Where Does Warm-Up Come From? Adaptive Scheduling for Norm-Constrained Optimizers
作者: Artem Riabinin, Andrey Veprikov, Arman Bolatov, Martin Takáč, Aleksandr Beznosikov
分类: cs.LG, math.OC
发布日期: 2026-02-05
备注: 26 pages, 6 figures, 4 tables
🔗 代码/项目: GITHUB
💡 一句话要点
针对Norm约束优化器,提出自适应warm-up调度方法,提升LLM预训练效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自适应学习率 Warm-up调度 Norm约束优化器 大型语言模型 预训练 LLaMA Muon Lion
📋 核心要点
- 现有Norm约束优化器依赖手动调整warm-up策略,缺乏理论支撑且调参成本高昂。
- 论文提出基于广义平滑性假设的自适应学习率调度方法,自动调整warm-up时长。
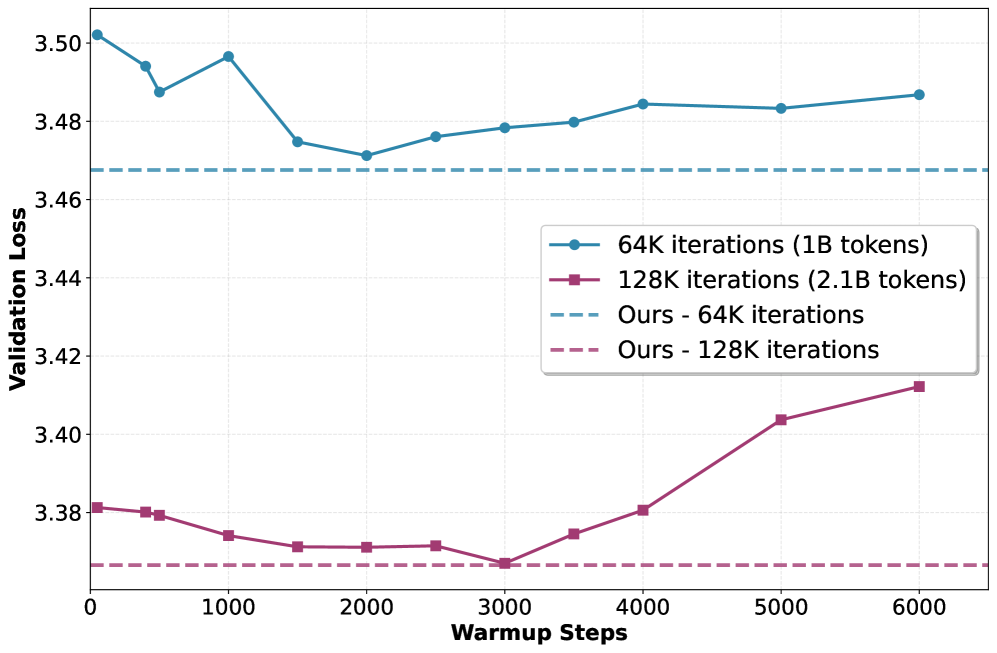
- 实验表明,该方法在LLaMA架构的LLM预训练中,性能优于或匹配手动调整的warm-up策略。
📝 摘要(中文)
本文研究了针对Norm约束优化器(例如Muon和Lion)的自适应学习率调度方法。作者提出了一种广义平滑性假设,即局部曲率随着次优性差距的减小而降低,并通过实验验证了这种行为在优化轨迹中成立。基于此假设,作者在适当的学习率选择下建立了收敛性保证,其中warm-up和随后的衰减自然地从证明中产生,而不是人为地施加。在此理论基础上,作者开发了一种实用的学习率调度器,该调度器仅依赖于标准超参数,并在训练开始时自动调整warm-up持续时间。作者使用LLaMA架构在大型语言模型预训练中评估了该方法,结果表明,作者的自适应warm-up选择始终优于或至少匹配所有考虑设置中手动调整的最佳warm-up调度,而无需额外的超参数搜索。源代码可在https://github.com/brain-lab-research/llm-baselines/tree/warmup 获取。
🔬 方法详解
问题定义:现有的Norm约束优化器,如Muon和Lion,在训练大型语言模型时,通常需要一个warm-up阶段,即在训练初期逐渐增加学习率。然而,warm-up的持续时间通常是手动调整的,缺乏理论依据,并且需要大量的实验才能找到最佳值,这增加了训练的成本和难度。因此,如何自动地、自适应地确定warm-up的持续时间是一个重要的研究问题。
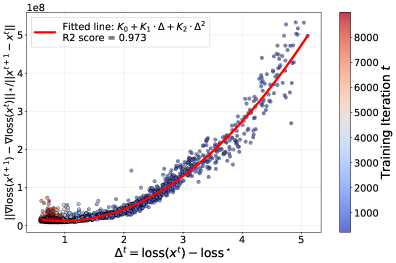
核心思路:论文的核心思路是基于一个广义的平滑性假设,即局部曲率随着次优性差距的减小而降低。这意味着在训练初期,模型可能位于损失函数的陡峭区域,需要较小的学习率来稳定训练;随着训练的进行,模型逐渐接近最优解,损失函数的曲率变得平缓,可以适当增加学习率。基于这个假设,论文推导出了一种自适应的学习率调度策略,该策略可以根据训练的进度自动调整warm-up的持续时间。
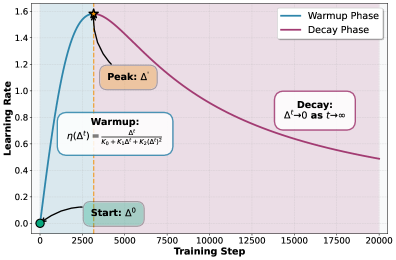
技术框架:该方法主要包含以下几个阶段:1)基于广义平滑性假设,推导出学习率的理论上界;2)根据理论上界,设计一个自适应的学习率调度器,该调度器仅依赖于标准超参数;3)在训练开始时,该调度器自动调整warm-up的持续时间;4)在warm-up阶段结束后,学习率按照预定的策略进行衰减。
