Verification of the Implicit World Model in a Generative Model via Adversarial Sequences
作者: András Balogh, Márk Jelasity
分类: cs.LG, cs.AI
发布日期: 2026-02-05
备注: Accepted at ICLR 2026. Code, datasets, and models are available at https://github.com/szegedai/world-model-verification
💡 一句话要点
提出对抗序列生成方法,用于验证生成模型在国际象棋领域的隐式世界模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 生成模型 对抗序列生成 可靠性验证 国际象棋 隐式世界模型
📋 核心要点
- 现有生成序列模型难以保证其“可靠性”,即生成的所有序列都符合规则,尤其是在复杂规则的领域。
- 提出对抗序列生成方法,通过构造特定序列来诱导模型生成无效的下一步预测,从而验证模型的可靠性。
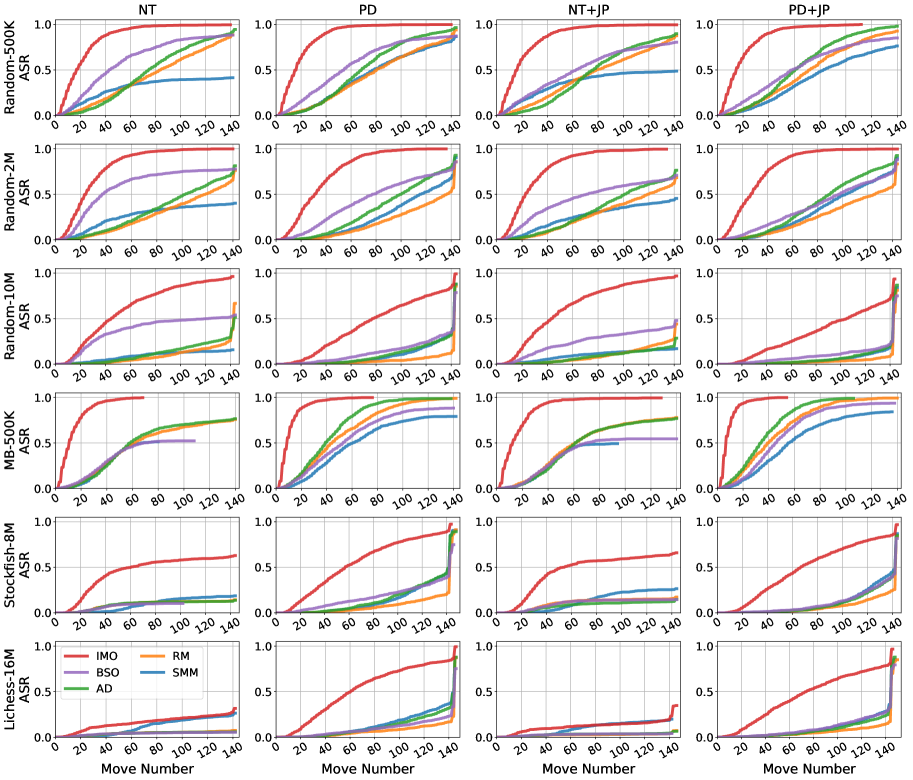
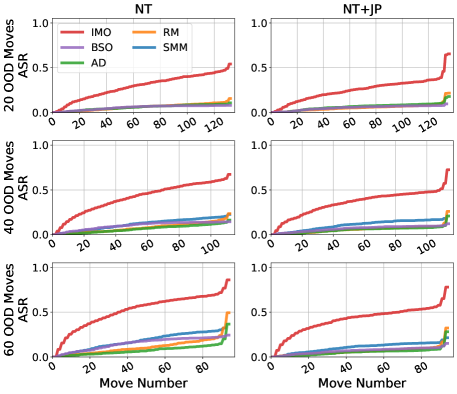
- 在国际象棋领域验证了该方法,发现现有模型均不完全可靠,但特定训练技巧和数据集选择可以显著提高可靠性。
📝 摘要(中文)
生成序列模型通常在自然或形式语言的样本序列上进行训练。一个关键问题是,基于样本的训练是否能够捕捉到这些语言的真实结构,即所谓的“世界模型”,以及在多大程度上能够捕捉到。理论结果表明,我们最多只能期望模型具有可靠性,即生成有效的序列,但不一定能生成所有有效的序列。然而,拥有能够验证给定序列模型是否可靠的实用工具仍然很重要。本研究侧重于国际象棋,因为它提供足够的复杂性,同时具有简单的基于规则的世界模型。我们提出对抗序列生成方法来验证序列模型的可靠性。我们的对抗者生成有效的序列,以迫使序列模型生成无效的下一步预测。除了验证可靠性之外,该方法还适用于对失败模式和训练期间不同选择的影响进行更细粒度的分析。为了证明这一点,我们提出了许多对抗序列生成方法,并在大量的国际象棋模型上评估了该方法。我们使用多种训练方法在随机和高质量的国际象棋游戏上训练模型。我们发现没有一个模型是完全可靠的,但一些训练技术和数据集选择能够显著提高可靠性。我们还研究了棋盘状态探针在我们训练和攻击方法中的潜在应用。我们的研究结果表明,在大多数模型中,提取的棋盘状态在下一步预测中没有因果作用。
🔬 方法详解
问题定义:论文旨在解决生成序列模型在复杂规则领域(如国际象棋)中的可靠性验证问题。现有方法难以有效验证模型是否能够始终生成符合规则的序列,即模型是否真正学习到了“世界模型”。现有方法的痛点在于缺乏一种系统性的方法来发现模型可能出错的边界情况。
核心思路:论文的核心思路是通过对抗的方式来验证模型的可靠性。具体来说,设计一个“对抗者”,其目标是生成一系列合法的棋局序列,使得被测试的生成模型在预测下一步棋时出错,即生成不合法的棋步。如果对抗者能够成功诱导模型出错,则说明该模型不完全可靠。
技术框架:整体框架包含两个主要部分:1) 序列生成模型:使用神经网络模型(具体模型结构未知)学习国际象棋棋局序列的生成;2) 对抗序列生成器:设计不同的策略来生成棋局序列,目标是最大化生成模型预测错误的可能性。对抗序列生成器与序列生成模型进行交互,不断调整生成的序列,直到找到能够诱导模型出错的序列。
关键创新:论文的关键创新在于提出了对抗序列生成这一概念,并将其应用于生成模型的可靠性验证。与传统的评估方法不同,该方法不是简单地评估模型在随机数据上的表现,而是主动寻找模型的弱点,从而更有效地发现模型可能存在的错误。
关键设计:论文设计了多种对抗序列生成策略(具体策略细节未知),并探索了棋盘状态探针的应用。棋盘状态探针旨在提取棋盘的抽象表示,并将其作为模型的输入,以提高模型的可靠性。此外,论文还研究了不同的训练方法和数据集选择对模型可靠性的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使在国际象棋这一规则明确的领域,现有的生成模型也难以保证完全可靠。通过对抗序列生成方法,可以有效地发现模型的错误,并评估不同训练技巧和数据集选择对模型可靠性的影响。研究发现,某些训练技巧和数据集选择可以显著提高模型的可靠性,但没有一个模型能够完全避免错误。此外,研究还发现,提取的棋盘状态在大多数模型中对下一步预测没有显著的因果作用。
