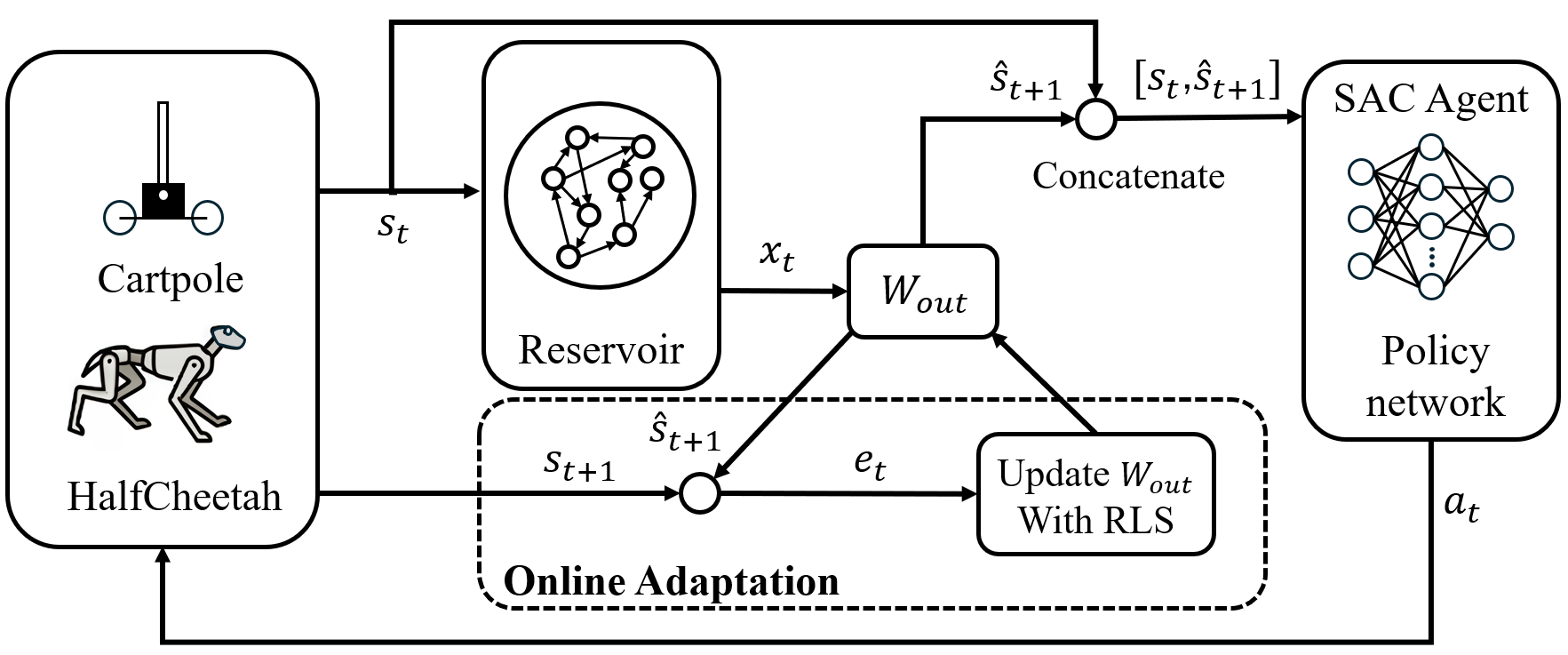
核心思路:论文的核心思路是利用储层计算(Reservoir Computing)的特性,特别是回声状态网络(ESN),来实现强化学习策略的在线自适应。ESN能够将历史观测信息编码成一个低维的上下文向量,并且可以通过简单的线性回归方法快速更新其输出权重,从而实现策略的快速调整。这种方法避免了复杂的反向传播过程,降低了计算复杂度,使其更适合在线学习和实时控制。
技术框架:整体框架包含一个强化学习策略和一个基于ESN的自适应模块。强化学习策略负责根据当前状态和上下文向量选择动作。ESN接收环境的观测作为输入,并将其编码成一个上下文向量,该向量与状态一起输入到强化学习策略中。ESN的读出权重使用递归最小二乘法(RLS)在线更新,以适应环境的变化。整个过程无需预训练,可以直接在真实环境中进行在线学习。
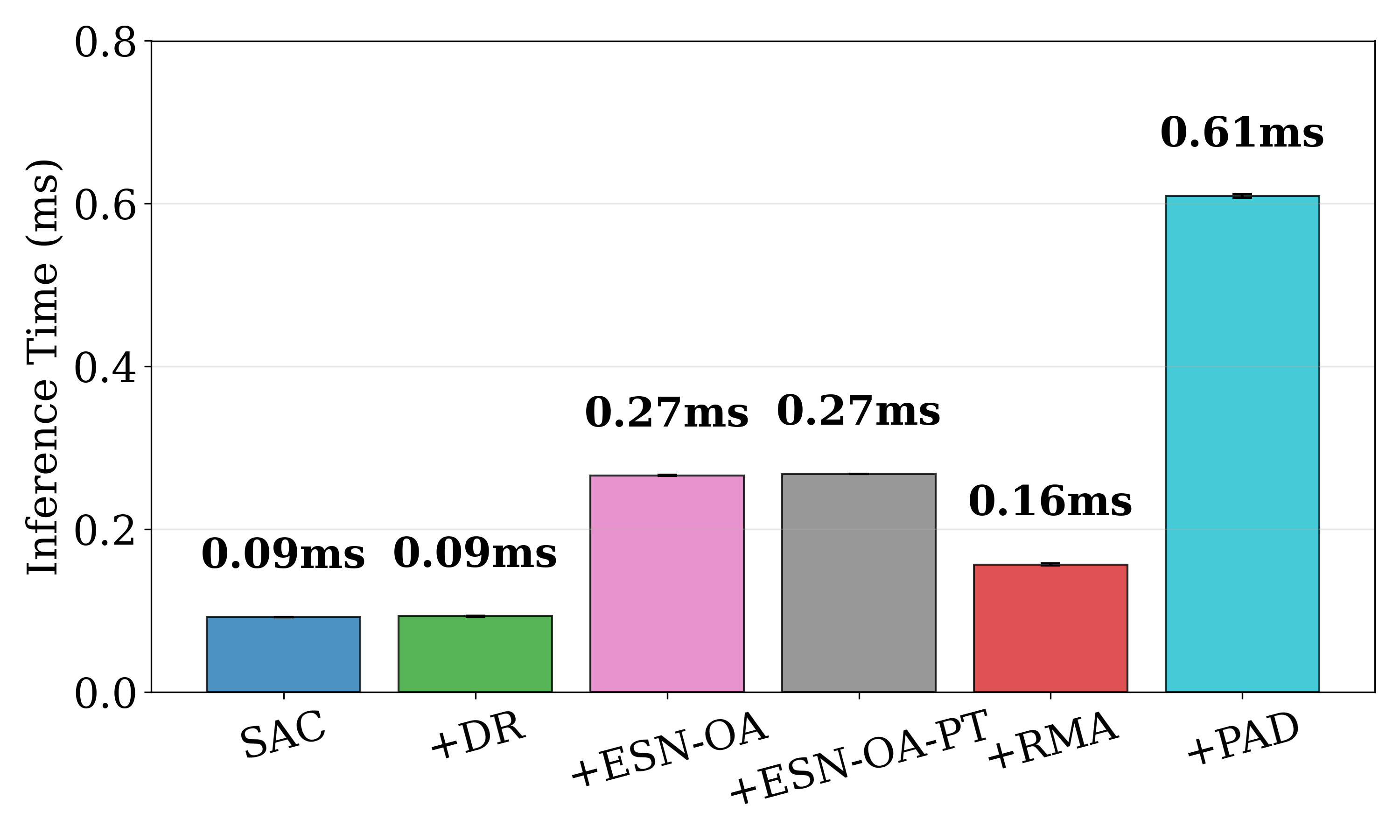
关键创新:该论文的关键创新在于将回声状态网络与强化学习相结合,提出了一种轻量级的在线自适应框架。与传统的领域随机化和元学习方法相比,该方法不需要大量的预训练数据和计算资源,并且能够快速适应环境的变化。此外,该方法还能够处理episode内的环境变化,而无需重置策略。
关键设计:ESN的网络结构包括一个随机初始化的循环神经网络(储层)和一个线性读出层。储层的权重保持固定,只有读出层的权重需要更新。递归最小二乘法(RLS)被用于在线更新读出权重,其更新速度快,计算复杂度低。论文中还详细描述了ESN的参数设置,例如储层的大小、谱半径等,以及RLS算法的学习率等参数。
🖼️ 关键图片
📊 实验亮点
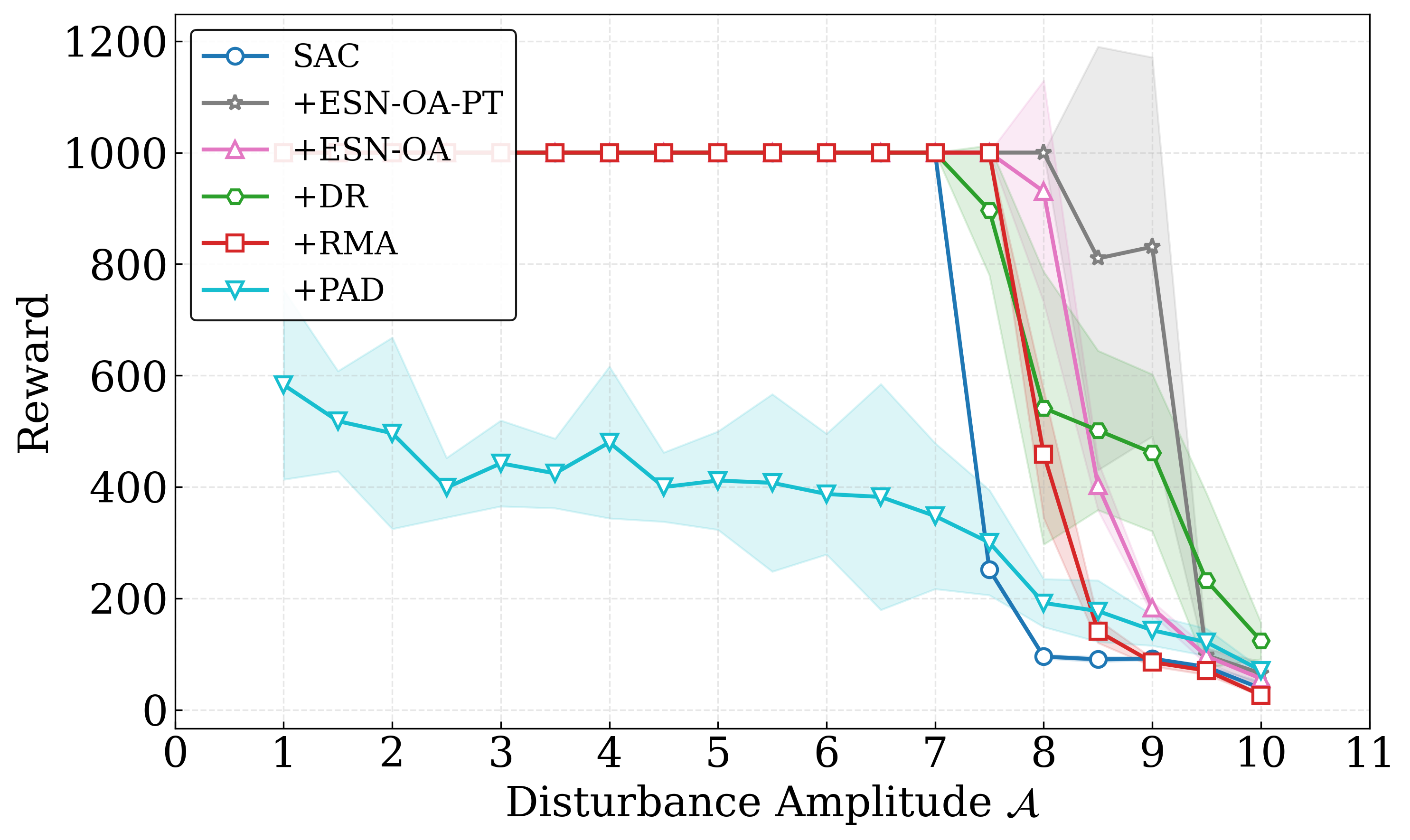
实验结果表明,该方法在CartPole和HalfCheetah任务中,面对剧烈的环境变化(如周期性干扰和摩擦变化),显著优于领域随机化(DR)和其他自适应基线方法。该方法能够在几个控制步骤内实现稳定的自适应,并且能够处理episode内的环境变化,而无需重置策略。