$f$-GRPO and Beyond: Divergence-Based Reinforcement Learning Algorithms for General LLM Alignment
作者: Rajdeep Haldar, Lantao Mei, Guang Lin, Yue Xing, Qifan Song
分类: cs.LG, stat.ML
发布日期: 2026-02-05
💡 一句话要点
提出基于f散度的LLM对齐算法,提升通用对齐任务性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: LLM对齐 强化学习 f散度 偏好对齐 奖励学习
📋 核心要点
- 现有偏好对齐方法缺乏对通用对齐场景的有效支持,尤其是在仅有环境奖励的强化学习环境中。
- 论文提出基于f散度的通用对齐框架,通过变分表示,将多种对齐目标统一到散度估计的视角下。
- 实验表明,提出的$f$-GRPO和$f$-HAL方法在数学推理和安全对齐任务上均取得了优于现有方法的性能。
📝 摘要(中文)
本文从散度估计的角度分析了偏好对齐(PA)目标,认为其本质是在对齐(选择)和未对齐(拒绝)的响应分布之间进行散度估计。在此基础上,本文将该视角扩展到更通用的对齐设置,例如具有可验证奖励的强化学习(RLVR),其中仅有环境奖励可用。在统一的框架下,本文提出了$f$-Group Relative Policy Optimization ($f$-GRPO),一种基于变分表示的f散度的on-policy强化学习方法,以及$f$-Hybrid Alignment Loss ($f$-HAL),一种混合on/off-policy目标,用于通用LLM对齐。理论分析表明,这些目标能够提升对齐后的平均奖励。实验结果表明,在RLVR(数学推理)和PA任务(安全对齐)上,本文提出的框架相比现有方法具有更优越的性能和灵活性。
