End-to-End Compression for Tabular Foundation Models
作者: Guri Zabërgja, Rafiq Kamel, Arlind Kadra, Christian M. M. Frey, Josif Grabocka
分类: cs.LG
发布日期: 2026-02-05
💡 一句话要点
提出TACO,一种端到端表格数据压缩模型,加速表格Foundation Model推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据 压缩模型 Foundation Model 端到端学习 Transformer 推理加速 上下文学习
📋 核心要点
- 现有表格Foundation Model基于Transformer,计算复杂度高,限制了其在大规模数据集上的应用。
- TACO通过在潜在空间中压缩训练数据,降低了模型对数据集大小的依赖,从而加速推理。
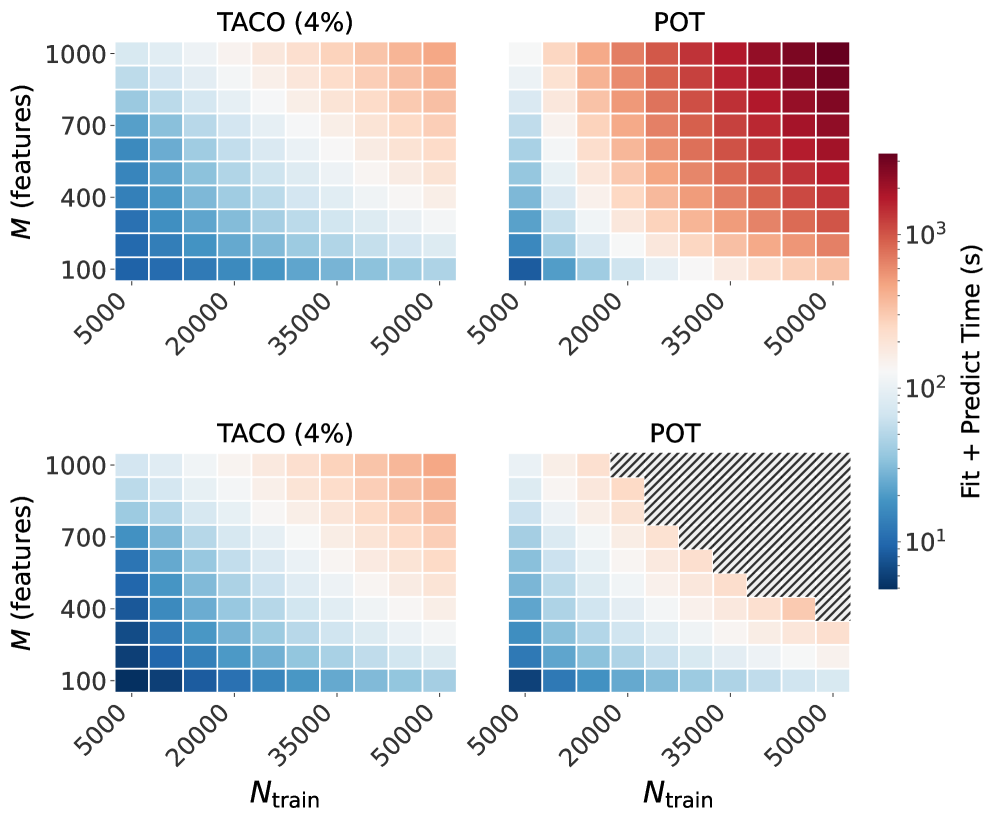
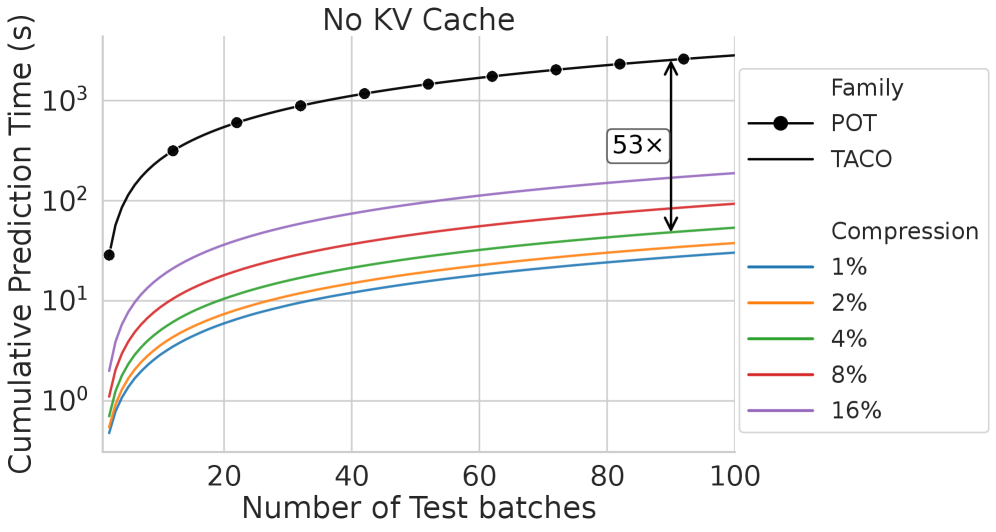
- 实验表明,TACO在TabArena基准测试中,推理速度提升高达94倍,内存占用减少97%,且性能保持甚至优于其他基线。
📝 摘要(中文)
表格数据领域长期以来由梯度提升决策树主导,但最近涌现的上下文学习表格Foundation Model对其发起了挑战。上下文学习方法通过单次前向传播进行拟合和预测,无需参数更新,而是利用训练数据作为上下文来预测查询测试点。虽然最新的表格Foundation Model取得了最先进的性能,但其基于注意力机制的Transformer架构在数据集大小方面具有二次复杂度,这反过来又增加了训练和推理时间的开销,并限制了模型处理大规模数据集的能力。在这项工作中,我们提出了TACO,一种端到端表格压缩模型,可以在潜在空间中压缩训练数据集。我们在TabArena基准上测试了我们的方法,结果表明,与最先进的表格Transformer架构相比,我们提出的方法在推理时间上快了94倍,同时消耗的内存减少了97%,并且在保持性能的同时没有显著的下降。最后,我们的方法不仅可以更好地随着数据集大小的增加而扩展,而且与其它基线相比,它还实现了更好的性能。
🔬 方法详解
问题定义:现有表格Foundation Model,特别是基于Transformer的架构,在处理大规模表格数据时面临计算复杂度高的挑战。注意力机制的二次复杂度使得训练和推理时间随着数据集大小的增加而显著增加,限制了模型的可扩展性和实际应用。
核心思路:TACO的核心思路是通过学习一个潜在空间的压缩表示来减少训练数据集的大小。通过将原始训练数据压缩到一个更小的潜在空间,模型可以在这个压缩空间上进行推理,从而降低计算复杂度,提高推理速度。
技术框架:TACO是一个端到端的压缩模型,包含一个编码器和一个解码器。编码器将原始训练数据映射到潜在空间,解码器则从潜在空间重建原始数据。在推理阶段,模型使用压缩后的潜在表示作为上下文来预测新的查询点。整体流程包括:1)使用编码器将训练数据压缩到潜在空间;2)使用压缩后的数据训练预测模型;3)在推理时,使用编码器压缩查询数据,并使用训练好的预测模型进行预测。
关键创新:TACO的关键创新在于其端到端的压缩学习框架,它能够同时学习数据的压缩表示和预测模型。这种联合优化使得模型能够更好地适应压缩后的数据,从而在保持性能的同时显著降低计算复杂度。与传统的先压缩后训练的方法相比,TACO能够更好地保留原始数据中的关键信息。
