Distributional Reinforcement Learning with Diffusion Bridge Critics
作者: Shutong Ding, Yimiao Zhou, Ke Hu, Mokai Pan, Shan Zhong, Yanwei Fu, Jingya Wang, Ye Shi
分类: cs.LG
发布日期: 2026-02-05
💡 一句话要点
提出基于扩散桥Critic的分布强化学习方法DBC,提升连续控制任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分布强化学习 扩散模型 扩散桥 价值评估 连续控制
📋 核心要点
- 现有基于扩散模型的强化学习方法主要关注策略优化,忽略了扩散模型在价值评估中的潜力,而准确的价值评估对策略优化至关重要。
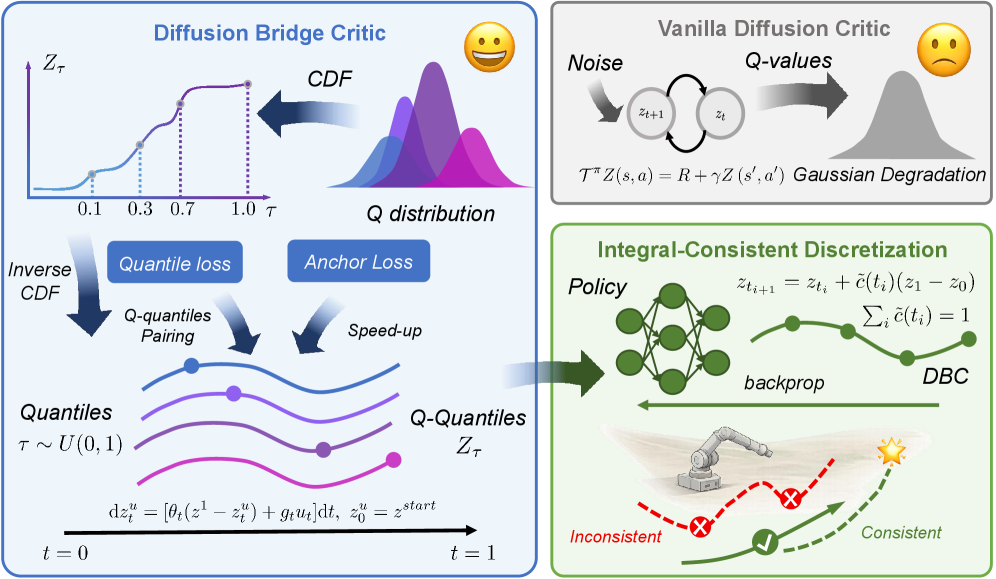
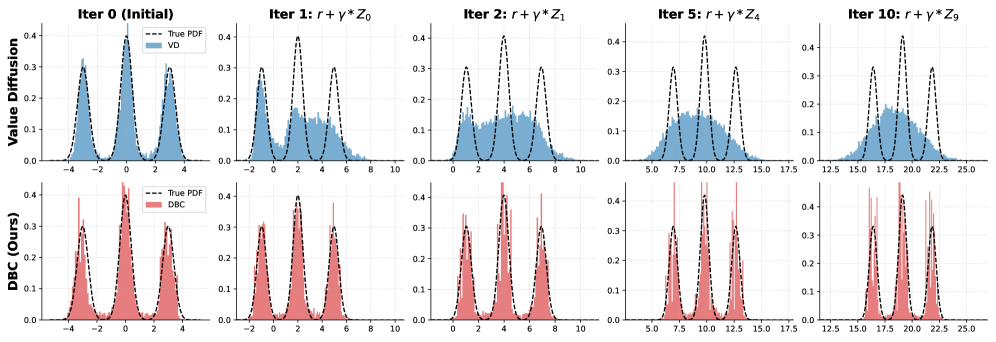
- DBC通过扩散桥模型直接建模Q值的逆累积分布函数,有效捕获价值分布,避免了分布坍塌问题,从而提升价值评估的准确性。
- DBC是一种即插即用的组件,可集成到现有强化学习框架中,并在MuJoCo机器人控制任务上取得了优于现有分布Critic模型的性能。
📝 摘要(中文)
本文提出了一种新的基于扩散桥Critic (DBC) 的分布强化学习方法。现有基于扩散的强化学习方法主要集中于扩散策略的应用,而忽略了扩散Critic的潜力。鉴于策略优化本质上依赖于Critic,准确的价值估计比策略的表达能力更为重要。此外,考虑到强化学习任务的随机性,使用分布模型来描述Critic更为合适。DBC直接对Q值的逆累积分布函数 (CDF) 进行建模,从而能够准确地捕获价值分布,并防止其因扩散桥强大的分布匹配能力而坍缩为平凡的高斯分布。此外,本文还推导出一个解析积分公式来解决DBC中的离散化误差,这在价值估计中至关重要。据我们所知,DBC是第一个采用扩散桥模型作为Critic的工作。值得注意的是,DBC也是一个即插即用的组件,可以集成到大多数现有的强化学习框架中。在MuJoCo机器人控制基准上的实验结果表明,与之前的分布Critic模型相比,DBC具有优越性。
🔬 方法详解
问题定义:现有基于扩散模型的强化学习方法主要集中在策略优化上,忽略了使用扩散模型来提升Critic的价值评估能力。强化学习任务通常具有随机性,传统的点估计Critic难以准确捕捉价值分布,导致策略优化受限。此外,直接使用扩散模型可能导致价值分布坍塌为简单的高斯分布,影响价值评估的准确性。
核心思路:本文的核心思路是利用扩散桥模型来建模Q值的逆累积分布函数(Inverse CDF)。扩散桥具有强大的分布匹配能力,可以有效防止价值分布坍塌,从而更准确地捕捉价值分布。通过直接建模逆CDF,可以方便地计算分位数,从而进行更精确的价值估计。
技术框架:DBC方法包含以下主要模块:1) 扩散桥Critic:使用扩散桥模型学习Q值的逆CDF。2) 策略网络:采用现有的策略网络结构,例如Actor-Critic框架中的Actor网络。3) 训练流程:通过最小化扩散桥Critic的训练损失来学习价值分布,并使用学习到的Critic来指导策略优化。DBC可以作为一个即插即用的模块集成到现有的强化学习框架中。
关键创新:DBC的关键创新在于:1) 首次将扩散桥模型应用于强化学习中的Critic,用于建模Q值的逆CDF。2) 提出了一个解析积分公式,用于解决DBC中的离散化误差,从而提高价值估计的准确性。3) DBC是一种分布式的Critic,能够更准确地捕捉价值分布,从而提升策略优化效果。
关键设计:DBC的关键设计包括:1) 扩散桥模型的选择:可以使用不同的扩散桥模型,例如基于高斯过程的扩散桥。2) 损失函数的设计:损失函数用于训练扩散桥Critic,可以采用KL散度或Wasserstein距离等度量价值分布的差异。3) 解析积分公式:该公式用于解决离散化误差,具体形式取决于所使用的扩散桥模型和价值分布的离散化方式。4) 网络结构:扩散桥Critic的网络结构需要能够有效地建模Q值的逆CDF,可以使用神经网络来实现。
🖼️ 关键图片
📊 实验亮点
