Constrained Group Relative Policy Optimization
作者: Roger Girgis, Rodrigue de Schaetzen, Luke Rowe, Azalée Robitaille, Christopher Pal, Liam Paull
分类: cs.LG, cs.CL, cs.RO
发布日期: 2026-02-05
备注: 16 pages, 6 figures
💡 一句话要点
提出Constrained GRPO,解决带约束的免Critic策略优化问题,提升机器人任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 约束强化学习 策略优化 拉格朗日方法 机器人控制 具身智能
📋 核心要点
- 现有Group Relative Policy Optimization (GRPO)方法在处理带显式行为约束的场景时存在不足,约束策略优化仍待探索。
- Constrained GRPO通过拉格朗日方法扩展GRPO,使用指示代价函数指定约束,直接优化违规率,实现约束策略优化。
- 实验表明,标量化优势构造能有效避免优化病理,恢复稳定约束控制,并在机器人任务中提升约束满足度和任务成功率。
📝 摘要(中文)
本文提出Constrained Group Relative Policy Optimization (GRPO),一种基于拉格朗日方法的GRPO扩展,用于约束策略优化。约束通过指示代价函数指定,从而可以通过拉格朗日松弛直接优化违规率。研究表明,在优势估计中采用朴素的多分量处理方式会破坏约束学习:不匹配的分量标准差会扭曲不同目标项的相对重要性,进而破坏拉格朗日信号,阻止有效的约束执行。论文形式化地推导了这种效应,并提出了标量化优势构造,以保持奖励和约束项之间预期的权衡。在玩具网格世界中的实验证实了预测的优化病理,并表明标量化优势可以恢复稳定的约束控制。此外,在机器人任务上评估了Constrained GRPO,它提高了约束满足度,同时增加了任务成功率,为具身人工智能领域中日益依赖大型多模态基础模型的约束策略优化建立了一个简单有效的方案。
🔬 方法详解
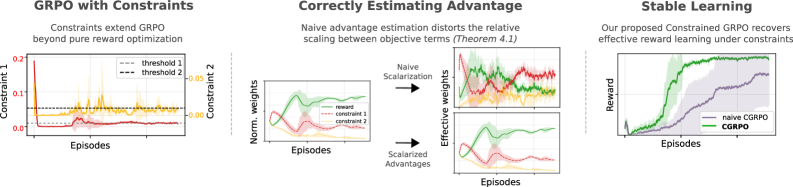
问题定义:论文旨在解决在强化学习中,如何有效地学习满足特定行为约束的策略的问题。现有方法,特别是GRPO,在处理显式行为约束时存在不足,直接应用可能导致约束违反,影响任务性能。一个关键的痛点是,在多目标优化中,不同目标(奖励和约束)之间的权衡难以有效控制,尤其是在优势函数估计中。
核心思路:论文的核心思路是利用拉格朗日方法将约束优化问题转化为无约束优化问题,并通过优化拉格朗日乘子来动态调整约束的权重。为了解决多目标优势函数估计中的问题,论文提出了标量化优势构造方法,确保奖励和约束项之间保持预期的权衡,避免因不同分量的标准差不匹配而导致的优化偏差。
技术框架:Constrained GRPO的整体框架基于GRPO,并引入了拉格朗日乘子来处理约束。主要流程包括: 1. 使用指示代价函数定义约束。 2. 构建拉格朗日函数,将奖励和约束项结合起来。 3. 使用标量化优势估计方法计算优势函数。 4. 使用GRPO更新策略和拉格朗日乘子。
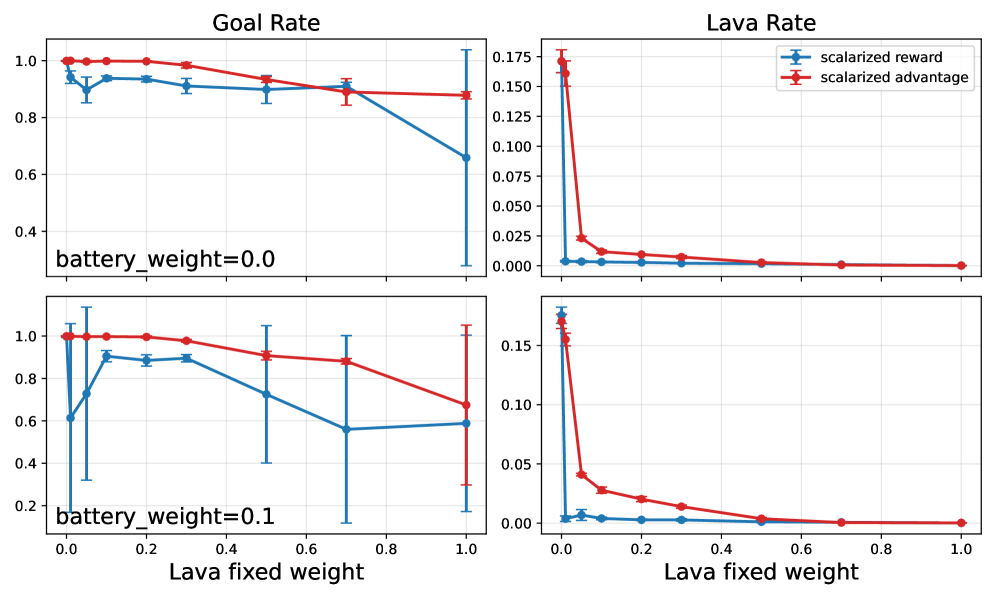
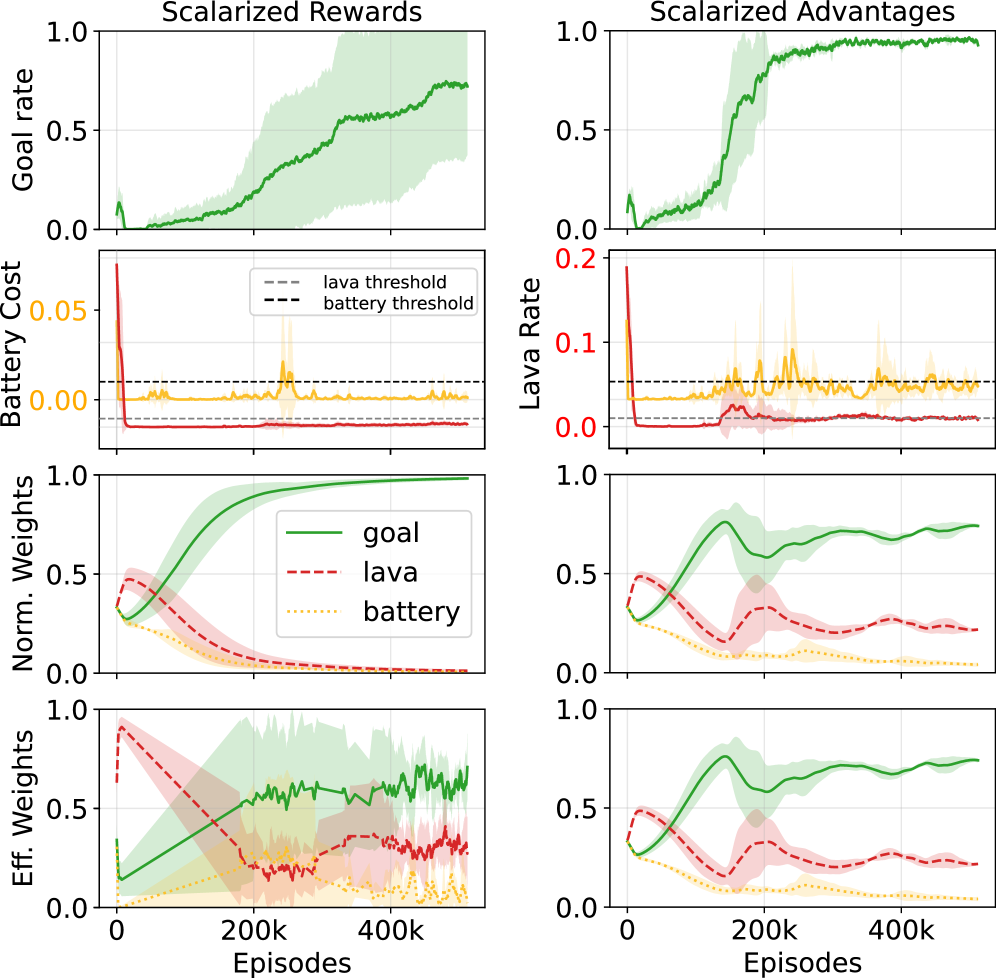
关键创新:论文最重要的技术创新点在于标量化优势构造方法。传统的优势估计方法在处理多目标时,容易受到不同目标分量标准差的影响,导致优化方向偏差。标量化优势构造通过将多个目标合并为一个标量值,确保了奖励和约束之间的正确权衡,从而实现了更稳定的约束学习。
