Layer-wise LoRA fine-tuning: a similarity metric approach
作者: Keith Ando Ogawa, Bruno Lopes Yamamoto, Lucas Lauton de Alcantara, Lucas Pellicer, Rosimeire Pereira Costa, Edson Bollis, Anna Helena Reali Costa, Artur Jordao
分类: cs.LG
发布日期: 2026-02-05
备注: Code is available at https://github.com/c2d-usp/Layer-wise-LoRA-with-CKA
🔗 代码/项目: GITHUB
💡 一句话要点
提出层级LoRA微调方法,通过相似性度量选择关键层,降低计算成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩适应 层选择 相似性度量 大规模语言模型
📋 核心要点
- 现有LoRA方法在LLM规模持续增长的情况下,参数缩减可能不足,微调成本依然较高。
- 通过测量各层对内部表示变化的贡献,选择对模型适应最关键的层进行LoRA微调。
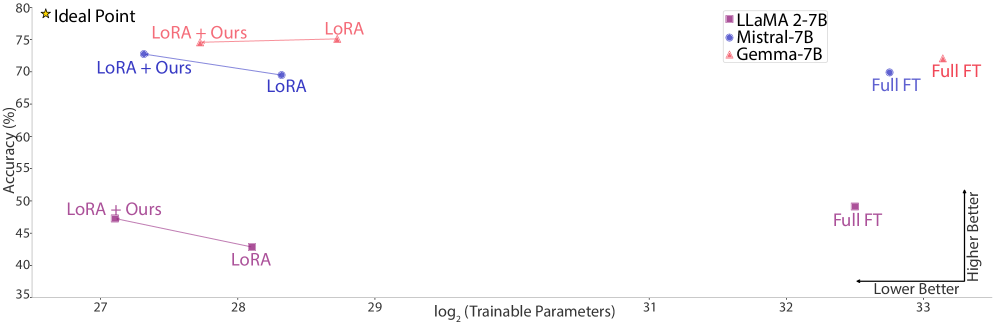
- 实验表明,该方法能在保持或提升预测性能的同时,显著减少可训练参数,最高达50%。
📝 摘要(中文)
预训练大规模语言模型(LLMs)在网络规模数据集上已成为推动通用人工智能的基础。相比之下,提高它们在下游任务上的预测性能通常涉及通过微调来调整它们的知识。低秩适应(LoRA)等参数高效微调技术旨在通过冻结预训练模型并更新较少数量的参数来降低此过程的计算成本。与完全微调相比,这些方法在可训练参数数量上实现了超过99%的减少,具体取决于配置。不幸的是,随着LLM规模的持续增长,这种减少可能不足。在这项工作中,我们通过系统地选择少量层来使用LoRA或其变体进行微调,从而解决了先前的问题。我们认为并非所有层都对模型适应做出同等贡献。利用这一点,我们通过测量它们对内部表示变化的贡献来识别最相关的微调层。我们的方法与现有的低秩适应技术正交且易于兼容。我们在基于LoRA的技术中将可训练参数减少了高达50%,同时保持了不同模型和任务中的预测性能。具体而言,在仅编码器架构上,这种可训练参数的减少导致GLUE基准上的预测性能下降可忽略不计。在仅解码器架构上,我们在数学问题解决能力和编码任务上实现了较小的下降甚至改进。最后,这种有效性扩展到多模态模型,对于这些模型,我们还观察到相对于在所有层中使用LoRA模块进行微调的具有竞争力的结果。
🔬 方法详解
问题定义:论文旨在解决大规模语言模型(LLM)微调过程中计算成本过高的问题。现有的参数高效微调方法,如LoRA,虽然能显著减少可训练参数的数量,但随着LLM规模的不断扩大,其参数缩减效果可能不足以满足实际需求,导致微调过程仍然耗时耗力。此外,现有方法通常对所有层进行微调,忽略了不同层对模型适应的贡献差异。
核心思路:论文的核心思路是选择性地对LLM中的部分层进行LoRA微调,而不是对所有层都进行微调。作者认为,并非所有层都对模型适应做出同等贡献,因此可以通过识别并仅微调那些对模型性能影响最大的层,从而进一步降低计算成本。这种选择性微调的策略能够更有效地利用计算资源,并在保持甚至提升模型性能的同时,减少需要训练的参数数量。
技术框架:该方法主要包含以下几个阶段: 1. 基线模型:使用预训练好的LLM作为基础模型。 2. 相似性度量:使用相似性度量(例如,Centered Kernel Alignment, CKA)来衡量不同层对内部表示变化的贡献。具体而言,通过比较微调前后各层输出的相似性,来评估该层对模型适应的重要性。 3. 层选择:根据相似性度量的结果,选择对模型适应贡献最大的若干层进行LoRA微调。选择策略可以是选择相似性变化最大的前N层,或者设置一个阈值,选择变化超过阈值的层。 4. LoRA微调:对选定的层应用LoRA微调技术,冻结预训练模型的原始参数,仅更新LoRA模块的参数。 5. 模型评估:在下游任务上评估微调后的模型性能。
关键创新:该方法最重要的技术创新点在于提出了基于相似性度量的层选择策略。与现有方法对所有层进行微调不同,该方法能够根据各层对模型适应的贡献程度,选择性地进行微调,从而更有效地利用计算资源,并在保持甚至提升模型性能的同时,减少需要训练的参数数量。这种方法与现有的LoRA技术正交,可以很容易地集成到现有的微调流程中。
关键设计: * 相似性度量:论文使用了Centered Kernel Alignment (CKA) 作为相似性度量指标,用于衡量不同层对内部表示变化的贡献。CKA能够捕捉不同层输出之间的相似性,从而评估该层对模型适应的重要性。 * 层选择策略:论文采用了一种简单的层选择策略,即选择CKA值变化最大的前N层进行微调。也可以根据实际情况,设置一个CKA变化阈值,选择变化超过阈值的层。 * LoRA配置:LoRA模块的秩(rank)是一个重要的超参数,需要根据具体任务和模型进行调整。论文中可能使用了不同的LoRA秩值,并进行了实验对比。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在encoder-only架构上,可将可训练参数减少高达50%,同时在GLUE基准上的预测性能下降可忽略不计。在decoder-only架构上,该方法在数学问题解决能力和编码任务上实现了小幅下降甚至性能提升。对于多模态模型,该方法也取得了与在所有层使用LoRA模块进行微调相媲美的结果。