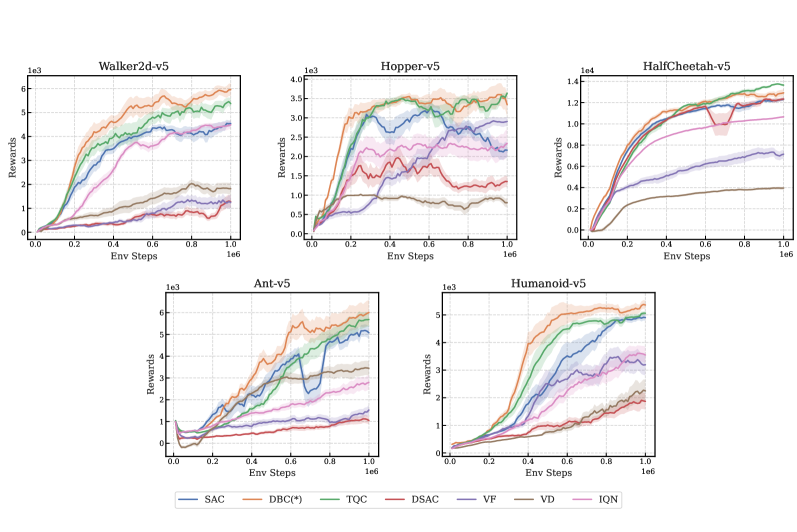
实验结果表明,DBC在MuJoCo机器人控制基准上优于现有的分布Critic模型。例如,在HalfCheetah任务上,DBC的性能显著优于C51和QR-DQN等基线方法。DBC的优势在于能够更准确地捕捉价值分布,从而提升策略优化效果。此外,DBC的即插即用特性使其易于集成到现有的强化学习框架中。
🎯 应用场景
DBC方法可以应用于各种连续控制任务,例如机器人运动控制、自动驾驶、资源调度等。通过更准确的价值评估,DBC可以提升强化学习算法的性能和稳定性,从而在实际应用中实现更好的控制效果。未来,DBC还可以扩展到其他强化学习领域,例如多智能体强化学习、离线强化学习等。
📄 摘要(原文)
Recent advances in diffusion-based reinforcement learning (RL) methods have demonstrated promising results in a wide range of continuous control tasks. However, existing works in this field focus on the application of diffusion policies while leaving the diffusion critics unexplored. In fact, since policy optimization fundamentally relies on the critic, accurate value estimation is far more important than policy expressiveness. Furthermore, given the stochasticity of most reinforcement learning tasks, it has been confirmed that the critic is more appropriately depicted with a distributional model. Motivated by these points, we propose a novel distributional RL method with Diffusion Bridge Critics (DBC). DBC directly models the inverse cumulative distribution function (CDF) of the Q value. This allows us to accurately capture the value distribution and prevents it from collapsing into a trivial Gaussian distribution owing to the strong distribution-matching capability of the diffusion bridge. Moreover, we further derive an analytic integral formula to address discretization errors in DBC, which is essential in value estimation. To our knowledge, DBC is the first work to employ the diffusion bridge model as the critic. Notably, DBC is also a plug-and-play component and can be integrated into most existing RL frameworks. Experimental results on MuJoCo robot control benchmarks demonstrate the superiority of DBC compared with previous distributional critic models.