关键创新:论文最重要的技术创新点在于提出了一个基于广义平滑性假设的自适应学习率调度方法,该方法可以自动调整warm-up的持续时间,而无需手动调整。与现有方法相比,该方法具有更强的理论依据和更高的效率。
关键设计:论文的关键设计包括:1)广义平滑性假设的具体形式;2)基于该假设推导出的学习率理论上界;3)自适应学习率调度器的具体实现,包括如何根据训练的进度调整warm-up的持续时间;4)学习率衰减策略的选择。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在LLaMA架构的大型语言模型预训练中,该自适应warm-up选择方法始终优于或至少匹配手动调整的最佳warm-up调度,而无需额外的超参数搜索。这意味着该方法可以在各种设置下提供一致的性能提升,并且可以显著降低调参的成本。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的预训练,特别是在使用Norm约束优化器(如Muon和Lion)的场景下。通过自动调整warm-up策略,可以显著降低调参成本,提高训练效率,并可能提升模型的最终性能。该方法还有潜力推广到其他深度学习任务中,例如图像识别和语音识别。
📄 摘要(原文)
We study adaptive learning rate scheduling for norm-constrained optimizers (e.g., Muon and Lion). We introduce a generalized smoothness assumption under which local curvature decreases with the suboptimality gap and empirically verify that this behavior holds along optimization trajectories. Under this assumption, we establish convergence guarantees under an appropriate choice of learning rate, for which warm-up followed by decay arises naturally from the proof rather than being imposed heuristically. Building on this theory, we develop a practical learning rate scheduler that relies only on standard hyperparameters and adapts the warm-up duration automatically at the beginning of training. We evaluate this method on large language model pretraining with LLaMA architectures and show that our adaptive warm-up selection consistently outperforms or at least matches the best manually tuned warm-up schedules across all considered setups, without additional hyperparameter search. Our source code is available at https://github.com/brain-lab-research/llm-baselines/tree/warmup