Diffusion Model's Generalization Can Be Characterized by Inductive Biases toward a Data-Dependent Ridge Manifold
作者: Ye He, Yitong Qiu, Molei Tao
分类: stat.ML, cs.LG, math.NA, math.PR
发布日期: 2026-02-05
💡 一句话要点
提出基于数据依赖脊流形的扩散模型泛化能力表征方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 泛化能力 脊流形 归纳偏置 生成模型
📋 核心要点
- 现有方法缺乏对扩散模型泛化能力的定量理解,难以评估其在下游任务中的性能。
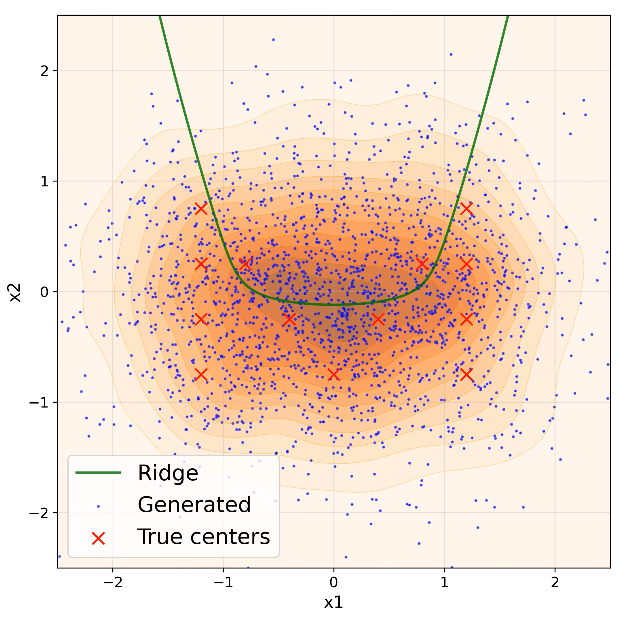
- 论文提出对数密度脊流形,将扩散模型的推理过程描述为围绕该流形的“到达-对齐-滑动”过程。
- 实验结果表明,该方法能够有效表征扩散模型的生成归纳偏置,并在合成数据和MNIST数据集上验证了其有效性。
📝 摘要(中文)
本文旨在量化理解扩散模型的泛化能力,而非仅仅关注其是否记忆训练数据。为此,论文提出了一种对数密度脊流形的概念,并量化了生成数据在推理过程中与该流形的关系。推理过程被描述为围绕脊流形的“到达-对齐-滑动”过程:轨迹首先到达流形附近,然后在法线方向上对齐(被推向或远离流形),最后在切线方向上沿流形滑动。不同的训练误差会导致不同的法线和切线运动,这些运动可以被量化,并用于描述多模态生成的出现。通过更深入地理解训练动态,可以更准确地量化生成归纳偏置。论文以随机特征模型为例,阐述了扩散模型的归纳偏置如何源于架构偏置和训练精度的组合,以及它们如何随推理动态演变。在合成多模态分布和 MNIST 潜在扩散上的实验验证了预测的方向性效应,包括低维和高维情况。
🔬 方法详解
问题定义:现有方法难以定量理解扩散模型的泛化能力,无法准确评估其在下游任务中的性能表现。简单地判断模型是否记忆训练数据是不够的,需要更细致地刻画模型生成的分布特性。
核心思路:论文的核心思路是将扩散模型的生成过程与一个数据相关的“脊流形”联系起来。该脊流形代表了数据分布的某种内在结构,而扩散模型的生成过程可以被分解为围绕该流形的三个阶段:到达(reach)、对齐(align)和滑动(slide)。通过分析这三个阶段的动态行为,可以量化地描述扩散模型的生成偏置。
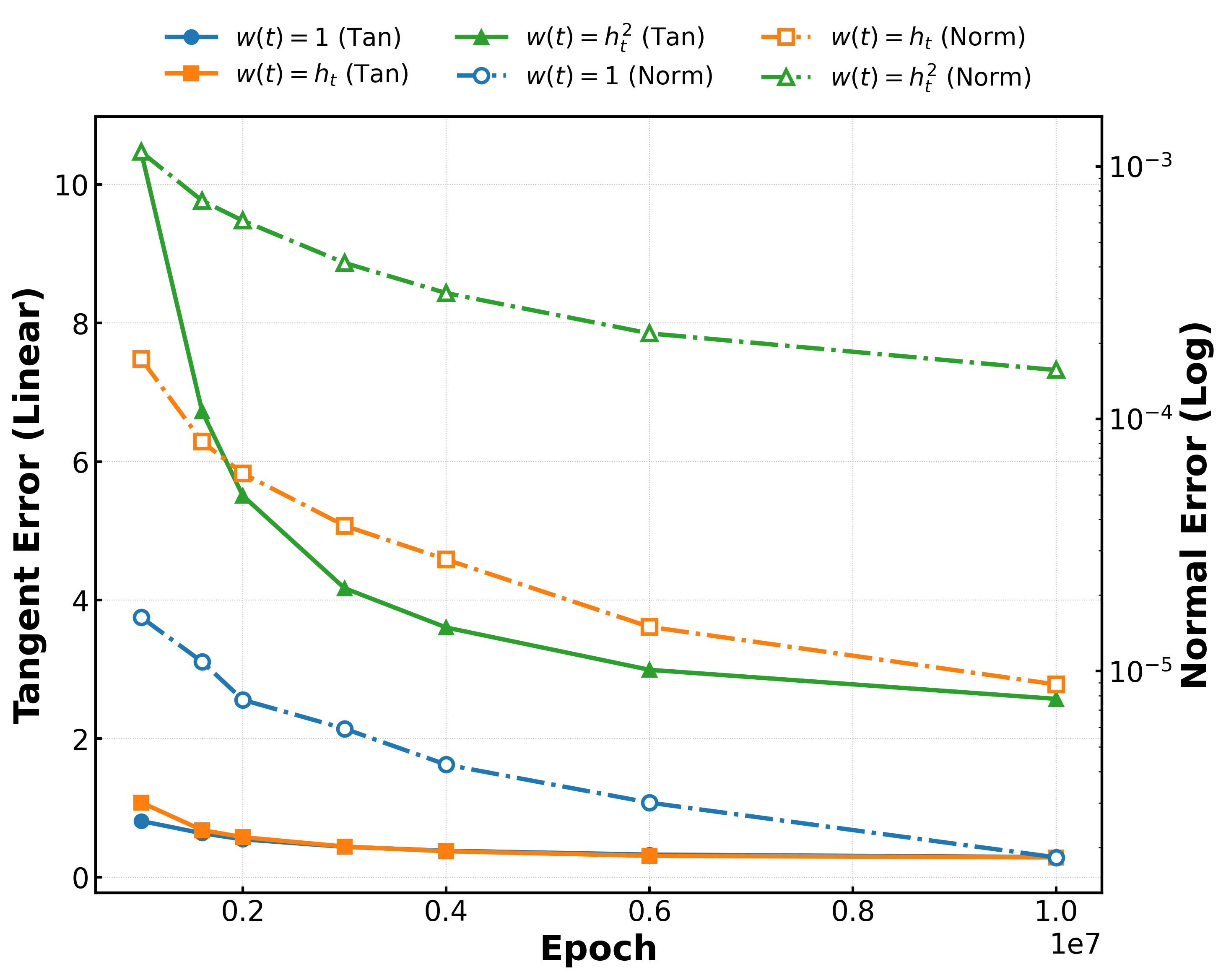
