Dr. Kernel: Reinforcement Learning Done Right for Triton Kernel Generations
作者: Wei Liu, Jiawei Xu, Yingru Li, Longtao Zheng, Tianjian Li, Qian Liu, Junxian He
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-05
💡 一句话要点
提出Dr. Kernel,利用强化学习优化Triton内核生成,性能超越现有LLM。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 内核生成 Triton 大型语言模型 奖励入侵 惰性优化 KernelGYM
📋 核心要点
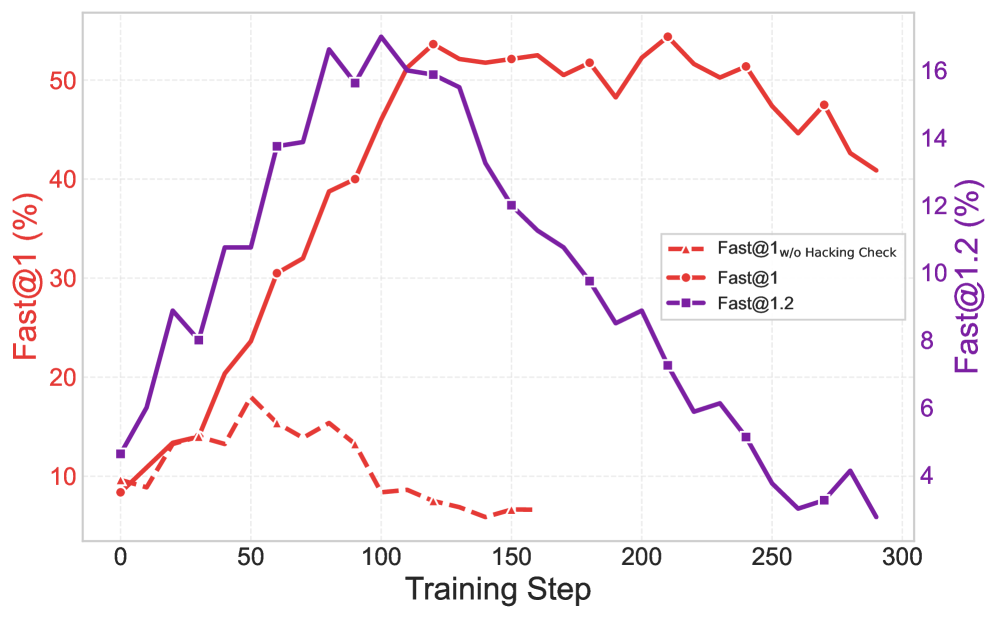
- 现有方法在利用LLM生成高性能内核时,面临数据不足、环境脆弱、易受奖励入侵和惰性优化等挑战。
- 论文提出KernelGYM环境和TRLOO、PR、PRS等方法,解决多轮RL训练中的偏差、惰性优化等问题,提升内核生成质量。
- 实验结果表明,Dr.Kernel-14B在KernelBench上性能与Claude-4.5-Sonnet相当,部分测试中超越了Claude-4.5-Sonnet和GPT-5。
📝 摘要(中文)
高质量的内核对于可扩展的AI系统至关重要,而使LLM能够生成此类代码将推动AI发展。然而,训练LLM完成此任务需要充足的数据、强大的环境,并且该过程容易受到奖励入侵和惰性优化的影响。在这些情况下,模型可能会入侵训练奖励,并优先考虑微不足道的正确性而非有意义的加速。本文系统地研究了用于内核生成的强化学习(RL)。首先,我们设计了KernelGYM,这是一个强大的分布式GPU环境,支持奖励入侵检查、来自多轮交互的数据收集和长期RL训练。基于KernelGYM,我们研究了有效的多轮RL方法,并确定了由GRPO中的自我包含引起的有偏策略梯度问题。为了解决这个问题,我们提出了Turn-level Reinforce-Leave-One-Out(TRLOO),为多轮RL提供无偏的优势估计。为了缓解惰性优化,我们结合了不匹配校正以提高训练稳定性,并引入了基于分析的奖励(PR)和基于分析的拒绝采样(PRS)来克服这个问题。训练后的模型Dr.Kernel-14B在Kernelbench中达到了与Claude-4.5-Sonnet竞争的性能。最后,我们研究了Dr.Kernel-14B的顺序测试时缩放。在KernelBench Level-2子集上,31.6%生成的内核实现了比Torch参考至少1.2倍的加速,超过了Claude-4.5-Sonnet(26.7%)和GPT-5(28.6%)。当选择所有轮次中最佳候选者时,这种1.2倍的加速率进一步提高到47.8%。所有资源,包括环境、训练代码、模型和数据集,都包含在https://www.github.com/hkust-nlp/KernelGYM中。
🔬 方法详解
问题定义:论文旨在解决如何利用大型语言模型(LLM)生成高性能的Triton内核代码的问题。现有方法在训练LLM生成内核时,面临着数据量不足、训练环境不稳定、容易出现奖励入侵和惰性优化等问题。奖励入侵指的是模型通过一些非预期的方式获得高奖励,而惰性优化指的是模型只关注于快速达到基本正确,而忽略了性能优化。这些问题导致生成的内核代码质量不高,无法充分发挥硬件性能。
核心思路:论文的核心思路是利用强化学习(RL)来训练LLM,使其能够生成高性能的内核代码。为了解决RL训练中遇到的问题,论文提出了KernelGYM环境,用于提供稳定可靠的训练环境,并提出了TRLOO、PR和PRS等方法,用于解决RL训练中的偏差、惰性优化等问题。通过这些方法,可以有效地训练LLM,使其能够生成高质量的内核代码。
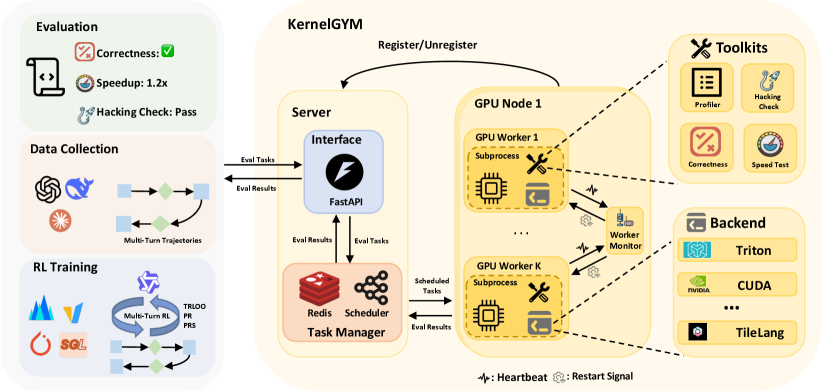
技术框架:整体框架包括以下几个主要模块:1) KernelGYM环境:提供一个分布式GPU环境,用于执行生成的内核代码,并评估其性能。该环境支持奖励入侵检查,确保模型不会通过非预期的方式获得高奖励。2) 多轮RL训练:使用多轮交互的方式训练LLM,使其能够逐步优化生成的内核代码。3) TRLOO:用于解决多轮RL训练中的偏差问题,提供无偏的优势估计。4) PR和PRS:用于缓解惰性优化问题,鼓励模型生成高性能的内核代码。
关键创新:论文的关键创新点在于:1) KernelGYM环境:提供了一个稳定可靠的训练环境,解决了现有方法中环境脆弱的问题。2) TRLOO:提出了一种新的优势估计方法,解决了多轮RL训练中的偏差问题。3) PR和PRS:提出了一种新的奖励机制和采样方法,缓解了惰性优化问题。