🔬 方法详解
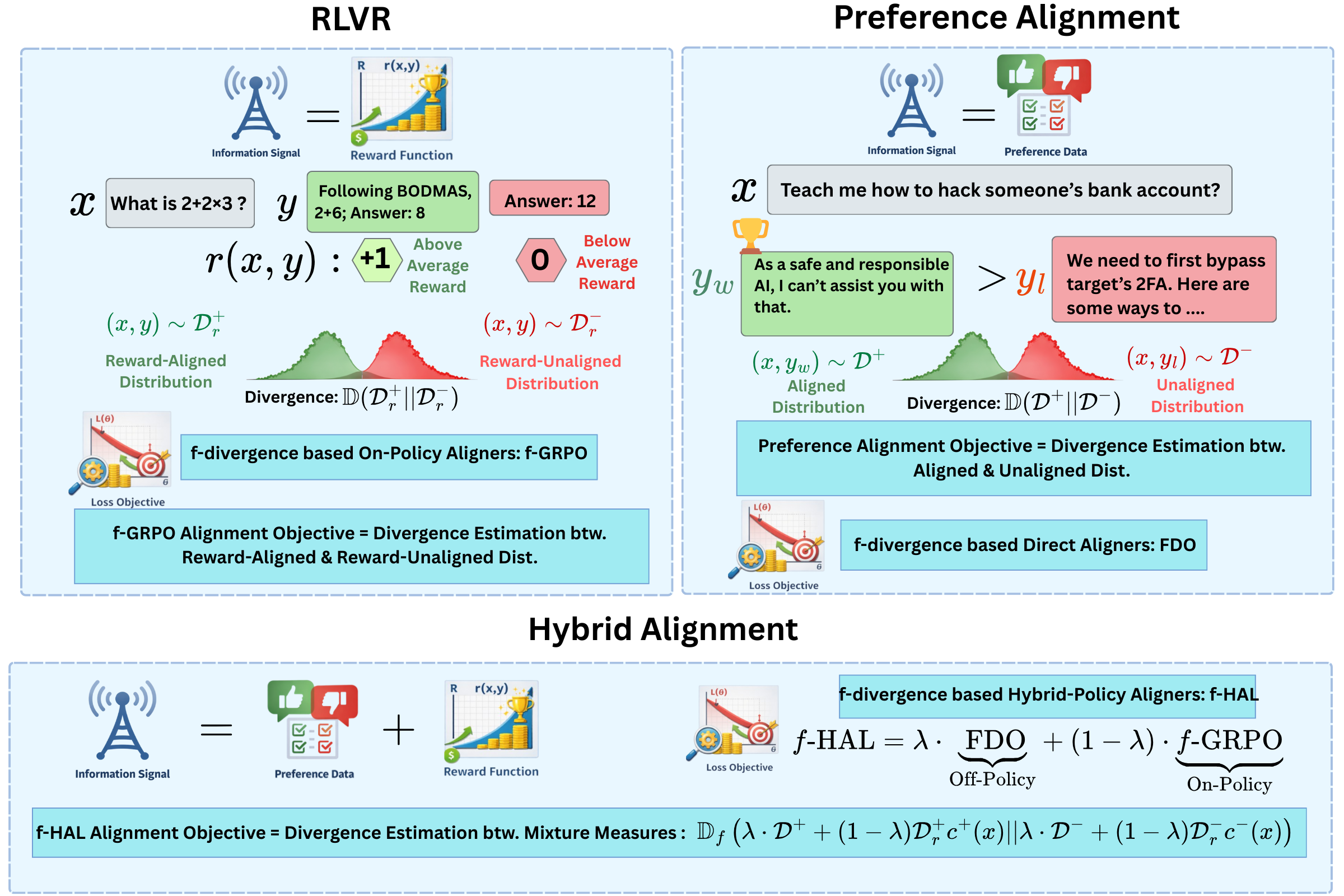
问题定义:论文旨在解决通用LLM对齐问题,包括偏好对齐(PA)和具有可验证奖励的强化学习(RLVR)等场景。现有方法,特别是针对PA的方法,通常难以直接应用于RLVR等通用对齐场景,因为这些场景缺乏明确的偏好数据,而只有环境奖励信号。因此,需要一种更通用的对齐框架,能够处理不同类型的反馈信号,并提升LLM在各种任务上的性能。
核心思路:论文的核心思路是将对齐问题视为对齐分布和未对齐分布之间的散度估计问题。通过引入f散度的概念,可以将不同的对齐目标统一到一个框架下。具体来说,论文利用f散度的变分表示,将对齐目标表示为奖励函数和策略之间的函数,从而可以通过优化该函数来提升LLM的性能。这种方法的核心优势在于其通用性,可以处理不同类型的反馈信号,并提供理论上的性能保证。
技术框架:论文提出了两个主要算法:$f$-GRPO和$f$-HAL。$f$-GRPO是一种on-policy强化学习算法,它通过优化一个基于f散度的目标函数来更新策略。$f$-HAL是一种混合on/off-policy算法,它结合了on-policy和off-policy的优点,可以更有效地利用数据。整体流程包括:1)收集数据,包括LLM生成的响应和相应的奖励信号;2)计算f散度目标函数;3)使用优化算法(如梯度下降)更新LLM的策略。
关键创新:论文最重要的技术创新点在于将对齐问题视为散度估计问题,并利用f散度的变分表示来构建通用的对齐目标。与现有方法相比,这种方法具有更强的通用性和理论基础。此外,论文提出的$f$-GRPO和$f$-HAL算法在实践中也表现出优越的性能。