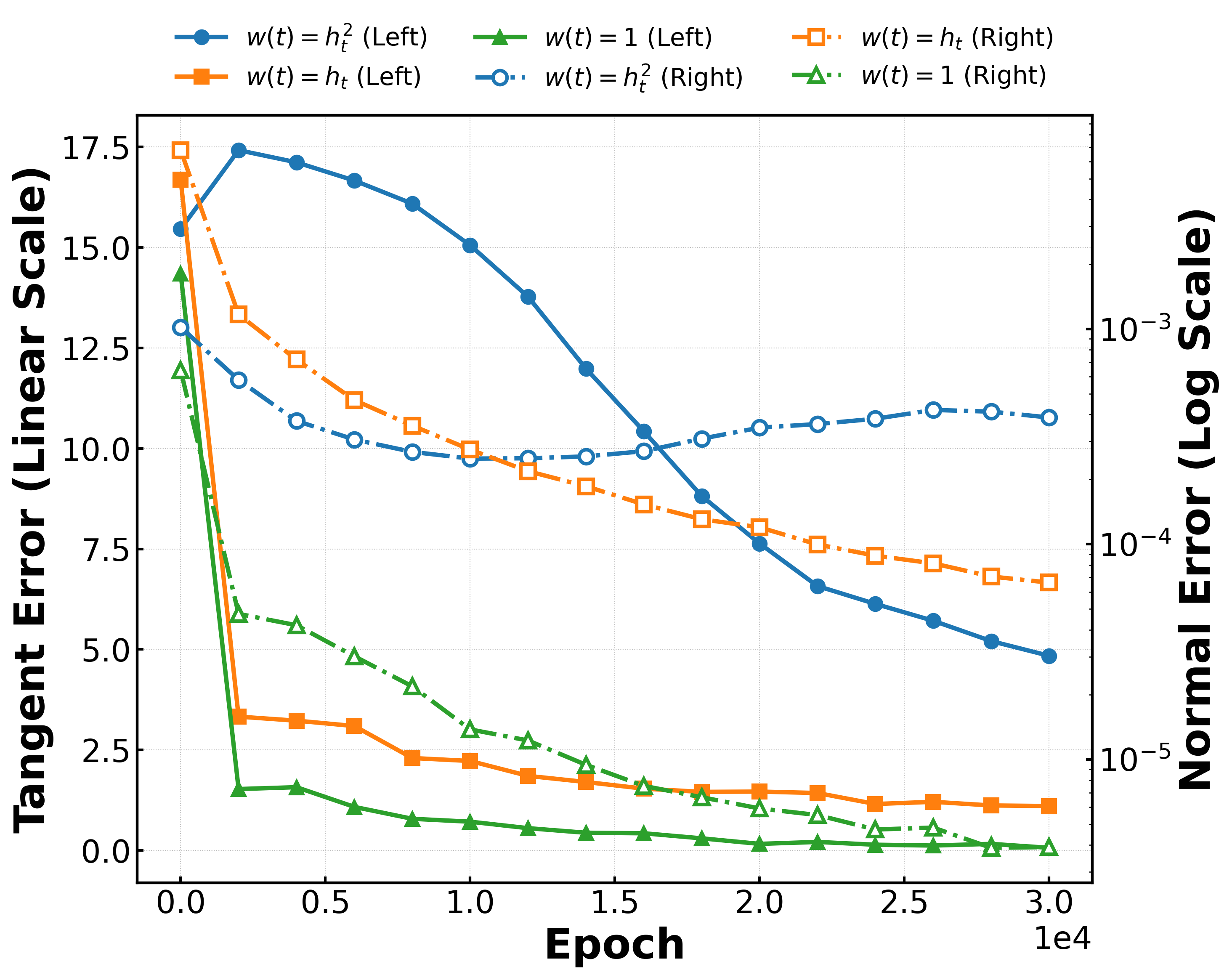
技术框架:整体框架包含以下几个关键步骤:1) 定义对数密度脊流形;2) 将扩散模型的推理过程分解为“到达-对齐-滑动”三个阶段;3) 建立训练误差与法线和切线运动之间的关系;4) 利用随机特征模型分析架构偏置和训练精度如何影响生成偏置;5) 通过实验验证理论分析的有效性。
关键创新:最重要的创新在于提出了对数密度脊流形的概念,并将其与扩散模型的生成过程联系起来。这种方法提供了一种新的视角来理解扩散模型的泛化能力,并能够定量地描述模型的生成偏置。与现有方法相比,该方法更加细致和深入,能够揭示扩散模型生成过程中的内在机制。
关键设计:论文的关键设计包括:1) 对数密度脊流形的具体定义;2) “到达-对齐-滑动”三个阶段的数学描述;3) 训练误差与法线和切线运动之间关系的建模;4) 随机特征模型的选择和分析;5) 实验数据的选择和评估指标的设计。
🖼️ 关键图片
📊 实验亮点
论文在合成多模态分布和 MNIST 潜在扩散上进行了实验,验证了所提出的理论框架的有效性。实验结果表明,扩散模型的生成过程确实可以被分解为围绕脊流形的“到达-对齐-滑动”三个阶段,并且不同的训练误差会导致不同的法线和切线运动。这些实验结果为理解扩散模型的泛化能力提供了重要的实证支持。
🎯 应用场景
该研究成果可应用于评估扩散模型在各种下游任务中的性能,例如图像生成、文本生成和音频生成。通过理解扩散模型的生成偏置,可以更好地控制生成结果的质量和多样性。此外,该研究还可以为设计更有效的扩散模型提供理论指导,例如通过调整架构偏置或训练策略来改善模型的泛化能力。
📄 摘要(原文)
When a diffusion model is not memorizing the training data set, how does it generalize exactly? A quantitative understanding of the distribution it generates would be beneficial to, for example, an assessment of the model's performance for downstream applications. We thus explicitly characterize what diffusion model generates, by proposing a log-density ridge manifold and quantifying how the generated data relate to this manifold as inference dynamics progresses. More precisely, inference undergoes a reach-align-slide process centered around the ridge manifold: trajectories first reach a neighborhood of the manifold, then align as being pushed toward or away from the manifold in normal directions, and finally slide along the manifold in tangent directions. Within the scope of this general behavior, different training errors will lead to different normal and tangent motions, which can be quantified, and these detailed motions characterize when inter-mode generations emerge. More detailed understanding of training dynamics will lead to more accurate quantification of the generation inductive bias, and an example of random feature model will be considered, for which we can explicitly illustrate how diffusion model's inductive biases originate as a composition of architectural bias and training accuracy, and how they evolve with the inference dynamics. Experiments on synthetic multimodal distributions and MNIST latent diffusion support the predicted directional effects, in both low- and high-dimensions.