🎯 应用场景
该研究成果可广泛应用于各种需要对大规模语言模型进行微调的场景,例如自然语言处理、计算机视觉、语音识别等。通过选择性地微调关键层,可以显著降低微调成本,提高微调效率,使得在资源受限的环境下也能有效地利用LLM。此外,该方法还可以应用于多模态模型的微调,进一步拓展了其应用范围。
📄 摘要(原文)
Pre-training Large Language Models (LLMs) on web-scale datasets becomes fundamental for advancing general-purpose AI. In contrast, enhancing their predictive performance on downstream tasks typically involves adapting their knowledge through fine-tuning. Parameter-efficient fine-tuning techniques, such as Low-Rank Adaptation (LoRA), aim to reduce the computational cost of this process by freezing the pre-trained model and updating a smaller number of parameters. In comparison to full fine-tuning, these methods achieve over 99\% reduction in trainable parameter count, depending on the configuration. Unfortunately, such a reduction may prove insufficient as LLMs continue to grow in scale. In this work, we address the previous problem by systematically selecting only a few layers to fine-tune using LoRA or its variants. We argue that not all layers contribute equally to the model adaptation. Leveraging this, we identify the most relevant layers to fine-tune by measuring their contribution to changes in internal representations. Our method is orthogonal to and readily compatible with existing low-rank adaptation techniques. We reduce the trainable parameters in LoRA-based techniques by up to 50\%, while maintaining the predictive performance across different models and tasks. Specifically, on encoder-only architectures, this reduction in trainable parameters leads to a negligible predictive performance drop on the GLUE benchmark. On decoder-only architectures, we achieve a small drop or even improvements in the predictive performance on mathematical problem-solving capabilities and coding tasks. Finally, this effectiveness extends to multimodal models, for which we also observe competitive results relative to fine-tuning with LoRA modules in all layers. Code is available at: https://github.com/c2d-usp/Layer-wise-LoRA-with-CKA