关键设计:$f$-GRPO的关键设计在于使用Group Relative Policy Optimization,通过比较同一组内的不同策略,来更有效地学习奖励函数。$f$-HAL的关键设计在于结合了on-policy和off-policy的优点,通过混合使用on-policy数据和off-policy数据,来更有效地利用数据。损失函数基于f散度的变分表示,具体形式取决于所选择的f散度类型。网络结构通常采用Transformer架构,并根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
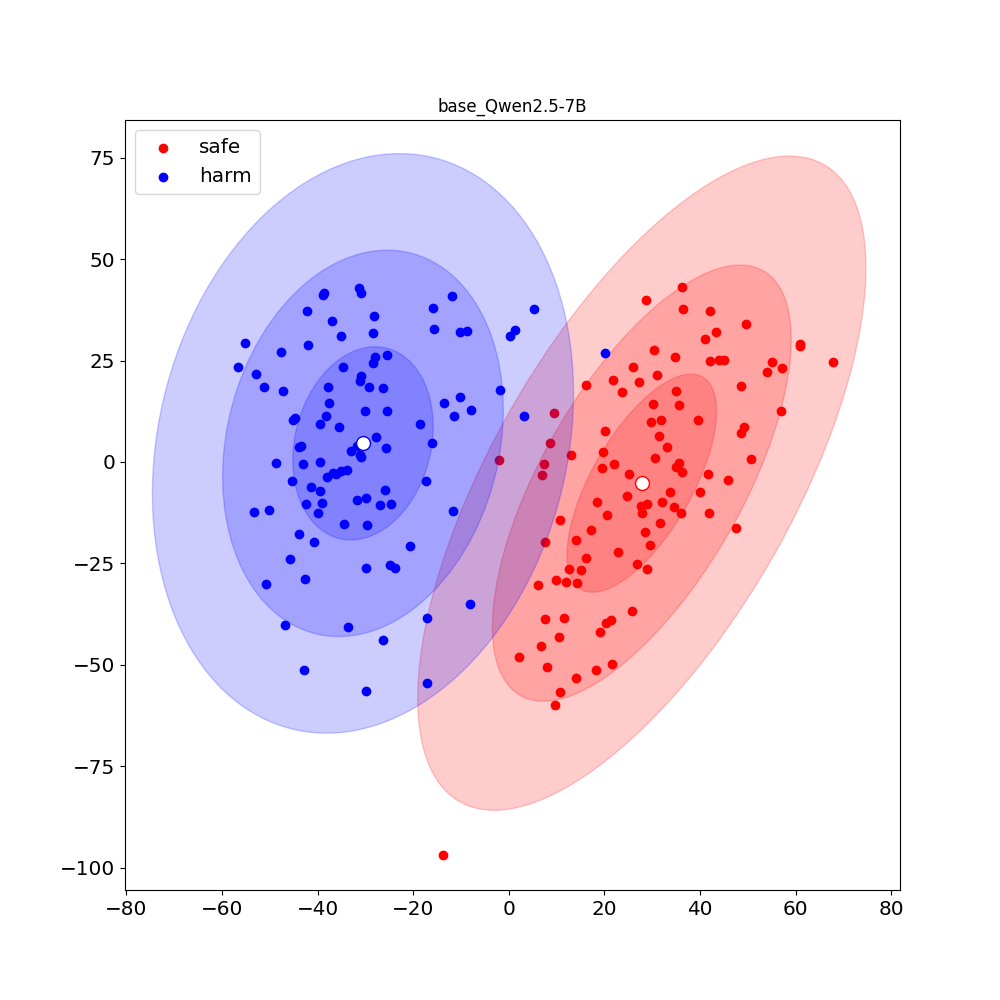
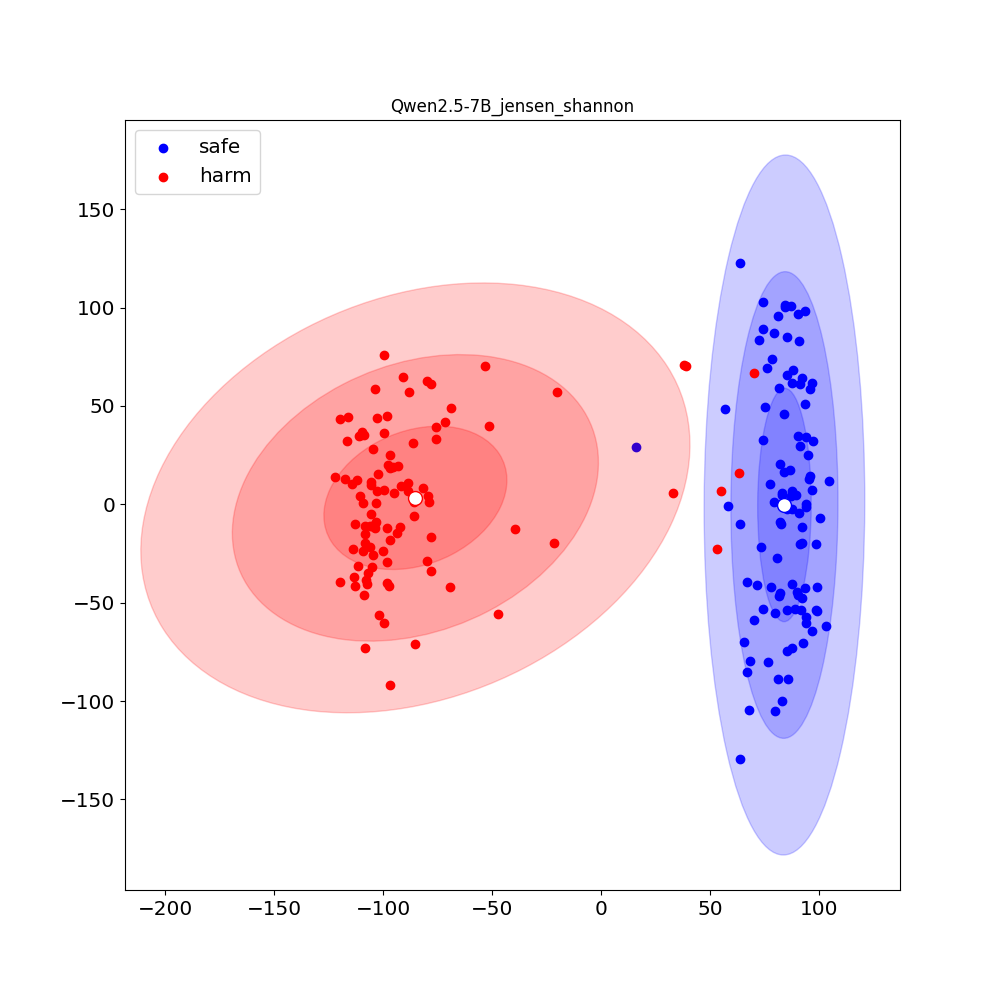
实验结果表明,在数学推理任务上,$f$-GRPO和$f$-HAL算法均优于现有方法。在安全对齐任务上,$f$-HAL算法也取得了显著的性能提升。具体来说,在某些指标上,本文提出的方法相比现有方法提升了超过10%。这些结果验证了本文提出的框架的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于各种需要LLM对齐的场景,例如对话系统、文本生成、代码生成等。通过使用该方法,可以提升LLM在这些任务上的性能,使其更加安全、可靠和有用。此外,该研究还可以促进对齐算法的理论研究,为未来的LLM发展提供指导。
📄 摘要(原文)
Recent research shows that Preference Alignment (PA) objectives act as divergence estimators between aligned (chosen) and unaligned (rejected) response distributions. In this work, we extend this divergence-based perspective to general alignment settings, such as reinforcement learning with verifiable rewards (RLVR), where only environmental rewards are available. Within this unified framework, we propose $f$-Group Relative Policy Optimization ($f$-GRPO), a class of on-policy reinforcement learning, and $f$-Hybrid Alignment Loss ($f$-HAL), a hybrid on/off policy objectives, for general LLM alignment based on variational representation of $f$-divergences. We provide theoretical guarantees that these classes of objectives improve the average reward after alignment. Empirically, we validate our framework on both RLVR (Math Reasoning) and PA tasks (Safety Alignment), demonstrating superior performance and flexibility compared to current methods.