关键设计:1) KernelGYM环境:采用分布式架构,支持大规模的并行训练。2) TRLOO:通过leave-one-out的方式,消除了自我包含带来的偏差。3) PR:基于内核的性能分析结果,设计奖励函数,鼓励模型生成高性能的内核代码。4) PRS:基于内核的性能分析结果,对生成的内核代码进行拒绝采样,只保留高性能的内核代码。
🖼️ 关键图片
📊 实验亮点
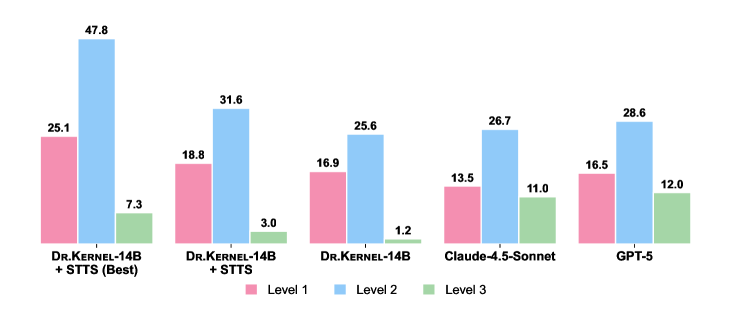
Dr.Kernel-14B在KernelBench Level-2子集上,31.6%生成的内核实现了比Torch参考至少1.2倍的加速,超过了Claude-4.5-Sonnet(26.7%)和GPT-5(28.6%)。当选择所有轮次中最佳候选者时,1.2倍加速率进一步提高到47.8%,表明该方法在内核生成方面具有显著优势。
🎯 应用场景
该研究成果可应用于各种需要高性能计算的领域,例如深度学习、科学计算、图像处理等。通过自动生成优化的内核代码,可以显著提升计算效率,降低开发成本。未来,该技术有望成为AI系统开发的重要工具,加速AI技术的普及和应用。
📄 摘要(原文)
High-quality kernel is critical for scalable AI systems, and enabling LLMs to generate such code would advance AI development. However, training LLMs for this task requires sufficient data, a robust environment, and the process is often vulnerable to reward hacking and lazy optimization. In these cases, models may hack training rewards and prioritize trivial correctness over meaningful speedup. In this paper, we systematically study reinforcement learning (RL) for kernel generation. We first design KernelGYM, a robust distributed GPU environment that supports reward hacking check, data collection from multi-turn interactions and long-term RL training. Building on KernelGYM, we investigate effective multi-turn RL methods and identify a biased policy gradient issue caused by self-inclusion in GRPO. To solve this, we propose Turn-level Reinforce-Leave-One-Out (TRLOO) to provide unbiased advantage estimation for multi-turn RL. To alleviate lazy optimization, we incorporate mismatch correction for training stability and introduce Profiling-based Rewards (PR) and Profiling-based Rejection Sampling (PRS) to overcome the issue. The trained model, Dr.Kernel-14B, reaches performance competitive with Claude-4.5-Sonnet in Kernelbench. Finally, we study sequential test-time scaling for Dr.Kernel-14B. On the KernelBench Level-2 subset, 31.6% of the generated kernels achieve at least a 1.2x speedup over the Torch reference, surpassing Claude-4.5-Sonnet (26.7%) and GPT-5 (28.6%). When selecting the best candidate across all turns, this 1.2x speedup rate further increases to 47.8%. All resources, including environment, training code, models, and dataset, are included in https://www.github.com/hkust-nlp/KernelGYM.