关键设计:TACO的具体实现细节包括:1)编码器和解码器的网络结构,可以使用自编码器或变分自编码器等;2)损失函数的设计,通常包括重建损失(衡量压缩和解压缩的保真度)和预测损失(衡量预测模型的性能);3)潜在空间的维度,需要根据数据集的大小和复杂度进行调整;4)训练过程中的正则化策略,以防止过拟合。
🖼️ 关键图片

📊 实验亮点
TACO在TabArena基准测试中表现出色,与最先进的表格Transformer架构相比,推理速度提升高达94倍,同时内存消耗降低了97%,并且在性能上没有显著下降。此外,TACO在处理更大规模数据集时表现出更好的可扩展性,并且在某些情况下,性能甚至优于其他基线方法。
🎯 应用场景
TACO适用于各种需要处理大规模表格数据的应用场景,例如金融风险评估、医疗诊断、客户行为分析等。通过降低计算复杂度和内存占用,TACO使得表格Foundation Model能够部署在资源受限的设备上,并能够处理更大规模的数据集,从而提高决策效率和准确性。未来,TACO可以进一步扩展到处理更复杂的数据类型,例如时序数据和图数据。
📄 摘要(原文)
The long-standing dominance of gradient-boosted decision trees for tabular data has recently been challenged by in-context learning tabular foundation models. In-context learning methods fit and predict in one forward pass without parameter updates by leveraging the training data as context for predicting on query test points. While recent tabular foundation models achieve state-of-the-art performance, their transformer architecture based on the attention mechanism has quadratic complexity regarding dataset size, which in turn increases the overhead on training and inference time, and limits the capacity of the models to handle large-scale datasets. In this work, we propose TACO, an end-to-end tabular compression model that compresses the training dataset in a latent space. We test our method on the TabArena benchmark, where our proposed method is up to 94x faster in inference time, while consuming up to 97\% less memory compared to the state-of-the-art tabular transformer architecture, all while retaining performance without significant degradation. Lastly, our method not only scales better with increased dataset sizes, but it also achieves better performance compared to other baselines.