Learning to Inject: Automated Prompt Injection via Reinforcement Learning
作者: Xin Chen, Jie Zhang, Florian Tramer
分类: cs.LG, cs.AI
发布日期: 2026-02-05
💡 一句话要点
提出AutoInject,利用强化学习自动生成Prompt注入攻击,提升攻击成功率和迁移性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Prompt注入 强化学习 对抗攻击 LLM安全 自动化攻击
📋 核心要点
- 现有Prompt注入攻击方法依赖人工,缺乏可扩展性和适应性,难以应对快速发展的LLM。
- AutoInject利用强化学习自动生成对抗性后缀,在攻击成功的同时兼顾良性任务的性能。
- 实验表明,AutoInject能有效攻击GPT 5 Nano等前沿系统,并在AgentDojo基准上取得显著成果。
📝 摘要(中文)
Prompt注入是LLM Agent中最关键的漏洞之一。然而,从优化角度出发的有效自动化攻击仍未被充分探索。现有方法严重依赖人工红队和手工制作的Prompt,限制了其可扩展性和适应性。我们提出了AutoInject,一个强化学习框架,用于生成通用的、可迁移的对抗性后缀,同时优化攻击成功率和良性任务上的效用保持。我们的黑盒方法支持基于查询的优化和对未见模型的迁移攻击。仅使用一个15亿参数的对抗性后缀生成器,我们成功地攻破了包括GPT 5 Nano、Claude Sonnet 3.5和Gemini 2.5 Flash在内的前沿系统,并在AgentDojo基准上建立了更强的自动化Prompt注入研究基线。
🔬 方法详解
问题定义:论文旨在解决Prompt注入攻击自动化程度低、依赖人工的问题。现有方法需要大量人工设计Prompt,难以适应不同LLM和任务,且泛化能力有限。因此,如何自动生成有效的、可迁移的Prompt注入攻击是本研究的核心问题。
核心思路:论文的核心思路是利用强化学习自动搜索对抗性后缀,该后缀能够诱导LLM执行恶意指令,同时尽量不影响LLM在正常任务上的表现。通过强化学习,模型可以学习到一种通用的攻击策略,从而提高攻击的成功率和迁移性。
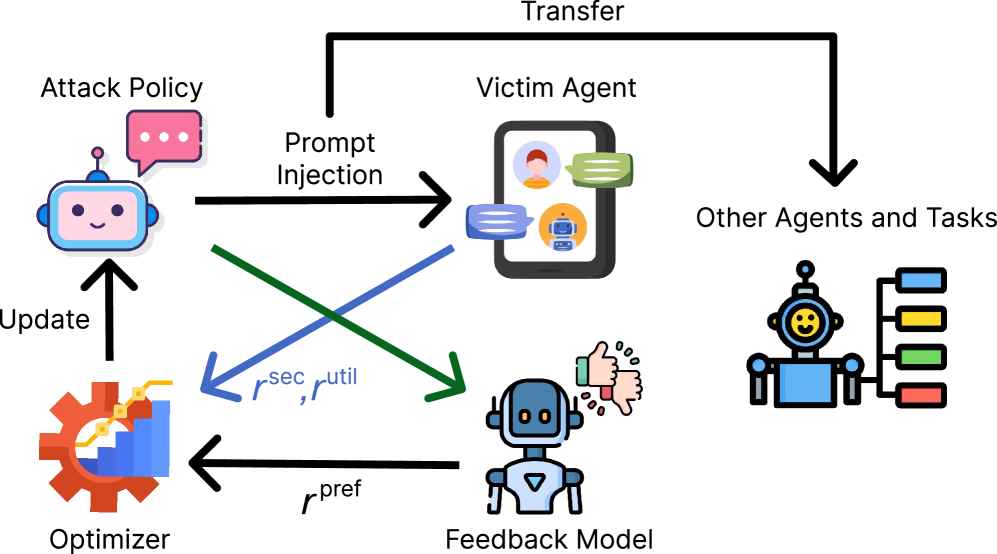
技术框架:AutoInject框架包含一个对抗性后缀生成器(基于Transformer),一个强化学习Agent和一个目标LLM。Agent通过与目标LLM交互,生成对抗性后缀。目标LLM接收包含对抗性后缀的输入,并产生输出。Agent根据输出计算奖励,并更新后缀生成器的参数。整个过程迭代进行,直到生成器能够生成有效的对抗性后缀。
关键创新:AutoInject的关键创新在于使用强化学习自动生成对抗性后缀,而不是依赖人工设计。这种方法可以自动探索攻击空间,发现更有效的攻击策略。此外,AutoInject还优化了攻击成功率和良性任务的效用保持,使得生成的对抗性后缀更加实用。
