DLM-Scope: Mechanistic Interpretability of Diffusion Language Models via Sparse Autoencoders
作者: Xu Wang, Bingqing Jiang, Yu Wan, Baosong Yang, Lingpeng Kong, Difan Zou
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-05
备注: 23 pages
💡 一句话要点
DLM-Scope:首个基于稀疏自编码器的扩散语言模型可解释性框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 可解释性 稀疏自编码器 模型干预 特征提取
📋 核心要点
- 自回归LLM的可解释性研究已较为成熟,但新兴的扩散语言模型(DLM)缺乏相应的工具。
- DLM-Scope利用稀疏自编码器(SAE)提取DLM中的可解释特征,并用于模型行为干预和分析。
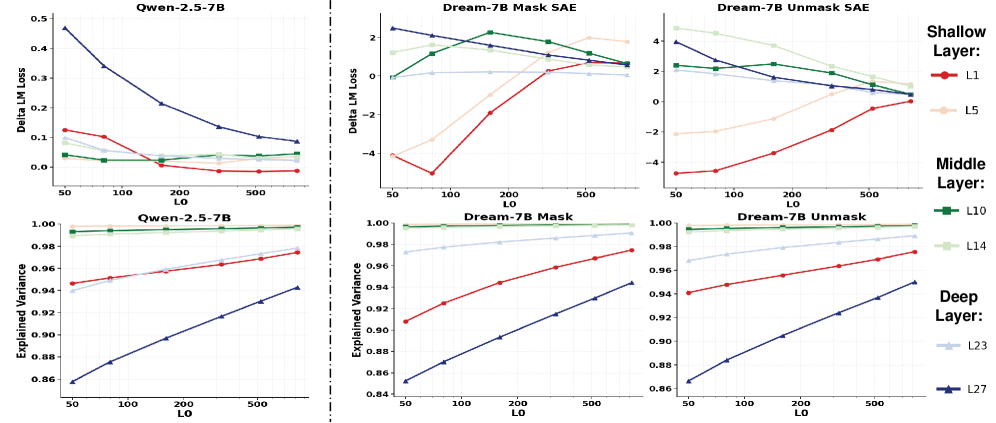
- 实验表明,SAE在DLM早期层插入可降低交叉熵损失,且SAE特征可有效用于扩散时间干预。
📝 摘要(中文)
稀疏自编码器(SAE)已成为自回归大型语言模型(LLM)中进行机制可解释性的标准工具,使研究人员能够提取稀疏的、人类可解释的特征并干预模型行为。最近,扩散语言模型(DLM)已成为自回归LLM的一种越来越有希望的替代方案,因此为这种新兴的模型类别开发量身定制的机制可解释性工具至关重要。在这项工作中,我们提出了DLM-Scope,这是第一个基于SAE的DLM可解释性框架,并证明了训练后的Top-K SAE可以忠实地提取可解释的特征。值得注意的是,我们发现插入SAE对DLM的影响与自回归LLM不同:虽然在LLM中插入SAE通常会产生损失惩罚,但在DLM中,当应用于早期层时,它可以减少交叉熵损失,这种现象在LLM中不存在或明显较弱。此外,DLM中的SAE特征能够实现更有效的扩散时间干预,通常优于LLM引导。此外,我们率先为DLM开创了某些新的基于SAE的研究方向:我们表明SAE可以为DLM解码顺序提供有用的信号;并且SAE特征在DLM的后训练阶段是稳定的。我们的工作为DLM中的机制可解释性奠定了基础,并显示了将SAE应用于DLM相关任务和算法的巨大潜力。
🔬 方法详解
问题定义:现有针对大型语言模型的可解释性方法主要集中在自回归模型上,而对扩散语言模型(DLM)的可解释性研究相对不足。DLM作为一种新兴的生成模型,其内部机制尚不明确,缺乏有效的工具来理解和控制其行为。因此,如何为DLM设计有效的可解释性方法是一个亟待解决的问题。
核心思路:本文的核心思路是借鉴在自回归LLM中广泛应用的稀疏自编码器(SAE),并将其应用于DLM。SAE通过学习稀疏的特征表示,能够提取模型内部的关键激活模式,从而帮助研究人员理解模型的决策过程。通过分析这些稀疏特征,可以实现对DLM行为的干预和控制。
技术框架:DLM-Scope框架主要包含以下几个阶段:1) 选择DLM的特定层作为分析对象;2) 在该层插入SAE,SAE的目标是重构该层的激活向量;3) 训练SAE,使其学习到稀疏的特征表示;4) 分析SAE学习到的特征,例如,通过可视化或与特定概念关联;5) 利用SAE特征进行模型干预,例如,通过修改SAE的激活来改变DLM的输出。
关键创新:该论文的关键创新在于首次将SAE应用于DLM的可解释性研究,并发现了一些与自回归LLM不同的现象。例如,在DLM的早期层插入SAE可以降低交叉熵损失,这在自回归LLM中很少见。此外,该论文还探索了SAE在DLM解码顺序分析和后训练阶段特征稳定性分析中的应用。
关键设计:SAE采用Top-K稀疏化策略,即只保留激活值最高的K个神经元。损失函数包括重构损失和L1正则化项,用于鼓励稀疏性。实验中,作者探索了不同的K值和L1正则化系数,并选择了最优的参数组合。此外,作者还设计了多种基于SAE特征的干预策略,例如,通过修改SAE的激活来控制DLM的输出。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在DLM的早期层插入SAE可以降低交叉熵损失,这与在LLM中观察到的现象相反。此外,基于SAE特征的扩散时间干预效果优于LLM引导。SAE还可以为DLM解码顺序提供有用的信号,并且SAE特征在DLM的后训练阶段是稳定的。
🎯 应用场景
该研究成果可应用于提升扩散语言模型的可控性和安全性。例如,通过理解和干预模型内部的特征表示,可以避免生成有害或不当的内容。此外,该方法还可以用于分析DLM的生成过程,从而改进模型的设计和训练,提高生成质量。未来,该研究有望推动DLM在文本生成、图像生成等领域的广泛应用。
📄 摘要(原文)
Sparse autoencoders (SAEs) have become a standard tool for mechanistic interpretability in autoregressive large language models (LLMs), enabling researchers to extract sparse, human-interpretable features and intervene on model behavior. Recently, as diffusion language models (DLMs) have become an increasingly promising alternative to the autoregressive LLMs, it is essential to develop tailored mechanistic interpretability tools for this emerging class of models. In this work, we present DLM-Scope, the first SAE-based interpretability framework for DLMs, and demonstrate that trained Top-K SAEs can faithfully extract interpretable features. Notably, we find that inserting SAEs affects DLMs differently than autoregressive LLMs: while SAE insertion in LLMs typically incurs a loss penalty, in DLMs it can reduce cross-entropy loss when applied to early layers, a phenomenon absent or markedly weaker in LLMs. Additionally, SAE features in DLMs enable more effective diffusion-time interventions, often outperforming LLM steering. Moreover, we pioneer certain new SAE-based research directions for DLMs: we show that SAEs can provide useful signals for DLM decoding order; and the SAE features are stable during the post-training phase of DLMs. Our work establishes a foundation for mechanistic interpretability in DLMs and shows a great potential of applying SAEs to DLM-related tasks and algorithms.