Regularized Calibration with Successive Rounding for Post-Training Quantization
作者: Seohyeon Cha, Huancheng Chen, Dongjun Kim, Haoran Zhang, Kevin Chan, Gustavo de Veciana, Haris Vikalo
分类: cs.LG, cs.AI
发布日期: 2026-02-05
💡 一句话要点
提出基于正则化校准和逐次舍入的后训练量化方法,提升大语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后训练量化 大语言模型 模型压缩 正则化校准 逐次舍入 低比特量化 量化算法
📋 核心要点
- 现有后训练量化方法在激活不匹配时鲁棒性不足,且量化目标和舍入过程的设计存在挑战。
- 通过在对称和非对称校准间插值实现正则化,并提出逐次舍入过程,有效提升量化性能。
- 实验表明,该方法在多个LLM和基准测试中,均优于现有PTQ方法,且计算成本可控。
📝 摘要(中文)
大型语言模型(LLM)在各种应用中表现出色,但存储和访问数十亿参数的内存和延迟成本带来了部署挑战。后训练量化(PTQ)通过将预训练权重映射到低比特格式来实现高效推理,而无需重新训练,但其有效性关键取决于量化目标和用于获得低比特权重表示的舍入过程。本文表明,在对称和非对称校准之间进行插值可以作为一种正则化形式,在PTQ中保留标准二次结构,同时提供对激活不匹配的鲁棒性。在此基础上,我们推导出一种简单的逐次舍入过程,该过程自然地结合了非对称校准,以及一种有界搜索扩展,允许在量化质量和计算成本之间进行显式权衡。跨多个LLM系列、量化比特宽度和基准的实验表明,所提出的基于正则化非对称校准目标和有界搜索的方法,始终优于PTQ基线,并在困惑度和准确性方面有所提高,同时仅产生适度和可控的额外计算成本。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的后训练量化(PTQ)问题。现有的PTQ方法,尤其是在低比特量化时,容易受到激活不匹配的影响,导致性能下降。此外,如何设计有效的量化目标和舍入策略,以在量化精度和计算成本之间取得平衡,也是一个重要的挑战。
核心思路:论文的核心思路是引入正则化校准,通过在对称和非对称校准之间进行插值,来提高PTQ的鲁棒性。同时,提出一种逐次舍入过程,该过程能够自然地结合非对称校准,并允许在量化质量和计算成本之间进行权衡。这种方法旨在更好地适应激活分布的变化,并优化量化后的权重表示。
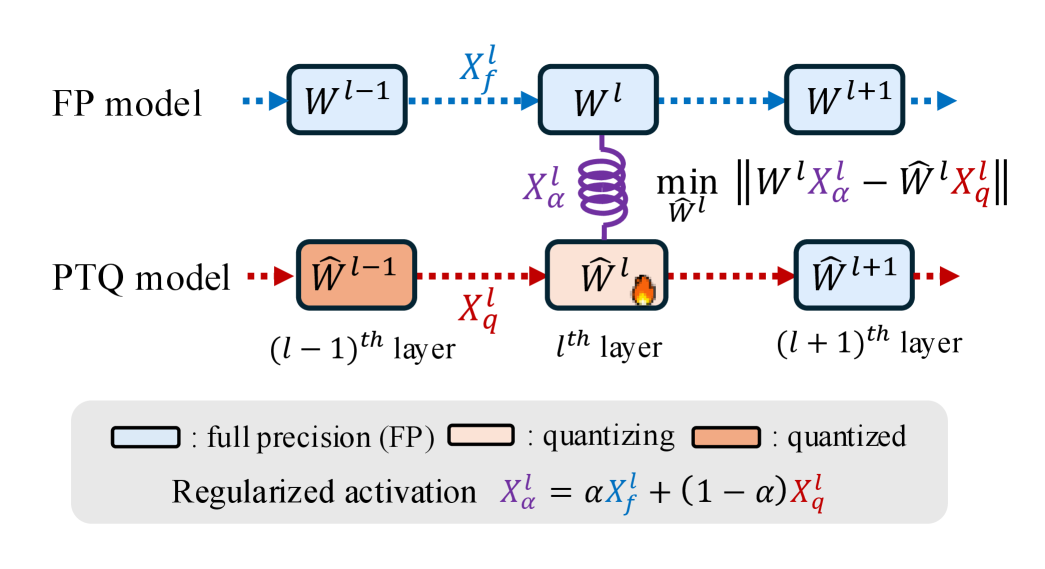
技术框架:该方法主要包含两个关键部分:正则化校准和逐次舍入。首先,通过在对称和非对称校准之间进行插值,得到一个正则化的量化目标。然后,使用逐次舍入过程,将权重逐步量化到目标比特宽度。此外,还引入了一个有界搜索扩展,用于在量化质量和计算成本之间进行权衡。整体流程包括:预训练模型 -> 正则化校准 -> 逐次舍入 -> 量化后的模型。
关键创新:该方法最重要的技术创新点在于正则化校准和逐次舍入的结合。正则化校准通过在对称和非对称校准之间进行插值,提高了PTQ的鲁棒性。逐次舍入过程能够自然地结合非对称校准,并允许在量化质量和计算成本之间进行权衡。与现有方法相比,该方法能够更好地适应激活分布的变化,并优化量化后的权重表示。
关键设计:正则化校准的关键在于插值系数的选择,该系数控制了对称和非对称校准之间的平衡。逐次舍入过程的关键在于每一步的舍入策略,以及如何有效地搜索最佳的量化值。有界搜索扩展的关键在于如何定义搜索空间和搜索策略,以在量化质量和计算成本之间取得平衡。损失函数采用标准的二次结构,以保证优化过程的稳定性和效率。