在非平稳动态环境下,该方法表现出更强的鲁棒性和适应性。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、智能制造等领域,尤其适用于环境动态变化且计算资源受限的场景。例如,在机器人控制中,可以使机器人快速适应不同的地形和负载;在自动驾驶中,可以使车辆适应不同的交通状况和天气条件。该方法具有很高的实际应用价值,有望推动强化学习在真实世界中的广泛应用。
📄 摘要(原文)
Reinforcement learning (RL) policies trained in simulation often suffer from severe performance degradation when deployed in real-world environments due to non-stationary dynamics. While Domain Randomization (DR) and meta-RL have been proposed to address this issue, they typically rely on extensive pretraining, privileged information, or high computational cost, limiting their applicability to real-time and edge systems. In this paper, we propose a lightweight online adaptation framework for RL based on Reservoir Computing. Specifically, we integrate an Echo State Networks (ESNs) as an adaptation module that encodes recent observation histories into a latent context representation, and update its readout weights online using Recursive Least Squares (RLS). This design enables rapid adaptation without backpropagation, pretraining, or access to privileged information. We evaluate the proposed method on CartPole and HalfCheetah tasks with severe and abrupt environment changes, including periodic external disturbances and extreme friction variations. Experimental results demonstrate that the proposed approach significantly outperforms DR and representative adaptive baselines under out-of-distribution dynamics, achieving stable adaptation within a few control steps. Notably, the method successfully handles intra-episode environment changes without resetting the policy. Due to its computational efficiency and stability, the proposed framework provides a practical solution for online adaptation in non-stationary environments and is well suited for real-world robotic control and edge deployment.