Rewards as Labels: Revisiting RLVR from a Classification Perspective
作者: Zepeng Zhai, Meilin Chen, Jiaxuan Zhao, Junlang Qian, Lei Shen, Yuan Lu
分类: cs.LG, cs.CL
发布日期: 2026-02-05
备注: 12 pages, 5 figures, 4 tables
💡 一句话要点
提出REAL框架,将可验证奖励视为标签,解决强化学习中梯度误分配和梯度主导问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 可验证奖励 策略优化 分类问题 梯度优化 数学推理 语言模型 奖励函数
📋 核心要点
- 现有基于可验证奖励的强化学习方法存在梯度误分配和梯度主导问题,导致策略更新效率低下。
- REAL框架将可验证奖励视为分类标签,把策略优化问题转化为分类问题,并引入锚定logits增强学习。
- 实验表明,REAL提高了训练稳定性,在数学推理任务上显著优于GRPO、DAPO和GSPO等基线模型。
📝 摘要(中文)
本文提出了一种名为Rewards as Labels (REAL) 的新框架,旨在解决基于可验证奖励的强化学习(RLVR)方法中存在的梯度误分配和梯度主导问题。现有RLVR方法,如GRPO及其变体,在复杂推理任务中表现出色,但存在上述问题,导致策略更新效率低下和次优。REAL将可验证奖励重新定义为分类标签而非标量权重,从而将策略优化转化为分类问题。此外,引入了锚定logits以增强策略学习。分析表明,REAL诱导单调有界的梯度加权,从而实现跨rollout的平衡梯度分配,并有效缓解了上述问题。在数学推理基准测试中,REAL提高了训练稳定性,并始终优于GRPO和DAPO等强基线。在1.5B模型上,REAL的平均Pass@1比DAPO提高了6.7%。在7B模型上,REAL继续优于DAPO和GSPO,分别提高了6.2%和1.7%。即使使用标准的二元交叉熵损失,REAL仍然稳定,并且平均超过DAPO 4.5%。
🔬 方法详解
问题定义:现有基于可验证奖励的强化学习方法,例如GRPO及其变体,在复杂推理任务中表现出色,但存在梯度误分配(Gradient Misassignment in Positives)和梯度主导(Gradient Domination in Negatives)的问题。梯度误分配指的是在正样本中,梯度方向可能与期望方向相反;梯度主导指的是负样本的梯度幅度远大于正样本,导致模型过度关注负样本,从而影响策略学习的效率和效果。
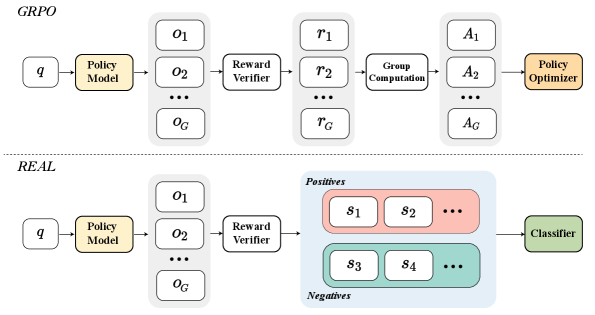
核心思路:REAL的核心思路是将可验证奖励重新定义为分类标签,而不是像传统方法那样将其作为标量权重。通过将策略优化问题转化为分类问题,可以利用分类任务中成熟的损失函数和优化方法,从而更有效地学习策略。此外,引入锚定logits,通过提供额外的监督信息,进一步增强策略学习。
技术框架:REAL框架主要包含以下几个步骤:1) 使用语言模型生成多个候选答案;2) 使用可验证奖励函数对每个候选答案进行评估,得到相应的奖励值;3) 将奖励值转化为分类标签,例如,奖励值为1表示正样本,奖励值为0表示负样本;4) 使用分类损失函数(例如,交叉熵损失)训练策略模型,使其能够预测给定输入对应的标签;5) 使用训练好的策略模型生成新的候选答案,并重复上述步骤,直到模型收敛。
关键创新:REAL最重要的技术创新点在于将可验证奖励视为分类标签,从而将策略优化问题转化为分类问题。这种转变使得可以利用分类任务中成熟的损失函数和优化方法,从而更有效地学习策略。与现有方法相比,REAL能够更好地平衡正负样本的梯度,从而缓解梯度误分配和梯度主导的问题。
关键设计:REAL的关键设计包括:1) 使用二元交叉熵损失函数作为分类损失函数;2) 引入锚定logits,通过提供额外的监督信息,增强策略学习。锚定logits的具体实现方式未知,需要在论文中进一步查找。此外,具体的网络结构和参数设置也需要参考原始论文。
🖼️ 关键图片


📊 实验亮点
REAL在数学推理基准测试中表现出色,在1.5B模型上,REAL的平均Pass@1比DAPO提高了6.7%。在7B模型上,REAL继续优于DAPO和GSPO,分别提高了6.2%和1.7%。即使使用标准的二元交叉熵损失,REAL仍然稳定,并且平均超过DAPO 4.5%。这些结果表明,REAL能够有效地提高模型的推理能力和训练稳定性。
🎯 应用场景
REAL框架具有广泛的应用前景,可以应用于各种需要复杂推理和决策的任务中,例如数学问题求解、代码生成、游戏AI等。通过利用可验证奖励作为监督信号,REAL可以有效地提高模型的推理能力和决策水平,从而在实际应用中发挥重要作用。此外,该方法还可以应用于其他类型的强化学习问题,例如机器人控制和自动驾驶。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards has recently advanced the capabilities of Large Language Models in complex reasoning tasks by providing explicit rule-based supervision. Among RLVR methods, GRPO and its variants have achieved strong empirical performance. Despite their success, we identify that they suffer from Gradient Misassignment in Positives and Gradient Domination in Negatives, which lead to inefficient and suboptimal policy updates. To address these issues, we propose Rewards as Labels (REAL), a novel framework that revisits verifiable rewards as categorical labels rather than scalar weights, thereby reformulating policy optimization as a classification problem. Building on this, we further introduce anchor logits to enhance policy learning. Our analysis reveals that REAL induces a monotonic and bounded gradient weighting, enabling balanced gradient allocation across rollouts and effectively mitigating the identified mismatches. Extensive experiments on mathematical reasoning benchmarks show that REAL improves training stability and consistently outperforms GRPO and strong variants such as DAPO. On the 1.5B model, REAL improves average Pass@1 over DAPO by 6.7%. These gains further scale to 7B model, REAL continues to outperform DAPO and GSPO by 6.2% and 1.7%, respectively. Notably, even with a vanilla binary cross-entropy, REAL remains stable and exceeds DAPO by 4.5% on average.