🖼️ 关键图片

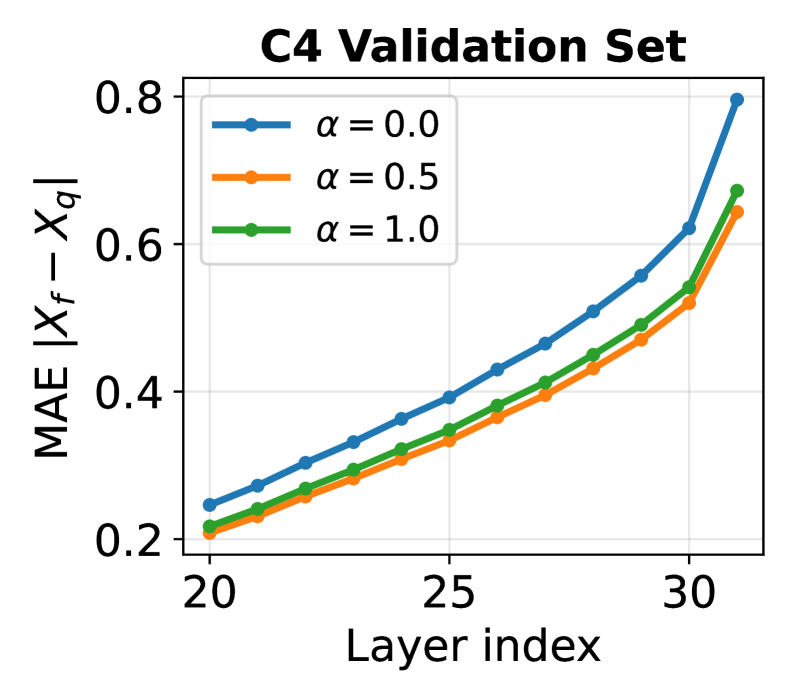
📊 实验亮点
实验结果表明,该方法在多个LLM系列、量化比特宽度和基准测试中,均优于现有的PTQ基线。例如,在某些模型上,该方法可以将困惑度降低显著,同时保持较高的准确率。此外,该方法的计算成本可控,使其在实际应用中具有很高的可行性。
🎯 应用场景
该研究成果可广泛应用于需要部署大型语言模型的场景,例如移动设备、边缘计算设备等资源受限的环境。通过降低模型大小和推理延迟,可以提升用户体验,并降低部署成本。此外,该方法还可以应用于其他类型的深度学习模型,具有广泛的应用前景。
📄 摘要(原文)
Large language models (LLMs) deliver robust performance across diverse applications, yet their deployment often faces challenges due to the memory and latency costs of storing and accessing billions of parameters. Post-training quantization (PTQ) enables efficient inference by mapping pretrained weights to low-bit formats without retraining, but its effectiveness depends critically on both the quantization objective and the rounding procedure used to obtain low-bit weight representations. In this work, we show that interpolating between symmetric and asymmetric calibration acts as a form of regularization that preserves the standard quadratic structure used in PTQ while providing robustness to activation mismatch. Building on this perspective, we derive a simple successive rounding procedure that naturally incorporates asymmetric calibration, as well as a bounded-search extension that allows for an explicit trade-off between quantization quality and the compute cost. Experiments across multiple LLM families, quantization bit-widths, and benchmarks demonstrate that the proposed bounded search based on a regularized asymmetric calibration objective consistently improves perplexity and accuracy over PTQ baselines, while incurring only modest and controllable additional computational cost.