关键设计: 1. 指示代价函数:使用指示函数来量化约束违反程度,方便优化违规率。 2. 拉格朗日函数:将奖励函数和约束违反项通过拉格朗日乘子结合,形成新的目标函数。 3. 标量化优势估计:使用标量化的方式计算优势函数,避免多目标之间的干扰。具体来说,将奖励和约束的优势函数进行加权求和,权重由拉格朗日乘子决定。 4. GRPO更新:使用GRPO算法更新策略和拉格朗日乘子,实现策略优化和约束控制。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在玩具网格世界中,标量化优势构造能够有效避免优化病理,恢复稳定的约束控制。在机器人任务中,Constrained GRPO在提高任务成功率的同时,显著提高了约束满足度。具体而言,与基线方法相比,Constrained GRPO在约束违反率方面取得了显著降低,同时保持或提高了任务完成率。
🎯 应用场景
Constrained GRPO适用于各种需要满足特定行为约束的强化学习任务,例如机器人导航、自动驾驶、资源管理等。在这些场景中,智能体需要在最大化奖励的同时,避免违反安全规则或资源限制。该方法尤其适用于具身智能领域,可以提升机器人任务的安全性、可靠性和效率,并促进大型多模态基础模型在实际机器人应用中的部署。
📄 摘要(原文)
While Group Relative Policy Optimization (GRPO) has emerged as a scalable framework for critic-free policy learning, extending it to settings with explicit behavioral constraints remains underexplored. We introduce Constrained GRPO, a Lagrangian-based extension of GRPO for constrained policy optimization. Constraints are specified via indicator cost functions, enabling direct optimization of violation rates through a Lagrangian relaxation. We show that a naive multi-component treatment in advantage estimation can break constrained learning: mismatched component-wise standard deviations distort the relative importance of the different objective terms, which in turn corrupts the Lagrangian signal and prevents meaningful constraint enforcement. We formally derive this effect to motivate our scalarized advantage construction that preserves the intended trade-off between reward and constraint terms. Experiments in a toy gridworld confirm the predicted optimization pathology and demonstrate that scalarizing advantages restores stable constraint control. In addition, we evaluate Constrained GRPO on robotics tasks, where it improves constraint satisfaction while increasing task success, establishing a simple and effective recipe for constrained policy optimization in embodied AI domains that increasingly rely on large multimodal foundation models.