Inverse Depth Scaling From Most Layers Being Similar
作者: Yizhou Liu, Sara Kangaslahti, Ziming Liu, Jeff Gore
分类: cs.LG, cs.AI, math.DS, stat.ML
发布日期: 2026-02-05
备注: 23 pages, 24 figures
💡 一句话要点
发现LLM深度与损失反比关系,源于相似层集成平均而非组合学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 深度学习 缩放定律 残差网络 集成平均
📋 核心要点
- 大型语言模型中,模型深度和宽度对性能的影响机制尚不明确,需要更细致的研究。
- 论文发现LLM损失与深度成反比,推测是由于相似层通过集成平均降低误差,而非组合学习。
- 研究表明残差网络的架构偏置和目标函数可能是导致这种低效但鲁棒的深度利用方式的原因。
📝 摘要(中文)
神经缩放定律描述了大型语言模型(LLM)中损失与模型大小的关系,但深度和宽度可能对性能有不同的影响,需要更详细的研究。本文通过分析LLM和玩具残差网络,量化了深度如何影响损失。研究发现,LLM中的损失与深度成反比,这可能是由于功能相似的层通过集成平均来减少误差,而不是通过组合学习或离散化平滑动力学。这种机制效率低下但鲁棒性强,可能源于残差网络的架构偏置以及与平滑动力学不兼容的目标函数。研究结果表明,提高LLM的效率可能需要架构创新,以鼓励深度进行组合使用。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)的缩放定律研究主要关注模型大小与性能的关系,但忽略了模型深度和宽度对性能的差异化影响。现有的深度模型可能存在深度利用效率不高的问题,即简单地增加深度并不能带来预期的性能提升。
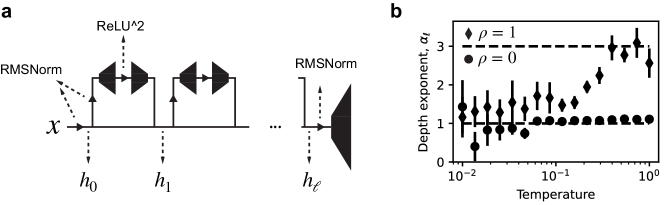
核心思路:论文的核心思路是通过分析LLM和简化的残差网络,研究模型深度对损失的影响。通过观察损失与深度的关系,推断模型如何利用深度来学习。核心假设是,如果模型中的层功能相似,那么增加深度可能只是起到集成平均的作用,而不是进行更复杂的组合学习。
技术框架:论文主要通过实验分析来验证其假设。首先,在大型语言模型上观察损失与深度的关系。然后,使用简化的残差网络进行控制变量实验,以排除其他因素的干扰。通过分析不同层之间的相似性,来验证层之间的功能相似性。最后,讨论了残差网络的架构偏置以及目标函数对深度利用方式的影响。
关键创新:论文的关键创新在于发现了LLM中损失与深度成反比的关系,并提出了这种关系可能是由于功能相似的层通过集成平均来减少误差。这个发现挑战了传统的深度学习观点,即深度应该用于进行更复杂的组合学习。
关键设计:论文的关键设计包括:1) 使用简化的残差网络进行控制变量实验,以排除其他因素的干扰。2) 分析不同层之间的相似性,以验证层之间的功能相似性。3) 讨论了残差网络的架构偏置以及目标函数对深度利用方式的影响。具体参数设置和网络结构细节在论文中未详细描述,属于实验的具体配置,但核心在于控制变量,观察深度与损失的关系。
🖼️ 关键图片


📊 实验亮点
研究发现,在大型语言模型中,损失与深度成反比。这意味着简单地增加模型深度可能并不能带来预期的性能提升,反而可能导致效率下降。这一发现挑战了传统的深度学习观点,并为未来的模型设计提供了新的方向。
🎯 应用场景
该研究成果可应用于指导大型语言模型的架构设计,通过鼓励深度进行组合使用,提高模型的效率和性能。此外,该研究也为理解深度学习模型的内部机制提供了新的视角,有助于开发更有效的训练方法和模型压缩技术。未来的研究可以探索如何设计新的架构,以克服残差网络的架构偏置,并鼓励深度进行更有效的组合学习。
📄 摘要(原文)
Neural scaling laws relate loss to model size in large language models (LLMs), yet depth and width may contribute to performance differently, requiring more detailed studies. Here, we quantify how depth affects loss via analysis of LLMs and toy residual networks. We find loss scales inversely proportional to depth in LLMs, probably due to functionally similar layers reducing error through ensemble averaging rather than compositional learning or discretizing smooth dynamics. This regime is inefficient yet robust and may arise from the architectural bias of residual networks and target functions incompatible with smooth dynamics. The findings suggest that improving LLM efficiency may require architectural innovations to encourage compositional use of depth.