关键设计:对抗性后缀生成器使用一个1.5B参数的Transformer模型。奖励函数的设计至关重要,它需要平衡攻击成功率和良性任务的效用。论文使用了多种奖励信号,包括攻击成功时的正奖励、攻击失败时的负奖励,以及良性任务性能下降时的负奖励。强化学习算法使用了Proximal Policy Optimization (PPO)。
🖼️ 关键图片

📊 实验亮点
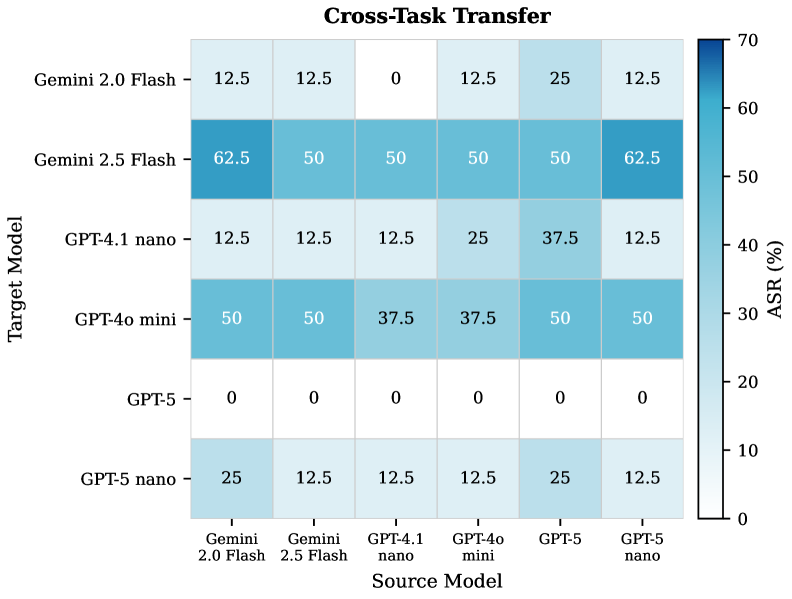
AutoInject成功攻破了GPT 5 Nano、Claude Sonnet 3.5和Gemini 2.5 Flash等前沿系统,并在AgentDojo基准上建立了更强的自动化Prompt注入研究基线。该方法仅使用一个1.5B参数的对抗性后缀生成器,就实现了显著的攻击效果,表明了其高效性和实用性。
🎯 应用场景
AutoInject的研究成果可应用于LLM安全评估、红队测试和防御机制开发。通过自动化Prompt注入攻击,可以更全面地评估LLM的安全性,发现潜在的漏洞。此外,该研究还可以帮助开发更有效的防御机制,提高LLM的鲁棒性,防止恶意利用。
📄 摘要(原文)
Prompt injection is one of the most critical vulnerabilities in LLM agents; yet, effective automated attacks remain largely unexplored from an optimization perspective. Existing methods heavily depend on human red-teamers and hand-crafted prompts, limiting their scalability and adaptability. We propose AutoInject, a reinforcement learning framework that generates universal, transferable adversarial suffixes while jointly optimizing for attack success and utility preservation on benign tasks. Our black-box method supports both query-based optimization and transfer attacks to unseen models and tasks. Using only a 1.5B parameter adversarial suffix generator, we successfully compromise frontier systems including GPT 5 Nano, Claude Sonnet 3.5, and Gemini 2.5 Flash on the AgentDojo benchmark, establishing a stronger baseline for automated prompt injection research.