CSRv2: Unlocking Ultra-Sparse Embeddings
作者: Lixuan Guo, Yifei Wang, Tiansheng Wen, Yifan Wang, Aosong Feng, Bo Chen, Stefanie Jegelka, Chenyu You
分类: cs.LG, cs.AI, cs.IR, cs.IT
发布日期: 2026-02-05
备注: Accepted by ICLR2026
💡 一句话要点
CSRv2:解锁超稀疏嵌入,实现高效且高性能的文本和视觉表示
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏嵌入 对比学习 超稀疏表示 k-退火 文本表示 视觉表示 边缘计算 模型压缩
📋 核心要点
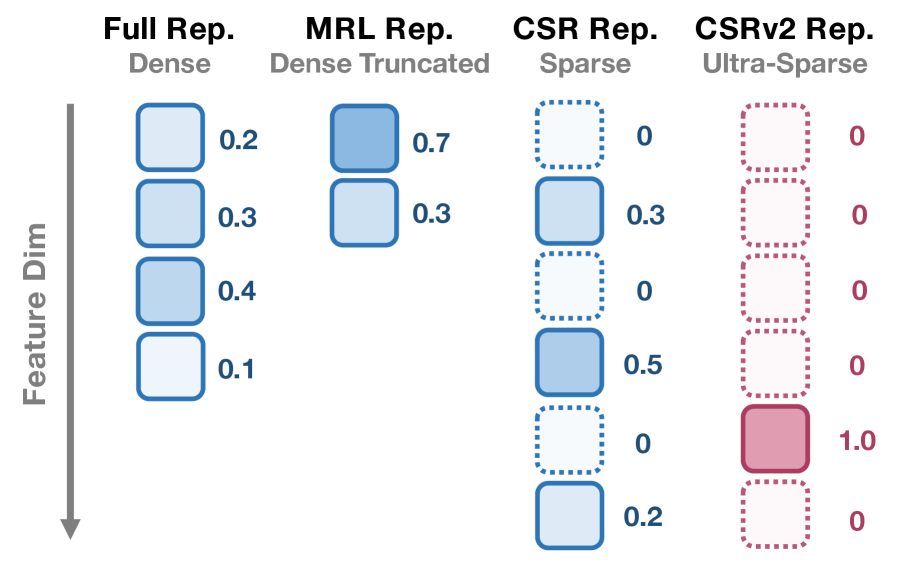
- 现有稠密嵌入维度过高,导致存储、内存和推理成本巨大,而现有稀疏嵌入方法在超稀疏场景下性能显著下降。
- CSRv2通过渐进式k-退火稳定稀疏学习,利用监督对比目标提升表示质量,并进行端到端微调以适应不同任务。
- 实验表明,CSRv2在超稀疏设置下显著提升性能,例如在k=2时准确率提升14%,同时实现了更高的计算和内存效率。
📝 摘要(中文)
在大规模基础模型的时代,嵌入的质量已成为下游任务性能和整体系统能力的关键决定因素。然而,广泛使用的稠密嵌入通常是极高维的,导致存储、内存和推理延迟方面的巨大成本。为了解决这些问题,对比稀疏表示(CSR)最近被提出作为一个有希望的方向,将稠密嵌入映射到高维但k-稀疏的向量,与紧凑的稠密嵌入(如Matryoshka Representation Learning (MRL))形成对比。尽管CSR具有潜力,但在超稀疏状态下会严重退化,超过80%的神经元保持非激活状态,使其效率潜力无法实现。在本文中,我们介绍了CSRv2,这是一种旨在使超稀疏嵌入可行的原则性训练方法。CSRv2通过渐进式k-退火来稳定稀疏性学习,通过监督对比目标来增强表示质量,并通过完全骨干微调来确保端到端适应性。CSRv2将死神经元从80%减少到20%,并在k=2时提供14%的准确率提升,使超稀疏嵌入与k=8时的CSR和32维时的MRL相当,而只有两个激活特征。在保持可比性能的同时,CSRv2比MRL提供7倍的加速,并且在文本表示中相对于稠密嵌入产生高达300倍的计算和内存效率提升。在文本和视觉方面的广泛实验表明,CSRv2使超稀疏嵌入在不影响性能的情况下变得实用,其中CSRv2在k=4时比CSR提高了7%/4%,并且在文本/视觉表示中,当k=2时,进一步将这一差距扩大到14%/6%。通过使极端稀疏性可行,CSRv2拓宽了实时和边缘可部署AI系统的设计空间,在这些系统中,嵌入质量和效率都至关重要。
🔬 方法详解
问题定义:论文旨在解决超稀疏嵌入在实际应用中性能下降的问题。现有的对比稀疏表示(CSR)方法在神经元激活比例极低(例如低于20%)时,表示能力会显著降低,无法充分发挥稀疏嵌入在计算和存储上的优势。
核心思路:论文的核心思路是通过改进训练方法,使模型能够在超稀疏条件下学习到高质量的嵌入表示。具体来说,通过逐步降低激活神经元的数量(k-退火),并结合监督对比学习,来稳定稀疏性学习过程,避免模型陷入局部最优。
技术框架:CSRv2的整体框架包括三个主要组成部分:1) 渐进式k-退火:逐步降低每个样本激活的神经元数量k,从较稠密的状态开始训练,逐渐过渡到超稀疏状态。2) 监督对比学习:利用标签信息,通过对比学习损失函数,鼓励相同类别的样本具有相似的嵌入表示,不同类别的样本具有不同的嵌入表示。3) 端到端微调:在预训练完成后,对整个模型(包括骨干网络和嵌入层)进行微调,以适应特定的下游任务。
关键创新:CSRv2的关键创新在于其渐进式k-退火策略和监督对比学习的结合。渐进式k-退火能够稳定稀疏性学习,避免模型在训练初期就陷入局部最优。监督对比学习则能够提升嵌入表示的质量,使其更好地反映样本之间的语义关系。与现有方法相比,CSRv2能够在超稀疏条件下学习到更高质量的嵌入表示。
关键设计:在渐进式k-退火中,k的值从一个较大的初始值逐渐降低到一个较小的目标值。监督对比学习使用InfoNCE损失函数,该损失函数鼓励相同类别的样本具有相似的嵌入表示,不同类别的样本具有不同的嵌入表示。在端到端微调中,使用交叉熵损失函数或hinge loss等损失函数,根据具体的下游任务进行选择。
🖼️ 关键图片


📊 实验亮点
CSRv2在文本和视觉表示任务上均取得了显著的性能提升。在文本表示方面,当k=4时,CSRv2比CSR提高了7%,当k=2时,提高了14%。在视觉表示方面,当k=4时,CSRv2比CSR提高了4%,当k=2时,提高了6%。此外,CSRv2在保持可比性能的同时,比MRL提供7倍的加速,并且在文本表示中相对于稠密嵌入产生高达300倍的计算和内存效率提升。