🎯 应用场景
该研究提出的对抗序列生成方法可应用于各种生成模型的可靠性验证,尤其是在规则复杂的领域,如编程语言生成、自然语言生成等。通过系统性地发现模型的弱点,可以帮助开发者改进模型的设计和训练,提高模型的可靠性和安全性。该方法还可用于评估不同训练策略和数据集对模型性能的影响。
📄 摘要(原文)
Generative sequence models are typically trained on sample sequences from natural or formal languages. It is a crucial question whether -- or to what extent -- sample-based training is able to capture the true structure of these languages, often referred to as the ``world model''. Theoretical results indicate that we can hope for soundness at best, that is, generating valid sequences, but not necessarily all of them. However, it is still important to have practical tools that are able to verify whether a given sequence model is sound. In this study, we focus on chess, as it is a domain that provides enough complexity while having a simple rule-based world model. We propose adversarial sequence generation for verifying the soundness of the sequence model. Our adversaries generate valid sequences so as to force the sequence model to generate an invalid next move prediction. Apart from the falsification of soundness, this method is also suitable for a more fine-grained analysis of the failure modes and the effects of different choices during training. To demonstrate this, we propose a number of methods for adversarial sequence generation and evaluate the approach on a large set of chess models. We train models on random as well as high-quality chess games, using several training recipes. We find that none of the models are sound, but some training techniques and dataset choices are able to improve soundness remarkably. We also investigate the potential application of board state probes in both our training and attack methods. Our findings indicate that the extracted board states have no causal role in next token prediction in most of the models.