🎯 应用场景
CSRv2在资源受限的边缘设备和实时系统中具有广泛的应用前景。例如,在移动设备上进行图像识别或自然语言处理时,可以使用CSRv2生成超稀疏嵌入,从而降低计算和存储成本,提高推理速度。此外,CSRv2还可以应用于大规模推荐系统、信息检索等领域,以提高系统的效率和可扩展性。
📄 摘要(原文)
In the era of large foundation models, the quality of embeddings has become a central determinant of downstream task performance and overall system capability. Yet widely used dense embeddings are often extremely high-dimensional, incurring substantial costs in storage, memory, and inference latency. To address these, Contrastive Sparse Representation (CSR) is recently proposed as a promising direction, mapping dense embeddings into high-dimensional but k-sparse vectors, in contrast to compact dense embeddings such as Matryoshka Representation Learning (MRL). Despite its promise, CSR suffers severe degradation in the ultra-sparse regime, where over 80% of neurons remain inactive, leaving much of its efficiency potential unrealized. In this paper, we introduce CSRv2, a principled training approach designed to make ultra-sparse embeddings viable. CSRv2 stabilizes sparsity learning through progressive k-annealing, enhances representational quality via supervised contrastive objectives, and ensures end-to-end adaptability with full backbone finetuning. CSRv2 reduces dead neurons from 80% to 20% and delivers a 14% accuracy gain at k=2, bringing ultra-sparse embeddings on par with CSR at k=8 and MRL at 32 dimensions, all with only two active features. While maintaining comparable performance, CSRv2 delivers a 7x speedup over MRL, and yields up to 300x improvements in compute and memory efficiency relative to dense embeddings in text representation. Extensive experiments across text and vision demonstrate that CSRv2 makes ultra-sparse embeddings practical without compromising performance, where CSRv2 achieves 7%/4% improvement over CSR when k=4 and further increases this gap to 14%/6% when k=2 in text/vision representation. By making extreme sparsity viable, CSRv2 broadens the design space for real-time and edge-deployable AI systems where both embedding quality and efficiency are critical.